多模态图像匹配:方法与应用综述
多模态图像匹配:方法与应用综述

A review of multimodal image matching: Methods and applications - ScienceDirect
A review of multimodal image matching: Methods and applications (sciencedirectassets.com)
摘要:
多模态图像匹配是指从具有显著模态或非线性外观差异的两幅或多幅图像中识别并对应相同或相似的结构/内容,是医学、遥感和计算机视觉等广泛应用中的一个基本和关键问题。在过去的几十年里,特别是在这个深度学习时代,由于在消除多模态图像匹配中固有的模态方差和几何变形方面的挑战,越来越多的方法被提出。然而,对传统的和最新的可训练方法及其在不同研究领域的应用缺乏全面的回顾和分析。为此,在本次调查中,我们首先介绍了两个通用框架,即基于区域和基于特征的框架,它们的核心组件、分类和过程细节。其次,我们根据每个研究领域的成像性质,从手工到深度的多模态图像匹配方法进行了全面的综述,包括医学、遥感和计算机视觉。在包含我们收集和注释的常见类型的多模态图像对的各种数据集上,对兴趣点检测、描述和匹配以及图像配准进行了广泛的实验比较。最后,我们简要介绍和分析了几种典型的应用,揭示了多模态图像匹配的意义,并对这些多模态图像匹配方法进行了深入的讨论和结论。并同时为相关研究领域的研究人员和工程师提供未来发展趋势,实现进一步突破。
关键词:多模态匹配、配准、深度学习、医学、遥感、计算机视觉
1 引言
一般的图像匹配,在相关调查中被定义为[1,2],目的是从两个或多个图像中识别并对应相同或相似的结构/内容。一个更实际的目的是几何扭曲一个移动的(感测或目标)图像到一个固定的(参考或源)图像的共同空间坐标系,并对齐他们的共同区域的像素,即图像配准或对齐。多模态图像匹配(Multimodal image matching, MMIM)有时也被称为多模态图像配准(Multimodal image registration, MMIR),可以看作是图像匹配领域的一种特殊情况。更普遍的定义是待匹配目标具有显著的非线性外观差异,这种差异通常是由不同(不限于)成像传感器、不同成像条件(如昼夜[3-5]、跨天气[6]、跨季节[7])和输入数据类型(如图像-油漆-草图[8,9])引起的。以及图像-文本[10-12])。
在许多研究领域和高水平任务中,MMIM作为一种前置程序要求已经发挥了重要作用。其最直接的目的是从不同的模态中识别和收集广泛的物理属性,从而通过图像配准和融合产生更丰富的场景表示[13,14]。另一个目标是识别输入图像之间的差异或联系,用于变化检测[15]、目标识别/跟踪[16-18]和跨模态人再识别[19-22]。此外,从另一模态捕获的图像将作为补充信息提供者,以实现3D重建[23]和图像定位(如同时定位和映射,以及位置识别)的先进性能[7,24,25]。在放射规划等医学领域,多模态数据(例如,计算机断层扫描(CT)和磁共振成像(MRI)扫描)通常用于更准确的肿瘤轮廓,从而降低放射治疗期间损伤健康组织的风险[26,27]。
在过去的几十年里,由于在这些实际应用中对MMIM或MMIR的高性能要求,越来越多的人提出了先进的技术。正如许多研究人员所建议的那样,现有方法更容易接受的分类方法是基于区域和特征的管道[1,2]。基于区域的框架通常在相似度指标的指导下对图像对进行配准,该相似度指标可以衡量图像对齐的精度,从而驱动配准过程的优化。相比之下,基于特征的框架在一般图像匹配任务和相关应用中更具可操作性。这类方法通常从特征提取开始,然后对特征进行匹配,然后进行变换模型估计,再对图像进行重采样和变形,从而实现图像配准。基于特征的管道由于其灵活性、健壮性和在各种应用程序中的能力而得到了更广泛的应用[10]。近年来,深度学习在各种复杂任务上取得了巨大进展。许多研究人员和工程师也用数据驱动的策略成功地解决了图像匹配问题。基于学习的方法实际上可以看作是对传统框架在信息提取与表示、相似度度量、转换参数回归等方面的直接替代。尽管MMIM已经有了许多系统的、有前景的方法,但由于以下挑战,开发一种在精度、鲁棒性和效率方面都有前景的通用管道仍然是一个悬而未决的问题:
- 第一个限制是不同模态的图像数据不足或不可用。没有完整和全面的数据库包含所有类型的多模态图像对及其基础事实。据我们所知,医学领域的研究人员已经提供了足够多的不同成像设备和/或目标,但在遥感和计算机视觉领域还没有。
- 基于区域的方法高度依赖于相似度度量、几何变换模型和优化方法的适当选择。然而,这些组件也很大程度上受到重叠区域和图像内容[2]的影响。在多模态情况下,由于两幅不同模态的图像之间存在严重的非线性强度差异,这种情况会更加严重。此外,这些方法在高分辨率图像对的情况下非常耗时,甚至在图像对发生大变形时失败。
- 由于多模态图像对的非线性强度差,特征管道的核心挑战是多模态图像对的特征检测和描述。在这种情况下,许多广泛应用于一般视觉应用的特征匹配器将无法运行。该框架中的其他限制与一般图像匹配任务一致,例如对应的两个特征集的组合性质,这将产生沉重的计算负担,或者由于仅使用局部图像信息而不可避免地出现在假定匹配中的严重异常值(不匹配)。
- 深度学习框架在MMIM问题上显示出了巨大的潜力,但它仍然面临着[2,28]中介绍的几个挑战。一方面,从图像中学习直接进行图像配准会受到大几何形变和高分辨率图像的限制。另一方面,由于点数据的无序性和分散性,使用卷积策略从稀疏点数据中学习仍然是一个具有挑战性的问题。此外,该方法还受到实际训练数据不足的限制,无法获得令人满意的匹配/配准模型。
- 由于成像设备和成像性质的不同,每对成像模态都有各自不同的难点。这使得很难提出一个通用的范例来同时解决来自医学、遥感和计算机视觉研究领域的这些常见类型的图像配准问题。
很少有著作专门回顾同时包含医学、遥感和计算机视觉研究的MMIM方法和应用。现有的调查主要集中在一般的图像匹配或配准任务上,仅将多模态情况作为一个小节进行了简要介绍[1,2,28 - 30]。大多数工作都集中在医学图像配准上,以提供特定的指导,或针对3D - 2D配准[31,32],可变形配准[29],或针对不同对象的配准,如乳房[33,34],脑[35],血管[36]。其他人通常审查实现[37,38]或深度学习框架[28,30]。[39,40]中简要介绍了两篇与遥感图像匹配相关的调查论文。在这方面,我们提供了最新的和全面的回顾现有的MMIM方法和应用在医学,遥感和计算机视觉研究领域,特别是最近推出的基于学习的方法。
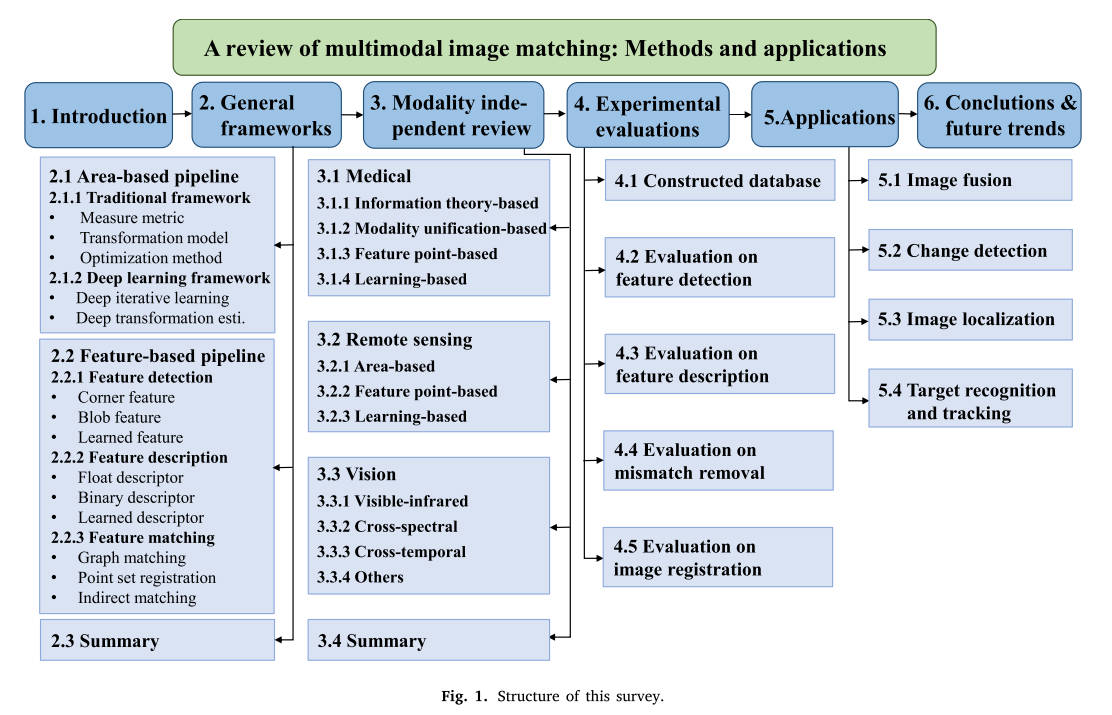
本次调查的总体结构如图1所示。在第2节中,我们介绍了图像匹配中常用的两个通用框架——基于区域的框架和基于特征的框架,以提供组件和流程图的概述。我们还回顾了这些常用的想法,从手工制作到深度学习技术,并分析了它们如何扩展到多模态案例。在第3节中,我们详细回顾了不同研究领域的多模态图像匹配方法,包括医学、遥感和计算机视觉。在第4节和第5节中,我们分别对实验评价和相关应用进行了综合分析。在第6节中,我们总结并讨论了可能的未来发展。
2 图像匹配的一般框架
如前所述,MMIM可以看作是一般图像匹配社区中的一个具体案例。除了外观上的差异外,MMIM将面临与一般图像匹配任务类似的挑战,即几何变形复杂、图像质量差、计算和存储负担高。因此,我们将首先按照[1,2]中的分类法,即基于区域和基于特征的管道,全面介绍一般匹配框架。在每个类别中,我们将着重回顾经典和最近发表的方法的核心思想,特别是那些使用学习技术的方法,然后将这些思想扩展到多模态案例并提供它们之间的联系。
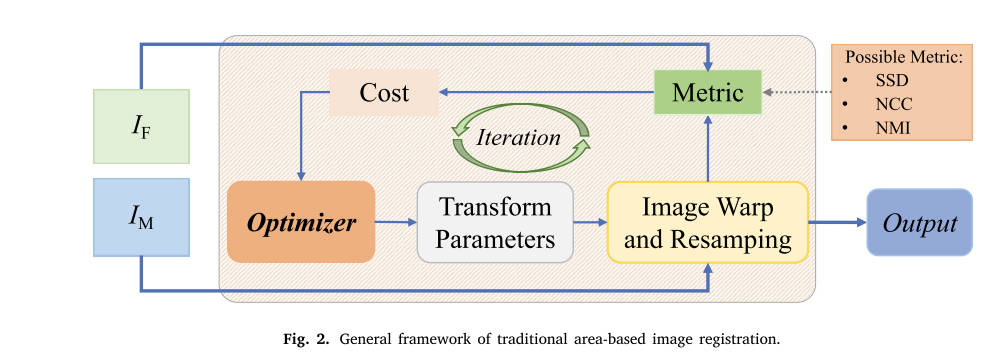
2.1 基于区域的流程
基于区域的管道是利用整幅图像的强度信息来实现图像配准。通常,给定预定义的变换模型,需要一个相似度度量和一种优化方法来估计变换参数,然后通过优化总体代价函数来对齐两幅图像的公共区域。这个代价函数通常是通过测量固定图像和扭曲的运动图像之间的相似性来创建的,从而可以测量图像对齐的准确性。该框架的总体目标可表述为以下形式:
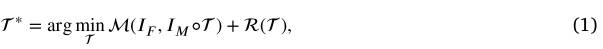
其中表示从运动图像到固定图像的转换模型,表示两者之间的对齐程度。将转换规范化,其目标是支持用户需要的解决方案中的任何特定属性,并寻求解决与问题的病态性相关的困难。整个框架如图2所示。接下来,我们将介绍手工制作和数据驱动策略的匹配方法,并分析传统方法如何在理论和实践中发展成为可训练的方法。
2.1.1 手工设定的框架
从以上细节可以看出,基于区域的图像配准方法由三个部分组成:(1)衡量指标,(2)变换模型,(3)优化方法。接下来,我们将根据这三个关键组件介绍这个通用框架。
(1)测量指标
作为基于区域的图像配准流程中的关键组成部分,用于测量图像配准准确性的指标或匹配标准是指导整个优化过程的热门话题。根据关于两个图像之间强度关系的假设可以设计不同的度量[29]。常用的手动度量可以简单地分为类相关方法和基于信息论的方法。
单模态图像配准中的直接测量是计算相应像素的距离,例如平方和或绝对差,即SSD和SAD。,该计算是在相同解剖结构具有相似强度值的假设下进行的。另一个想法受到信号相关性的启发,它假设两个信号序列之间本质上存在线性相关性,其中最具代表性的标准是互相关性[41-43]和归一化相关系数(NCC)[44, 45]。
基于信息论的方法中最具代表性的度量是互信息(MI)[46,47],它通常基于图像域的统计比较。MI 由于两幅图像之间的统计依赖性而特别适合多模态病例的配准。该指标还引起了人们对设计基于信息的高级指标的极大兴趣,包括 MI 的标准化版本 (NMI) [48]、最大 MI 的上限 [49]、条件 MI (cMI) [50]、区域 MI ,(RMI)[51],或一些基于分歧的方法[52-54]。然而,MI 在确定整个搜索空间的全局最大值时遇到困难,不可避免地降低了其鲁棒性[29]。
然而,这些指标与图像配准的准确性并不绝对线性,这在很大程度上受到重叠区域的大小和图像内容的影响。当图像对经历严重的图像变形或包含没有任何突出细节的平滑区域时,也存在一些限制。
(2)变换模型
图像匹配社区的另一个关键组成部分是变换模型(也称为映射函数)的选择。一般来说,变换模型通常解释目标图像对之间的几何关系,需要准确估计其参数以指导图像变形和重采样(连同适当的插值方法)以实现最终配准。除了基于区域的图像匹配之外,基于特征的匹配管道也需要良好的变换模型,例如实现点集配准或鲁棒地估计特征匹配后的全局变换。尽管变换模型在前几十年已经得到充分研究并形成了一系列标准,但它们仍然值得重新审视,因为选择合适的变换模型不仅可以保持匹配精度,而且可以实现快速优化,特别是对于基于学习的方法。根据两幅图像之间的几何场景的类型,现有的变换模型可以简单地分为线性模型(例如,刚性、仿射和射影)和非线性变形(例如,插值模型、弹性模型和扩散模型)。
线性模型。刚性变换可以看作是最简单的静态模型,它考虑了 3 个自由度 (DOF)(或 3D 情况下的 6 个自由度)的旋转和平移。这种基本模型是文献中的常见选择,用于匹配刚体(例如骨骼)或使用相似变换来容忍尺度变化。更通用的模型(在 2D 情况下使用 6-DOF),即仿射变换,可以保留线的平行度,但不能保留线的长度或角度,因此还允许剪切变形并将平行四边形映射到正方形上。另外两个参数化模型源自多视图几何和摄影成像,使用更多参数来捕获相机运动,即基本矩阵(对极几何)和单应性矩阵(射影变换)。基本矩阵通常将第一幅图像中的点约束为第二幅图像中的一条线,而投影变换可以将梯形映射到正方形上。这两个参数模型可以满足自然图像匹配的大部分要求。
非线性变形。在动态场景中迫切需要能够解释弹性体甚至局部变形的变换模型。为此,在过去几十年中研究了许多非线性模型,也称为非刚性或变形模型,并广泛应用于图像匹配社区(图像或点集配准、特征匹配)。根据基本思想,非线性变形可以分为物理模型和插值模型[29]。
物理模型通常源自物理现象并用偏微分方程表示。弹性体模型通常将图像网格视为弹性膜,该弹性膜在两个相互竞争的力的影响下变形直至达到平衡。外力试图使图像变形以实现匹配,而内力则增强材料的弹性特性。提出了一种非线性形式的弹性模型,利用超弹性材料特性来处理大变形。除了弹性体之外,用于恢复大变形的另一种物理模型是基于粘性流体的,其中使用平滑项来约束相邻点类似地变形。此外,基于麦克斯韦妖,非刚性变形可以建模为扩散过程。该过程通常在估计每个恶魔的恶魔力量和更新由计算的力量引导的变换之间迭代[55]。正则化通常可以通过高斯核卷积有效地实现。其他物理模型包括曲率配准和微分同胚流。在曲率方法的正则化方案中,设计了多个边界条件以实现有效优化,例如使用二阶项[56]或曲率罚分的近似形式[57]。在微分同胚方法中,根据拉格朗日输运方程以及约束速度场平滑的正则化项,通过考虑其随时间变化的速度来对变形进行建模[58,59]。由于速度场的逐渐变化行为,微分同胚框架可以处理大变形配准问题,因此也被称为大变形微分同胚度量映射[60,61]。
与物理模型相比,源自插值或近似理论的几何变换由于其低自由度、计算效率和普遍适用性而在非刚性匹配中受到了相当多的关注。在这一系列变换中,位移基于匹配的控制点或地标进行插值,从而通常通过使用不同的样条函数或插值函数传播到图像域的其余部分。最具代表性的函数被称为径向基函数(RBF)[62],其中插值位置的值被估计为其与已知匹配地标的距离。薄板样条 (TPS) [63, 64] 首先使用 RBF 进行图像配准,至今仍广泛应用于从稀疏到密集的多种应用中。此外,距离函数通常被不同地定义以处理不同的场景,其中高斯距离函数使用核参数来控制全局样本以影响局部变形。另一种常用的模型是自由形式变形(FFD)[65],它基于将图像网格化为几个矩形单元,这些矩形单元在控制点的影响下发生变形,并且密集变形通常使用三次 B 样条进行[ ,66-69]。其他基于插值的模型包括弹性体样条[70]、信号表示的基函数[71,72]和局部仿射模型[73,74]。读者可以参考[29,75,76]了解更多细节和评估。
(3)优化方法
一旦给定了测量度量和转换模型,并获得了目标或能量函数,如式(1)所示。它还需要一种优化方法来从解空间中搜索最佳变换,以最佳地对齐两个图像。显然,优化方法的选择可能很大程度上影响匹配的精度和效率。根据优化方法试图推断的变量的性质,它们的简要类别是连续方法和离散方法。连续优化假设变量为实值,要求目标函数可微。这种类型的代表性方法是梯度下降法、共轭梯度法和拟牛顿法。离散方法通过将其解空间假设为离散集来解决问题。代表性的方法是基于图的[77]、消息传递[78]和线性编程方法[79,80]。概率图模型(例如,马尔可夫随机场)通常用于制定匹配任务并通过这些离散优化方法来解决。一些启发式和元启发式方法,例如贪婪算法[81,82]和进化算法[83,84],也被研究以探索更大的解空间,从而能够处理更一般的问题,但它们不能保证其最优解。
总之,优化方法的选择应考虑目标函数的性质及其可优化的结构。传统的优化方法得到了充分的研究;,我们建议读者参考[29]了解更多细节。近年来,越来越多的研究利用 CNN 捕获的深层特征来指导优化的进行。更鼓舞人心的是,这些优化方法可以被深度回归器取代,以利用数据驱动策略直接估计变换参数或位移场。
2.1.2 基于深度学习的框架
传统的基于区域的图像匹配通常在迭代框架中执行,该框架由相似性测量、转换模型和优化方法的适当设计组成。这种传统的管道因其低计算效率和手工制作的测量指标而受到限制。深度学习技术的出现缓解了这种困境,并且在图像匹配任务中得到了广泛的研究,特别是在医学界。总的来说,现有文献已成功地将深度学习技术嵌入到传统流程中,以驱动迭代优化过程或以端到端的方式直接估计几何变换参数或变形场。
(1)深度迭代方法
最直观的方法是使用深度学习网络来估计目标图像对的相似性测量,以驱动迭代优化过程。这样,经典的测量指标,例如相关性方法和 MI 方法,就可以用更高级的深度指标来替代。
许多研究人员尝试使用堆叠式自动编码器 [85-87] 或一些简单的 CNN 结构 [88,89] 来训练高级测量指标。深度相似性度量和手工度量的结合也被用作图像配准的增强测量[90]。这些深度相似性指标在 MMIR 中显示出了有希望的优势,特别是对于一些手工指标收效甚微的具有挑战性的情况。深度度量学习应该与传统的优化方法和预定义的变换模型相结合来实现图像配准,因此需要较长的执行时间和足够的对齐图像(或图像块)对来进行监督训练。
另一种深度迭代方法是使用强化学习(RL)范式迭代估计变换参数[91]。给定环境及其当前状态,强化学习通常训练人工智能体通过最大化累积预期奖励来预测最佳行动,从而驱动迭代过程,而不是依赖传统的优化方法。在图像配准社区中,经过训练的智能体可以是单个[91-93]或多个[94],并且可以处理刚性[91,92,94]和非刚性[93]图像配准问题。然而,由于其迭代性质,这些方法仍然受到时间要求的影响,并且在解决高分辨率非刚性图像配准问题时,它们应该克服从大解决方案空间进行优化的限制。
(2)深度变换估计
考虑到这些迭代方法的配准速度慢,特别是对于可变形情况下的高维参数空间,越来越多的研究集中在一步直接估计几何变换参数或变形场。根据训练策略,这些深度变换估计方法可以大致分为有监督方法和无监督方法。
监督方法。完全监督的方法通常需要真实数据来定义其损失函数。最大的挑战是在已知 ground truth 变换参数的情况下获得足够的样本进行监督训练。为此,除了使用真实场景的现有标记数据集[95,96]之外,还提出了许多数据生成策略来丰富训练样本的多样性,这些策略通常是通过随机或手动选择的变换来变换对齐数据来合成的[94] ,97] 或习得的合理变形 [98]。由于定义其基本事实的难度增加,这种数据合成策略对于变形配准更具挑战性。此外,通常使用域适应模块[99]或统计外观模型[100]来确保这些合成数据能够更好地模拟真实的变换。
一旦获得了足够的训练样本及其真实的变换参数,另一个关键部分就是定义损失函数。在监督学习过程中,可以根据预测和真实变换参数之间的偏差直观地定义损失,可以通过手工设计的匹配标准或指标直接测量损失。此外,一些简单的 CNN 结构足以输出少量参数来表示静态变换。在可变形的情况下,通常需要全卷积(FC)层来表示高维参数空间并输出可变形场或位移向量场[101],例如FlowNet [100]、DVFNet [102]和U-Net [ ,103,104]。完全监督的方法高度依赖训练数据的大小和多样性,这刺激了更复杂的 ground truth 生成的发展[105]。
另一种训练策略是结合使用真实数据和相似性测量作为监督。该策略涉及使用预测和真实变换之间的相似性以及扭曲图像和固定图像之间的相似性来训练其网络[105]。在某种程度上,额外的监督信息可以实现优越的注册性能。弱监督策略使用分段标签相似性来构造损失函数,也被应用于学习估计变换[103,106]。遵循这些想法,除了上述网络之外,生成对抗网络(GAN)[107]也广泛用于这个匹配管道[108, 109]。生成器经过训练来估计变换,而鉴别器则识别对齐的图像对是否基于 ground truth 变换或预测变换。
总之,这些监督变换估计器的主要目标是使用不同的正则化项来迫使预测的变换现实或接近真实情况。此类方法由于其一步性质,利用深厚的技术大大加快了注册过程。这个目标在 GAN 框架中更容易实现,但这种方法仍然受到需要大量带注释的真实数据的限制,而这些数据通常依赖于从业者的专业知识 [100]。
无监督方法。为了减轻带注释的 ground truth 的局限性,并受到空间变换网络(STN)[110]成功使用的启发,提出了许多无监督方法来以端到端的方式预测几何变换。此类方法仅使用传统的相似性测量(例如NCC、SSD、MSE、NMI)以及限制变换模型的复杂性或平滑度的正则化项来构建损失函数[111-113]。网络结构与监督方法中使用的结构类似,以无监督的形式应用,不使用任何手动注释的数据。因此,为了提高配准性能,许多研究人员尝试在网络中潜在地学习相似性度量,例如学习图像相似性度量和目标配准误差(TRE)之间的关系,应用基于对称微分同胚变换的学习[114],以及,使用 GAN 框架隐式学习测量图像对齐的准确性 [112,115]。其他方法还从原始图像中学习特征表示,然后使用它们来训练深度变换估计器[116]。
还做出了一些努力来处理多模态图像对。典型的策略是使用图像强度和梯度信息输入 CNN [113],图像二值化,然后计算扭曲的运动图像和固定图像之间的 Dice 分数 [117],以及使用为风格迁移提出的循环约束,以及精心设计的指标[112]。
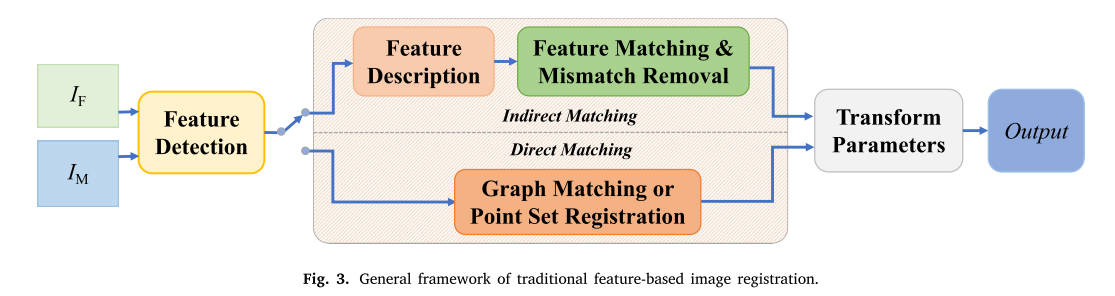
2.2 基于特征的流程
基于特征的管道通常遵循特征检测、特征描述和特征匹配的过程[1]。该管道在图像匹配社区中得到更广泛的使用,因为稀疏特征可以被视为图像的简单表示,因此对几何变形和噪声更加灵活和鲁棒[2]。下面,我们介绍经典的手工特征检测器、描述符和匹配器,以及近年来提出的那些。每个步骤中基于学习的方法将得到重点审查。我们建议读者参阅最近的一项调查 [2] 以了解更多详细信息。该流程的流程图如图 3 所示。
2.2.1 特征检测
检测到的特征通常表示图像或现实世界中的特定语义结构,可以分为角点[118-120]、斑点[121-123]、线/边缘[124-127]和形态区域特征[128] ,–130]。与线和区域特征相比,点特征由于其简化且易于提取和定义的性质而在图像匹配领域中更容易被接受。提取的线或区域特征如果用于匹配,通常会转换为点形式[131-135]。特征检测的核心思想是构建一个响应函数来区分点、线、区域以及平坦和无区别的图像区域。这个想法随后可以分为梯度检测器、强度检测器、二阶导数检测器、轮廓曲率检测器、区域分割检测器和基于学习的检测器[2]。下面,我们将简要介绍每个类别的主要流程和典型方法,并主要关注为 MMIM 设计的最新手工和基于学习的方法。
(1)角点特征
角特征定义为通常位于纹理区域或边缘的两条直线的交叉点。角点特征提取的代表性响应是基于梯度、强度和轮廓曲率的方法[1,2,136,137]。
基于梯度的特征响应是基于图像的一阶信息实现的,该信息源自[138]中提出的抖动窗口中的局部强度自相关。Harris [118] 改进了该策略,以减轻各向异性和计算负担,从而使其对方向和照明保持不变。Harris 检测器使用二阶矩矩阵来制定强度变化并根据特征值的大小来区分角点特征。为了使 Harris 角点的位置更加准确和分布,[139]进一步改进了它以获得更好的跟踪性能。基于梯度的策略使得Harris特征在MMIM中得到广泛使用,因为梯度可以很好地描述不同模态的两幅图像中保存的结构信息[135,140–143]。
基于强度的角点检测器,又名基于模板或强度比较的检测器,旨在通过将强度值与其周围像素进行比较来简化梯度计算。这种二进制比较策略可以很大程度上节省执行时间,因此广泛应用于许多需要存储和实时性的应用中。[119]中的早期方法使用局部半径区域像素和核之间的亮度差异来识别角点和边缘特征。著名的 FAST 检测器 [144] 使用了相同的概念,即沿着圆形图案对中心与像素进行比较,并进一步改进以增强可重复性 [136] 和鲁棒性 [145]。特别是,Rublee 等人。使用灰度质心方法为每个特征分配一个主方向,使其方向不变,并提出了著名的ORB特征。[146]中引入了一种称为鞍状检测器的更新方法。这种局部像素比较策略可以快速计算,轻松地沿着图像的纹理区域提取足够的兴趣点,这就是它在 MMIM [147-149] 中广泛使用的原因。
基于曲率的策略旨在通过沿着检测到的图像曲线状边缘或轮廓搜索最大曲率来提取角点。该方法通常遵循曲线(边缘/轮廓)提取、曲线平滑、曲率估计和阈值选择的流程[150]。基于曲率的角点检测首先需要曲线特征检测器,这可以通过几种现成的方法进行[124-126]。随后,需要一种平滑方法来抑制噪声的影响。为此,使用高斯方法[151,152]的直接方法可以减轻噪声,但可能会改变曲线位置,而间接方法,例如基于区域支持或基于弦长的方法[153,154],可以更好地保留曲线位置。下一步,曲率的设计可以被视为点特征响应,进一步用于通过阈值策略识别独特的兴趣点。曲率可以用代数或几何形式来估计,例如余弦、局部曲率和切向偏转[151,152,155]。显着性测量还可用于通过计算支撑结构线索(例如点[156]、距离[153]和其他[157,158])来近似曲率响应。
(2)斑点特征
斑点特征通常被定义为局部封闭区域,其中像素被认为是相似的,因此与周围的邻域不同。通常采用两种策略来提取稳定的斑点特征:二阶偏导数(SPD)和基于分割的检测器[2]。
基于 SPD 的检测器通常基于拉普拉斯尺度空间和/或 Hessian 矩阵计算来实现尺度和仿射不变量。通过这种想法提取的特征,又名blob特征,可以用(𝑥,𝑦,𝜃)表示,其中(𝑥,𝑦)是特征位置的像素坐标,𝜃表示blob形状信息,包括尺度和/或仿射。此类特征源自高斯拉普拉斯算子(LoG)[159],它检测多尺度空间中具有归一化高斯响应的局部极值点或区域。LoG是用著名的SIFT方法[121,160]中的高斯差(DoG)来近似的,以减少计算量。SIFT 提取潜在关键点作为 DoG 金字塔中的局部极值,并使用局部强度值的 Hessian 矩阵对其进行过滤。SURF方法[122]使用Haar小波计算和积分图像策略进一步加速了该过程,可以显着简化SPD模板的构造。人们已经研究了基于 SIFT 或 SURF 的许多其他改进,例如增强仿射不变量 [161]、效率 [162] 和可重复性 [163]。
基于分割的方法的核心思想是为每个分割的形态区域拟合最佳椭圆以进行斑点特征检测或使用轮廓或边界进行角点特征搜索。分割区域通常是不规则的,并且基于恒定的像素强度或零梯度,因此能够针对阈值变化保持稳定。著名的基于区域分割的检测器之一是最大稳定极值区域(MSER)[128]。它基于较亮或较暗的极值区域搜索来提取斑点特征。基梅尔等人。[130]扩展了MSER以利用形状结构线索,并引入了许多其他改进以实现更高的辨别力,例如使用曲率图像[164,165]、颜色信息[166]或其他分割基础[167]。最近,通过使用从现有超像素分割方法构建的三个或更多区域的边界的交集,Mustafa 等人。[168]提出了一种 MSFD 角点检测器,以实现更好的宽基线图像匹配。我们建议读者参考[129,169]以获得更全面的介绍。
凭借其鲁棒性、辨别力和定位精度,类 SIFT 方法被广泛应用于各种应用中。许多研究人员已经成功改进SIFT或SURF以消除模态间隙,从而实现MMIM,包括视网膜[170, 171]、多光谱[172–174]、光学到SAR图像[175–177]和可见光的匹配,红外(VIS-IR)图像[178]。
(3)可学习的特征
在深度学习之前,许多检测器在匹配之前使用经典学习(训练分类器)来识别更可靠和可匹配的特征,例如 FAST [179]、ORB [120] 等 [145,180,181]。近年来,深度学习在关键点检测方面显示出了巨大的潜力,特别是对于具有显着外观差异的两幅图像的关键点检测,这种情况经常发生在跨模态图像匹配中。基于CNN的检测器的核心思想是生成响应图,然后搜索显着点位置,这是作为回归问题进行的,可以在几何变换和图像外观不变性约束下以可微分的方式进行训练。一般来说,这类方法可以分为监督方法[123,182,183]、自监督方法[184,185]或无监督方法[186-190]。
有监督的方法已经显示了使用锚点(例如,从 SIFT 方法获得)来指导训练的好处,但性能可能在很大程度上受到锚点构造方法的限制,因为锚点本身本质上难以合理定义,并且可能会阻止,如果附近不存在锚点,网络将不会提出新的关键点[190]。自监督和无监督方法训练检测器无需任何人工注释,仅需要两幅图像之间的几何约束来进行优化指导;,有时需要简单的人工辅助进行预训练[185]。此外,许多方法通过与特征描述和匹配联合训练,将特征检测集成到整个匹配流程中[123,188,191-193],这可以增强最终的匹配性能并以端到端的方式优化整个过程。我们建议读者参考[2,194,195]了解更多细节。
一些探测器,例如 TILDE [182],也在天气和照明条件的剧烈图像外观变化下进行训练。在TILDE中,训练通用回归器来预测分数图,非极大值抑制后的最大值可以被视为潜在的兴趣点。学习策略还可以与手工方法相结合,以提高 MMIM 的性能[196,197]。总之,CNN 可以捕获原始图像的整体结构信息和高阶线索(例如语义信息),从而本质上桥接不同模态图像以提取可匹配的特征点。
2.2.2 特征描述
特征描述是指将特征点周围的局部强度映射为稳定的、有判别力的向量形式,从而能够快速、轻松地匹配检测到的特征。此步骤要求生成的两个匹配特征的描述符尽可能接近,并且两个不匹配特征在描述符空间中相距较远,同时对几何变换、图像外观变化和图像质量具有鲁棒性。描述符设计是基于特征的MMIM中最关键的部分,直接决定最终的性能。一般图像匹配任务的描述符很难在多模态图像对之间建立正确的点对应关系,因此需要研究人员针对特定模态方差数据修改这些方法。根据使用的图像线索(例如梯度、强度)和描述符生成的形式(例如比较、统计和学习)[2],我们将现有描述符分类为浮点描述符、二进制描述符和可学习描述符,随后可以将这些描述符分类为浮点描述符、二进制描述符和可学习描述符。分为梯度统计方法、局部强度比较方法、局部强度顺序统计方法和基于学习的方法。
(1)浮点描述符
浮点描述符通常是通过基于梯度或强度线索的统计方法生成的。基于梯度统计的描述符的核心思想是计算梯度的方向[198]以形成用于特征描述的浮点向量。最相关的方法 SIFT [121] 对每个 DoG 特征使用这种策略,已知该策略是尺度不变、旋转不变和光照不变的。基于类似的概念,SURF[122]利用Haar小波响应和积分图像来简化梯度计算并实现较高的计算效率。SIFT 或 SURF 的许多变体往往在计算效率、鲁棒性和辨别力方面获得更好的性能,例如使用颜色或仿射信息 [161,199] 或平方根核测量 [200] 以及不同域大小中的梯度统计 [201],,仅举几个。
另一种统计策略是基于像素值的顺序而不是原始强度,这已被证明在单峰可见图像匹配中具有优越性[202,203]。按强度顺序进行池化将顺序信息编码到描述符中。该方案可以使描述符成为旋转不变的,而无需像 SIFT 那样估计参考方向,而 SIFT 是大多数现有方法的主要误差源。这种类型的代表性方法包括通过使用序数和空间强度直方图对捕获的纹理信息和结构信息进行归一化来生成描述符[202],或者基于多个支持区域中的梯度和强度顺序来池化局部特征[204]。
由于其独特性和鲁棒性,类似 SIFT 的描述符被广泛修改为 MMIM。,例如,对称 SIFT 已适用于多模态配准 [205],并在 [206] 中得到进一步改进。其他应用和修改包括基于形态梯度和 C-SIFT [178] 执行可见光和红外图像配准,改进 SIFT 算法的特征选择策略 [173],或对其进行调整以适应遥感图像的特征 [175,207] 。
(2)二值描述符
二进制描述符通常基于局部强度的比较策略。该方法的核心挑战是比较的选择规则。一种更具代表性的方法是BRIEF描述符[208],它是通过对图像块中几个随机点对的强度的二进制测试创建的结果串联而构建的。在此概念的基础上,通过集成旋转不变策略并使用机器学习进行选定的鲁棒二进制测试,提出了著名的 ORB [120] 特征,从而减轻了旋转和尺度变化的限制。其他二元选择和比较规则包括半径增加的同心圆采样策略[209]以及比较视网膜采样模式上的图像强度[210]。
由于其简单的比较策略,这种类型的描述符可以以较低的计算和内存需求来执行特征描述。然而,这种方法可能同时牺牲很大的辨别力和鲁棒性,这在图像对具有显着的非线性强度方差的多模态情况下会更糟。因此,二进制描述符并不是 MMIM 的优先选择。
(3)可学习的描述符
基于学习的描述符中的数据驱动策略可以很大程度上增强辨别力,因为可以在 CNN 中提取两幅图像之间的高阶图像线索或语义信息,从而显示出描述不同模态图像的巨大潜力。早期的经典学习策略已在许多手工描述符中得到采用,目的是减少描述符的维度[211-213],将浮点描述符转换为二进制描述符[214-216],并直接从原始补丁中学习二进制表示[217,218] 。
基于CNN的特征描述在训练策略、模型结构和损失设计方面刺激了越来越多的深度描述符的出现。主要目标是学习一种表示,使两个匹配的特征尽可能接近,而不匹配的特征在测量空间中相距很远[219]。一般来说,根据深度模型的输出,现有的深度描述符可以简单地分为度量学习[220-223]和描述符学习[5,224-229]。前者通常学习判别性度量来预测一对原始补丁或生成的描述符是否匹配。相比之下,描述符学习倾向于从原始图像或补丁生成描述符表示。与度量学习不同,这种策略更加灵活和经济,因为它避免了重复计算。另一项有意义的任务是将特征描述与检测器集成到完整的匹配管道中,近年来也得到了广泛的研究[123,185,188,191,192]。耦合特征检测、描述和匹配的优化可以创造卓越的匹配性能。
对于多模态图像,深度描述符可用于预测后续配准任务的匹配标签[230],或与手工制作的特征相结合以实现更好的配准[196,197]。除了相同目标或场景的特征匹配之外,还研究了相似目标/场景的图像的语义匹配[231-235](例如狗和猫之间的匹配)。数据驱动策略是语义匹配的合适选择,并且可以通过使用 CNN 理解语义相似性来实现有希望的准确性。在这方面,基于学习的方法在解决 MMIM 任务方面显示出了巨大的潜力。
2.2.3 特征匹配
假设我们从运动图像中获得了一组M兴趣点,从固定图像中获得了N兴趣点。特征匹配的目的是从两个提取的特征集中建立正确的特征对应关系;,该步骤可以以间接或直接的方式进行,这对应于使用或不使用局部图像描述符。特征检测和描述部分抑制了模态差异,这就是为什么匹配步骤可以通过通用方法很好地执行。
一种直接的方法是直接利用空间几何关系和优化方法来对应这两个集合。两种代表性策略被广泛研究:图匹配和点集配准。间接管道通常将特征匹配视为两阶段问题。第一阶段,根据局部特征描述子的相似度构建假定匹配集,即,其中表示建立的假定匹配集的数量,匹配,这取决于使用哪个匹配标准[120,188,236]。在第二阶段,通过施加额外的局部和/或全局几何约束来拒绝中的错误匹配。一般来说,间接管道可以进一步分为基于重采样的方法、基于非参数模型的方法和宽松的方法。每个类别中基于学习的方法将在相应部分中进行回顾。
(1)图匹配
图匹配(GM)旨在通过定义其中的节点和边来为每个点集构造一个图,然后通过先验图结构相似度最大化整体亲和力得分来建立点对应关系。它通常将点集匹配表述为二次分配问题(QAP)[237]。GM可以简单地分为精确匹配和非精确匹配。前者是指找到两个二元(子)图的双射,要求严格保留所有边[238-240]。这种严格的条件可能会导致实际应用中的性能不佳。
相比之下,不精确匹配在实践中具有良好的灵活性和有效性,从而吸引了更多的研究兴趣。此类中的大多数方法倾向于将约束放松为可承受的形式,从而产生了各种 GM 求解器。具体来说,谱松弛方法通常将此任务转换为特征向量求解问题,可以通过离散化策略[241,242]、进化博弈论的复制方程[243]、非负矩阵分解方法[244]、概率解释策略来求解,[245],或者通过将分配矩阵放宽为正交[246,247]。由于放松,这些方法更加有效,但准确性较低。凸松弛用于将原始非凸QAP问题松弛为具有理论保证的凸形式,通常通过半定规划[248-250]或线性规划[251,252]来解决。近年来,线性规划松弛的对偶问题已被广泛研究以解决GM问题[253-257]。凸凹松弛[258,259]旨在通过使用路径跟踪方法逐渐实现原始问题的凸凹过程。连续松弛方法[260-263]可以近似QAP问题并以准确或有效的方式解决它,但没有全局最优性保证。许多其他方法,例如随机游走方法[264]和蒙特卡罗方法[265,266],也针对GM问题进行了研究。此外,多图[267-271]和超图匹配[272-274]也得到了积极的研究,即联合匹配具有一致对应关系的多个图,并以高阶形式制定GM以主要探索几何线索。
近年来,深度学习技术被广泛用于解决GM问题。亲和矩阵在 GM 问题中起着关键作用,这就是为什么大多数深度学习技术倾向于以监督 [275] 或无监督 [276] 形式获得更好的表示。许多研究人员甚至通过同时学习节点/边亲和力并解决这个组合优化问题,以端到端的方式处理GM问题[277,278]。
(2)点集匹配
与GM方法不同,点集配准(PSR)假设点集之间存在全局变换模型并且预先已知,然后迭代估计模型参数和点对点对应关系。为此,越来越多的技术被提出来提高鲁棒性和求解效率。最具代表性的方案之一是迭代最近点(ICP)[279]及其变体[280-283]。该方法通过鲁棒点匹配(RPM)框架下的软分配和确定性退火策略进行了改进[284,285]。另一种将 RPM 与高斯混合模型 (GMM) 相结合的代表性流程也得到了广泛研究 [286-289],并且通常通过期望最大化 (EM) 求解器进行优化。为了增强鲁棒性和效率,引入了许多其他基于密度和基于优化的方法,例如核密度方法[290]、支持向量参数化策略[291]或模糊聚类方法[292],而基于优化的方法包括随机方法,优化方法[293,294]、分支定界[295-299]和半定规划方法[300]。
除了专注于探索模型公式和优化方法的方法之外,一些 PSR 方法旨在从点集中构造形状描述符,然后利用描述符的相似性约束建立稀疏点对应关系,然后使用鲁棒估计器进行全局变换参数估计,[301–303]。典型的点描述符包括形状上下文(SC)[131]、旋转图像[304]、积分体积[305]和点特征直方图[306]。
(3)间接方法
最经典的失配消除和参数估计方法是基于重采样的方法,也称为随机样本一致性(RANSAC)[301]及其变体[307-311]。这些方法的共同思想是按照假设和验证策略获得最小的一致内点集来拟合给定的变换模型。许多基于 RANSAC 的改进主要集中在验证模型质量,例如在 MLESAC [307,308] 中使用最大似然程序,或者根据内点的特定属性的启发修改采样策略,例如基于空间一致性的 [312],通过,使用分组策略[309]或内点概率预测[313]。一些研究通过局部优化程序 [314,315] 或渐进增长抽样程序 [311,316,317] 解决了这个问题,以消除对用户定义阈值(例如异常值决策)的需要。[310]中介绍了一个集成了RANSAC的许多改进策略的通用框架。值得注意的是,基于重采样的方法可能在很大程度上依赖于重采样策略,并且如果图像对经历严重的非刚性变形,则会遭受相当大的损失甚至失败。而且,理论执行时间随着异常值比例的增加呈指数增长。
开发基于非参数模型的方法来处理刚性和非刚性变换,从而显示出更大的灵活性。这些方法通过以高维形式定义变形函数来代表,例如三角二维网格[318]或使用Tikhonov正则化再现核希尔伯特空间中的核表示[319-321]。这些方法通常通过定制的稳健优化器进行优化,例如 Huber 估计器 [322]、L2E [320]、支持向量回归 [323] 或贝叶斯模型中的 EM 解决方案 [319, 321,324–327]。
另一个活跃的主题是研究用于消除错配的宽松方法。这些松弛规则通常基于局部性或分段一致性的假设[328],例如基于网格的运动统计(GMS)[329]、局部性保持匹配(LPM)[330]及其变体[331,332]、特征匹配,使用具有严重异常值的空间聚类[333]和基于一致性的决策边界[334]。其他策略包括使用过滤理论[335,336]或马尔可夫随机场公式[337]。这些方法非常有效,并且可以处理刚性和非刚性图像匹配。因此,它们更适合实时要求的应用程序,因为它们通过使用不太严格的几何约束来快速获得解决方案。然而,这些宽松的方法通常对参数设置敏感,并且很大程度上依赖于密集的匹配集,这应该很好地保持正确匹配的局部一致性。
近年来,一种学习技术已被广泛研究,并通过训练深度回归器[338-340]或分类器[341-343]来消除异常值和/或估计模型参数。一般来说,参数回归和异常值分类是联合训练的,以提高性能[341]。深度回归器受到经典 RANSAC 的启发,旨在估计变换模型,例如基本矩阵 [344] 或极几何 [339]。例如,可微的RANSAC,即DSAC[338],通过使用强化学习以端到端的方式进行训练,同时还做出了其他努力来改进采样策略[339,340]。至于分类器学习,Yi 等人。[341]首先引入了一种名为 LFGC 的管道,通过从一组假定的匹配集及其图像内在特征中训练网络来找到良好的特征对应关系。马等人。[342]提出了LMR,一种用于消除不匹配的通用二类分类器学习框架,通过使用一些训练图像对和手工制作的几何表示来进行训练和测试。张等人。[345]更多地关注其订单感知网络中的几何恢复。除了使用多层感知器(MLP)学习之外,另一种方法还使用图卷积网络(GCN)[346]来执行此任务。
由于稀疏点的无序结构和分散性,从点数据中学习并不像使用深度卷积网络从原始图像中学习那么容易。即便如此,这种方法仍然值得关注,因为最近的许多研究表明,使用 GCN 和 MLP 网络结构以及定制的归一化项来学习解决基于稀疏点的任务具有巨大的潜力 [2,333]。
2.3 总结
现有的多模态图像匹配方法可以系统地分为基于区域和基于特征的管道。基于区域的方法很大程度上受到测量指标选择的影响。MMIM 通常应用两种可能的策略:一种是使用独立于模态的测量度量,例如 MI 及其变体,另一种是将不同模态简化为公共域。然而,基于区域的方法受到计算负担大以及图像对具有较大重叠和轻微几何变形的要求的限制。该框架中的深度度量学习或深度变换估计极大地缓解了匹配标准设计和迭代优化的困境。然而,这种学习策略仍然受到高图像分辨率和大或复杂变形的限制,特别是需要足够的训练数据。基于特征的管道可以有效地解决几何变形问题。直接特征匹配,例如图匹配和点集配准,更适合包含较少纹理(甚至二值图像)或重模态或语义方差的图像对。在这些情况下,基于图像块的描述符将无效。然而,潜在的真实点对应关系之间的图结构可以稳定地保留,这需要对整体对应矩阵进行优化以找到最优解。但这些直接基于特征的匹配方法受到高计算负担和异常值敏感性的限制。对于间接特征匹配,由于两种模态之间存在显着的非线性强度差异,提取大量和高比例的兴趣点,然后构造独特的描述并准确地对应它们是很困难的。提出一种在准确性和效率方面具有更好配准性能的先进范例仍然是研究人员面临的一个悬而未决的问题。
3 独立于模态的回顾
如上所述,多模态图像的匹配可以被视为一种具体情况。除了一般图像匹配任务 [2] 中提出的这些挑战之外,多模态情况下的主要挑战还包括消除两个输入图像之间的域或模态间隙。然而,不同研究领域的不同成像传感器或数据类型的图像性质会有很大差异。因此,下面我们将回顾这些典型的和最新的图像匹配方法,这些方法是针对不同研究领域(包括医学、遥感和计算机视觉)下的特定多模态场景而设计的。同时,将首先在相应部分分析每种模态的图像性质,以加强对不同模态图像配准的挑战和需求的理解。
3.1 医学
MMIR 最大的家族可能在于医学界。随着计算机成像技术可视化的快速发展,医学成像从统计性成像发展到动态成像、平面成像到立体成像、形态成像到功能成像,在现代医学诊断中发挥了巨大的作用。常用的医学成像技术包括 X 射线、超声成像(UI 或 US)、计算机断层扫描 (CT)、单光子发射计算机断层扫描 (SPECT)、磁共振成像 (MRI)、正电子发射断层扫描 (PET) 和功能性断层扫描 (CT)。磁共振成像(fMRI),生成不同模式的医学图像。从医学应用的角度来看,这些模式可以简单地分为解剖图像(如 CT 和 MRI)和功能图像(如 PET、fMRI 和 SPECT)[347]。解剖图像具有很高的空间分辨率,可以清晰地显示几何信息,例如内脏和骨骼的解剖结构,但没有任何功能信息。相比之下,功能图像可以很好地显示代谢过程中的功能转变,但图像通常不够清晰,无法揭示结构信息,导致解剖结构和边界定位困难。因此,需要组合来自这两种类型的图像的互补信息,这首先需要图像对在空间上对齐。配准目标还包括T1、T2、质子密度(PD)等不同权重的MRI,或者数字减影血管造影(DSA)、眼底摄影、透视血管造影(FA)等不同血管造影的视网膜图像。
在医学研究领域,MMIM 是一个热门话题,并导致配准技术的数量和多样性不断增加。为了解决这个问题,人们提出了几种主要策略,包括(1)信息论相似性度量;(2) 将多模态问题还原为单模态问题(模态统一);(3)基于兴趣点提取和匹配的管道。所有这些策略都可以通过使用深度卷积网络来实现,这将是新小节的主要焦点。
3.1.1 基于信息论
在过去的几十年中,信息论相似性测量成功地缩小了配准任务中多模态图像对之间的差距,这已被广泛研究并扩展到更高级的形式。这一步得益于 MI 的成功使用,由 Viola 和 Wells [46,47] 以及 Collignon 和 Maes [348,349] 引入并推广。近年来,梅斯等人。[347]认识到MI措施给MMIR任务带来了革命性突破。然而,MI的广泛使用和研究揭示了它的一些缺点。首先,它不是重叠不变的。因此,当图像变得未对准时,MI 在某些情况下可能会最大化。
在最大化 MMIR 的 MI 分数的过程中,人们研究了许多先进的信息论方法来弥补上述缺点。例如,Studholme 等人。[48]提出了 MI 的标准化版本,即 NMI,以通过大脑的临床 MR 和 CT 图像体积更好地配准切片。研究了可变形图像配准的最大 MI [49] 的上限,这可以进一步深入了解 MI 作为相似性度量的使用。此外,cMI [50]被提出作为非刚性配准的改进相似性度量。cMI 是基于强度和空间维度的 3D 联合直方图,并通过使用 Parzen 窗口或广义部分体积核进行直方图构建,将其合并到张量积 B 样条非刚性配准方法中。在[350]中,作者提出了一种将空间信息与MI相结合的混合策略,以实现多模态视网膜图像配准。
许多研究人员利用散度度量来比较 MMIR 中的联合强度分布,包括 Kullback-Leibler 散度(KLD)[52,53] 和 Jensen-Shannon 散度(JSD)[54]。Renyi熵[351,352]在配准问题中的使用也引起了极大的关注,它是通过最小生成树或生成图[353]进行的,或者通过与KLD[354]集成以实现更好的泛化。
考虑到这些统计测量通常基于单像素联合分布模型,统计标准也在全局或局部区域中实现。例如,Studholme 等人根据 MI 局部评估的线性加权和进行构建。[51]提出RMI来减少局部强度变化引起的误差。其他人使用八叉树[355]或本地分布式函数[356]。
许多研究人员越来越关注快速准确估计变换模型的优化方法。瓦乔维亚克等人。[83]认为局部优化技术经常失败,因为在基于区域的过程中,这些关于变换参数的度量函数通常是非凸且不规则的。因此,他们修改了一种涉及生物医学 MMIR 粒子群优化的进化方法。阿尔塞等人。[357]使用贝叶斯公式下的 MRF 系数来模拟局部强度多项式变换,而局部几何变换则被建模为 MRF 的先验信息,以配准 MRI T1 和 T2 模态的刚性和非刚性脑图像。此外,弗雷曼等人。[358]提出了一种新的非均匀采样方法,用于在多模态脑图像刚性配准中准确估计 MI。,该方法使用 3D 快速离散曲波变换,通过对与其邻域依赖性较小的体素进行采样来减少采样体素的相互依赖性,从而提供更准确的 MI 估计。遵循 NMI 和 FFD 注册流程,Yang 等人。[359]引入了一种基于协作协同进化的优化方法,该方法将有限内存 Broyden-Fletcher-Goldfarb-Shanno 与边界(L-BFGS-B)和非刚性 MMIR 的猫群优化相结合。在该方法中,块分组策略可以捕获所有变量的相互依赖性,从而实现3D CT、PET以及T1、T2、PD加权MR图像的快速收敛和更好的配准精度。
近年来,考虑到空间信息,Legg 等人。[360]在他们的两阶段非刚性配准框架中提出了特征邻域 MI,以对齐配对的视网膜眼底照片和共焦扫描激光检眼镜(CSLO)图像。这种改进的 MI 优于许多现有的 MI 变体,例如原始 MI、梯度 MI、梯度图像 MI、二阶 MI、区域 MI、特征 MI 和邻域合并 MI。
[29]对本世纪初探索的方法进行了全面回顾;,读者可以参考这篇文章来了解更多细节。基于学习的方法部分回顾了使用深度学习的度量指标。
3.1.2 基于模态统一
另一种策略旨在将两种不同的模态转换为一个公共域,使其可用于单模态图像匹配中成功使用的一般测量指标。使用两种可能的方法将该问题简化为单模态问题:从一种模态模拟另一种模态并将两种模态映射到第三种模态。在这一部分中,我们回顾了遵循这一想法的典型和相关的手工方法。基于学习的方法将引入使用深度网络的方法,例如风格迁移学习和描述符学习。更多详情请参阅相应部分。
遵循这一策略,一些研究旨在根据成像设备的物理特性将一种模态映射到另一种模态。为了配准 US 和 MR 图像,Roche 等人。[361]根据MR图像的强度和梯度信息将MR图像变换到US图像的域中。配准是使用刚性模型并基于扩展相关比方法来执行的。[362]中的另一种方法旨在通过利用US图像的物理原理从CT生成伪US图像,从而实现在局部评估的统计标准下优化的CT-US刚性/仿射配准。除了以全局方式将一种模态映射到另一种模态之外,如果直接使用 MI 度量,还研究了基于局部补丁的策略来识别不可靠区域,然后将这些区域的小补丁模拟到公共域 [363] 。映射策略也是通过学习策略进行的,这将在基于学习的方法部分进行回顾。
将两种不同图像模态映射到通用图像模态的另一种方法是利用形态信息,例如边缘或轮廓结构,这些信息通常存在于两种模态中。许多方法通过过滤[364,365]或使用现有的边缘提取器直接提取这些形态或结构信息。Gabor 滤波可以轻松地从原始图像中捕获纹理信息,这就是它被广泛用于模态统一的原因 [364,366],也可以通过几种局部频率表示进行[365]。
局部描述符还可以将目标像素或体素映射成高维空间中独特的向量形式,使得相似性测量更加方便,从而使优化过程更加有效。受这一思想的启发,许多方法旨在基于自相似图像表示的概念将多模态减少到统一域,该概念首先由 Shechtman 等人在局部自相似性(LSS)中进行研究。[367]。LSS是一种局部特征描述符,可以捕获图像中LSS的内部几何布局并间接表示局部图像属性,这就是为什么它可以用来匹配两个具有显着外观差异但布局或几何形状相似的纹理区域。此外,提出了一种称为模态独立邻域描述符(MIND)[368]的描述符来提取局部邻域中的不同结构以生成描述向量,从而将不同模态的图像转换为第三域,其相似性可以通过以下方式轻松测量,任意指标,例如 SSD。,作者将此描述符应用于对称非参数高斯-牛顿配准框架,并在刚性和可变形变换下良好配准 3D CT 和 MRI 胸部扫描。MIND 的使用使得该描述符对图像噪声和图像强度的非线性方差具有鲁棒性。因此,所提出的技术将适用于任意模式的注册任务。同一作者引入了一种新的结构图像表示,称为自相似上下文(SSC)[369],以实现高效计算。SSC还基于自相似性描述符的概念来表示公共空间中的图像块,从而使得相似性度量更容易应用。这个想法是通过使用对称多尺度离散优化和扩散正则化来注册 3D US 和 MRI 脑扫描来搜索准确的变形参数。
[370]中的作者提出了基于熵和拉普拉斯图像的结构表示以及 SSD 度量(即 eSSD)来测量块相似性,然后用它来驱动 T2–T1–PD MRI 和 PET–CT 图像的配准过程,在刚性或非刚性变换下。该方法通过具有局部距离保持约束的流形学习方案在流形空间中创建中间结构表示。[371]的作者解决了eSSD在噪声敏感性和高计算负担方面的弱点,他们引入了一种基于韦伯局部描述符(WLD)的新相似性度量。[372]中使用扩散图来捕获不同模态的两幅图像的几何和光谱特性,从而更好地表示复杂的图像特征,从而提高配准性能。Rivaz 等人提出的自相似性 𝛼-MI (SeSaMI)。[373]在基于图形的 MI 实现中使用局部结构信息进行非刚性图像配准。里瓦兹等人。[374]还在相似结构上条件化MI估计的基础上提出了上下文条件化MI。,该方法考虑相应像素的强度值及其相邻像素的上下文信息。
与 MIND 类似,提出了另一种基于自相似性的局部描述符,称为基于 Zernike 矩的局部描述符(ZMLD)[375],以增强相似性度量的鲁棒性和辨别力。引入的自相似性是基于图像块的Zernike矩以及局部邻域来生成描述子,直接计算其在欧几里得空间中的距离作为测量标准。对 T1-T2-PD 加权 MR 脑图像和真实 MR-CT 图像进行大量实验,结合基于样条的 FFD 变换和 L-BFGS 优化方法,证明了该方法相对于 NMI、ESSD、WLD 和 MIND 的优越性。这个想法可以用二进制描述符来实现,例如判别性局部导数模式(dLDP),将不同模态的图像编码为相似的图像表示[376]。dLDP 根据其邻域的强度导数模式计算每个体素的二进制字符串。使用汉明距离来评估描述符相似度,可以有效地计算该距离。
3.1.3 基于特征点
鉴于医学图像的纹理减少,基于特征的方法很少用于该领域的匹配任务。然而,全局结构和计数器或边缘通常存在于不同模态的两个图像中,从而提供可匹配的信息。目标图像对有时会覆盖小的重叠区域或大的变形,这在基于区域的管道中通过相似性测量进行优化非常困难,从而启发研究人员设计可行的特征检测、描述和匹配方法来处理这些问题。凯尔曼等人。[377]针对代表性的基于特征的方法评估了一般MMIM。
这个想法广泛应用于配准不同模态的视网膜图像对。例如,陈等人。[140]提出了针对低质量图像对的部分强度不变特征描述符(PIIFD),它是用Harris特征执行的,因此也被称为Harris-PIIFD。,在多模态视网膜图像匹配中成功使用 PIFD 描述符的基础上,Ghassabi 等人。[170]结合使用UR-SIFT特征和PIIFD描述符,取得了可喜的性能。考虑到 Harris-PIIFD 在面对较大的内容变化时可能无法正确地将彩色视网膜图像与其他模态对齐,Wang 等人。[378]提出了一种名为 SURF-PIIFD-RPM 的鲁棒点匹配框架,用于多模态视网膜图像配准。在该方法中,首先利用 SURF 检测器从两幅图像中提取可匹配的点特征,然后作者使用 PIFD 描述符进行匹配。随后,基于在再现核希尔伯特空间中进行的核方法的单高斯鲁棒点匹配模型被用来估计假定匹配集中与现有异常值的映射函数,以获得更好的匹配性能。遵循类似的策略,[171]中介绍了 SIFT 和 PIFD 与异常值拒绝策略的结合使用。此外,还设计了残差缩放加权最小二乘法来强制执行仿射变换模型,该模型明显优于 Harris-PIIFD 方案。除了上述策略之外,对称 SIFT 还被采用来通过刚性变换估计快速配准 CT 和 MR 脑图像 [205],[206] 对此进行了进一步改进。
最近,李等人。[379]提出了彩色眼底(CF)和扫描激光检眼镜(SLO)视网膜图像的两步配准程序。第一步,生成平均相位图像进行特征描述符匹配,并结合RANSAC方法估计全局仿射变换,然后利用MIND来细化局部精度,从而实现变形配准。
3.1.4 基于深度学习
具有深度网络的 MMIR 医疗应用是一个活跃的研究领域,并导致出版物的数量和多样性不断增加。与传统方法类似,学习策略通常用于解决模态差距,从而简化注册过程。正如在总体框架(即第 2 节)中提到的,这个概念通常表现为相似性度量学习、模态迁移学习以将多模态问题简化为单模态问题,以及端到端学习以直接估计变换参数或位移场,一步之遥。
(1)度量学习
度量学习可以被视为手工相似性度量的直接扩展,例如类似 SSD 或 MI 的方法,并且这些学习到的度量可以更好地指导迭代 MMIR 过程。[380]中基于早期学习的方法提出了通过联合内核机器学习以判别方式学习相似性度量,使得参考图像和正确变形的图像获得高相似性分数。为此,作者开发了一种源自最大边缘结构化输出学习的方法,并在标准刚性配准算法中采用了学习到的相似性度量。[87]中引入了堆叠式去噪自动编码器(SAE)来学习刚性 CT 和 MR 图像配准的相似性测量。在[89]中,通过对齐的 3D T1-T2 加权大脑 MR 体积学习,可以获得深度相似性度量,并将其与梯度下降法集成,以迭代估计预定义变形场的参数。为了估计 3D US-MR 腹部扫描配准中刚性模型的参数,Sedghi 等人。[381]使用一个简单的五层神经网络来学习可以测量配准水平的相似性度量。然后通过鲍威尔方法以迭代方式优化该学习指标。在[88]中,作者提出了一种新颖的策略来训练网络,通过预测配准性能评估(例如 TRE)来获得相似性度量。在该策略中,利用进化算法来探索解空间,实现经直肠超声 (TRUS) 和 MR 图像的刚性配准。与上述方法不同,Wright 等人。[382]训练了 LSTM 空间协同变换器网络来指导迭代过程,然后实现 3D 胎儿 MR-US 脑部扫描的配准。这种深度方法优于其他相似性度量和基于自相似性的描述符。
(2)强化学习
强化学习首先是在医学图像配准问题中探索的。第一个将 RL 用于 MMIR 的团队是 Liao 等人。[91]。他们试图通过单个代理的 Q 学习来实现心脏和脊柱 3D CT 和锥束 CT (CBCT) 图像的严格配准,其中利用贪婪监督方法和注意力策略进行端到端,训练。马等人。[92]对深度和CT图像对进行严格配准进行强化学习,其中借用Q学习策略来提取特征表示以消除两幅图像的外观方差,并捕获上下文信息来指导配准以增强性能。为了配准脊柱的 X 射线和数字重建射线照片,Miao 等人。[94] 在他们的 RL 范式中设计了马尔可夫决策过程中的扩张 FCN 和多智能体系统。他们使用自动注意机制来捕获多个区域之间的深层信息。该方法可以大大提高配准的效率和准确性。
(3)变换模型估计的监督学习
为了避免迭代管道(例如度量学习或基于强化学习的方法)中的大量计算负担,越来越多的研究以端到端的方式估计几何变换参数。正如 Salehi 等人首先进行的那样,刚性模型更容易通过深层框架进行估计。[97]和斯隆等人。[383],他使用深度回归网络生成刚性参数来对齐 T1-T2 加权大脑 MR。[97] 中的作者基于双变量测地距离构建了损失函数,并在校正网络之前首先通过残差网络注册了 MR 体积组。该策略可以扩大其网络的捕获能力。作者在多模态 2D-3D 和 3D-3D 配准问题上验证了定制损失及其网络。[383]的作者使用他们的深度网络进行单模态和多模态配准。用于提取深层特征的这些层的参数在单模态情况下是共享的,但在 MMIR 中是单独学习的。
更具挑战性的问题是学会在非刚性情况下一步估计可变形模型参数或变形场。杨等人。[101]通过使用非刚性模型参数分布的低阶 Hessian 近似解决了 3D T1-T2 加权大脑 MR 体积的问题。在[384,385]中,Hu 等人。训练他们的合作网络(即全局网络和局部网络)来分别估计全局和局部精细变形场,并且他们应用此管道来配准可变形 MR-TRUS 前列腺图像 [384]。整个框架基于分段标签的相似性进行训练,并通过以密集位移场(DDF)作为变形建模的FCN网络进一步修改为端到端学习形式[385]。在[106]中,胡等人。旨在通过使用 GAN 模型通过最大化分段标签相似性和最小化对抗性损失来执行可变形 MR 和 TRUS 配准。与使用标签相似性来指导网络训练类似,Hering 等人。[103]利用基于 U-Net 的架构,并基于标签和相似性度量构建了损失函数,用于 2D cine-MR 图像的变形配准,进一步应用于心脏运动追踪。
(4)用于变换模型估计的无监督学习
除了使用带注释的标签进行监督训练之外,还研究了越来越多的无监督方法。为了执行 3D MR-US 脑体积配准,应用了一种无监督框架 [113],该框架使用 3D CNN 进行特征提取和变形模型回归。该方法利用基于像素强度和梯度信息的相似性度量来实现无监督训练。[111]中的类似方法训练由传统相似性度量(例如 NCC)引导的深度网络,并基于预对准图像对来配准可变形骨盆 CT 和 MR 体积。在[386]中,作者使用编码器-解码器范例来生成与模态无关的潜在表示,以循环一致的方式执行,并且他们使用逆一致损失来指导 STN 在简单相似性下学习仿射和非刚性变换,约束,例如 MSE。,所提出的方法可以在 2D 或 3D T1 和 FLAIR MR 大脑数据上实现有希望的性能。
(5)用于变换模型估计的 GAN
还针对医学切片或体积的 MMIR 研究了 GAN 模型。严等人。[108]提出了一种 GAN 范例来严格注册 3D MR 和 TRUS 前列腺活检体积。核心思想是迫使经过训练的判别器识别卷组的对齐是通过真实变换执行的还是由生成器生成的,同时需要一个更先进的生成器,其输出更接近真实值,从而能够,欺骗鉴别器。随后,玛哈帕特拉等人。[112]通过将包括 NMI、SSIM 和 SSD 在内的几种相似性度量与 GAN 框架中的高级对抗性和循环约束损失相结合来构造损失项,以应对视网膜 CF 图像和荧光素血管造影(FA)图像的 MMIR。
最近,基于 STN 和 GAN 框架,[104] 中训练了 U-Net 以生成对抗性损失,从而指导训练过程。为了避免训练时需要 ground truth 变形场、带注释的地标或任何对齐的多模态图像对,Qin 等人。[109]尝试以无监督的方式学习潜在嵌入空间中模态统一的参数化配准函数。任何有意义的几何变形都可以在潜在空间中直接导出。该框架设计了三个组件:通过不成对的图像到图像转换的图像解缠网络、解缠潜在空间中的可变形配准网络以及隐式学习图像空间中相似性度量的 GAN 模型。整个过程是通过将自重建损失、潜在重建损失、跨循环一致性和对抗性损失与潜在空间上定义的相似性度量相结合来执行的。GAN 框架还可以将一个图像域转换为另一个图像域,从而将图像模态简化为通用模态[387-390]。通过这种方式,可以利用用于传统基于区域的配准的任意相似性度量来构造损失项来指导网络训练。
(6)混合方法
[391]中引入了监督学习方法来学习 MMIR 的优化更新。该方法将问题作为一个回归任务,利用Haar-like特征来估计基于局部结构和全局外观信息的未知变换,其变换参数通过大特征空间中的回归森林来建模。[117]中使用预训练网络作为特征提取器,其中可以提取兴趣点,然后将其馈送到MLP回归模型以预测几何变换,并且点的数量是固定的并变成超参数。该技术可以执行零样本学习,无需对齐图像对或 ground truth 转换进行训练,从而实现大脑 T1-T2 加权 MR 的实时配准。此外,引入了基于拉普拉斯特征图[392]的流形学习方法,通过结构表示将多模态图像嵌入为单模态问题。
3.2 遥感
另一组MMIM被研究用于遥感应用。高分辨率传感器的显着发展导致越来越多的遥感卫星用于获取图像数据,例如Ikonos、Quickbird、TerraSAR-X、Cosmo-Skymed和WorldView[393]。遥感图像根据成像系统的类型通常分为被动方式和主动方式两类。
被动光学图像是指利用被动传感系统在可见光和近红外(NIR)光谱波段捕获的遥感图像,通过电磁波反射到相应的传感器获得的,准确地表示颜色和颜色的遥感图像。目标的亮度信息。这些图像可以进一步分为全色图像和多光谱图像。在主动成像系统中,光探测和测距(LiDAR)倾向于以主动方式构建图像,其中从发射器发射红外、可见光或紫外范围内的电磁脉冲。与无线电探测和测距 (RADAR) 系统相比,LiDAR 系统具有许多优势,这对于测量远处物体和表面的范围具有重要意义。合成孔径雷达(SAR)是微波雷达的另一种主动成像形式。SAR通常反映目标的两个特征,即结构信息和电磁散射信息[394]。
多种遥感应用需要结合使用这些数据,例如土地覆盖绘图 [395]、变化检测 [15, 17] 和数据融合 [396]。多种模态的图像配准可以提供联合使用多种信息的能力,从而获得更大的数据量、更短的重访时间以及互补特征的利用[397]。以广泛使用的光学和SAR图像匹配为例。由于这两种成像方式的明显差异,光学图像和SAR图像之间存在很大的外观差异,这可以解释成像区域的不同特性。此外,SAR系统可以在白天和夜间工作,并且可以穿透雾和云,这是无源光学传感器无法做到的。在这种情况下,结合历史光学图像和当前捕获的SAR图像的信息对于分析成像区域非常重要,使得光学图像和SAR图像的配准成为核心且不可避免的问题。然而,SAR 图像中的强散斑噪声将导致难以提取匹配任务的有效特征[175]。
除了光学与SAR或光学与LiDAR图像之间的匹配之外,其他匹配目标还包括地图到光学、无人机跨季节、光学昼夜和跨时间图像对。接下来,我们将通过基于区域、特征点和基于学习的管道的分类,对这些多模态数据的匹配方法进行详细而全面的回顾。
3.2.1 基于区域的方法
正如第 2 节中介绍的,与医学图像配准类似,基于区域的框架用于处理多模态遥感图像对。然而,核心挑战是如何设计和使用合适的相似性度量来驱动迭代过程,从而准确估计几何变换。一种直接的解决方案是利用或修改信息论下为多模态图像设计的常用指标,例如 MI 和 NMI。,另一种方法是通过将多模态图像减少到统一域来间接使用相似性度量,这通常通过域转移技术来执行,例如快速傅里叶变换(FFT)、结构信息提取以及通过以下方式将图像强度映射到高维空间:,使用描述符。还研究了配准问题的高级表述和寻找最佳解决方案的优化方法。
(1)基于信息论的方法
基于信息论的相似性度量在MMIR中的成功使用促使许多研究人员遵循这种策略来处理具有显着非线性辐射差异的遥感图像对的配准问题。使用 MI 的相似性度量对于光学和 SAR 图像配准非常有用 [398–401],并且通过与基于特征的方法结合使用来进一步改进 [402, 403]。[393] 中引入了 MI 峰值度量,以实现专门在城市地区获取的高分辨率 TerraSAR-X 和 Ikonos 图像的自动配准。所提出的度量涉及直接根据图像强度值估计联合直方图,图像强度值可能是由不同的传感器几何形状和/或模态生成的。徐等人。[404]提出了MI的对称形式,即Jeffrey散度(JD)作为相似性度量,并对SPOT图像、Landsat TM图像、ALOS PalSAR图像和数字高程模型(DEM)的配准进行了数学分析和实验,数据与仿射模型。通过提供更大的可行搜索空间,基于JD的配准模型更能够配准小重叠区域的多模态图像对。
(2)基于频率的模态统一
为了避免使用类 MI 方法的限制,一种更有效的策略是构造图像表示,从而将多模态图像简化为统一的图像。该方法通过使用 FFT 在频域成功进行,其中由 De [405] 和 Reddy [406] 开发的相位相关或相位一致性(PC)算法被广泛用于配准需要提取常见结构的多模态图像。消除模式差距。受到基于阶段的方法的成功使用以及解决显着模态和几何差异的启发,Xie 等人。[407]扩展了基于多尺度log-Gabor [409]滤波的早期方法[405,406,408],并将他们提出的方法称为MLPC。,该方法在 LGEPC [410] 中得到进一步改进,用于配准光学红外、LiDAR 深度光学和全色到城市地区或建筑物的多光谱图像对。
(3)基于描述符的模态统一
实现模态统一的另一种策略是使用特征描述符将图像强度嵌入到高维特征空间中。为了注册从岛屿和海岸线场景捕获的 MODIS 数据中的不同通道,[411] 中的作者提出了一种基于自适应加权策略的新颖 MI 方案,该方案在通过有效 LoG 和针对显着特征的引导过滤方法构建的特征图上进行,萃取。在[412]中,作者旨在通过类光流算法来密集配准光学和SAR图像。在该方法中,基于一致梯度计算(即 GLOH)构建的密集描述符被用于光学和 SAR 图像表示和匹配。针对全局和局部图像内容进行的两个协作框架分别用于全局目标函数优化和局部流向量计算。该方法采用由粗到精的策略,适用于大位移场景。最近,受到基于特征的方法和 PC 策略的启发,Xiang 等人。[413]结合了光学和SAR图像以及3D PC的鲁棒特征表示。为了准确估计 3D PC,在空间域和傅立叶域中提出了两种解决方案。采用约束能量最小化方法在逆FFT后的空间空间中寻找狄拉克δ函数,并采用快速样本一致性拟合方案来估计频域中的线性相位系数。
(4)侧重于公式化和求解的方法
除了关注更好地使用传统基于区域的框架的相似性度量之外,先进的问题表述或解决方案对于提高配准的准确性和效率至关重要,因此由于高分辨率、噪声而引起了遥感界的高度关注。,以及大规模的性质。在[414]中,作者主要关注适应MI成本函数的优化方法,并提供了实用的解决方案。所提出的逆组合优化方法表明,使用基于 Hessian 矩阵的特定优化方法可以使配准更加鲁棒并且计算量更少。哈桑等人。[415]借用交叉累积残差熵(CCRE)进行遥感SAR和谷歌卫星图像配准。在该方法中,研究了基于部分体积插值的 Parzen 窗优化方法的新扩展,用于计算相似性度量的梯度中的解空间搜索,其中几何变换被建模为二次多项式或,仿射矩阵。
卡兰扎洛斯等人。[416]提出了一种光学雷达卫星数据的自动配准框架,该框架基于MRF公式和线性规划解决方案,并利用NCC和NMI等相似性度量作为光谱保存约束。实验数据覆盖城市、农业、沿海、林区。乌斯等人。[417]提出了一种基于精度估计配准(RAE)的新的基于区域的方法,并为粗略配准的图像对之间的每个局部对应定义了配准误差的 Cramer-Rao 下界(CRLB)。该方法根据局部图像纹理和噪声特性估计CRLB,有助于容忍异常值并提高变换估计的准确性。整个流程用于在仿射和二阶多项式模型下配准光学雷达 DEM 图像。
3.2.2 基于特征
在执行多模态遥感图像配准时,基于区域的管道可能存在一些限制。遥感图像具有高分辨率成像,并且通常包含由成像传感器和大气引起的严重噪声,导致使用相似性度量来指导优化时产生巨大的计算负担。此外,图像对通常是在显着的几何方差下捕获的,例如大的旋转、缩放、变形和小的重叠区域,使得解空间复杂且难以优化。基于特征的管道更广泛地用于处理遥感图像,其中主要挑战是提取多模态图像中的可重复特征点,然后正确匹配它们。
(1)基于现有特征算子的方法
最直接的策略是通过直接修改SIFT、Harris等现成的方法来实现特征检测和描述。例如,[172] 中的作者首先使用 SIFT 特征算子和仿射模型估计来粗略配准多源图像对。然后,在精细尺度配准的过程中,他们提取了哈里斯角点,然后进行分段线性变换。最后,利用不规则三角网络(TIN)和仿射估计进行局部变形校正。所提出的方法在城市、湖泊或河流区域拍摄的 Quickbird 全色图像、SPOT5 全色图像、SPOT4 和 TM 多光谱图像的配准上得到验证。此外,易等人。[418]提出了SR-SIFT,一种梯度方向修改描述和尺度限制策略,以适应SIFT用于多光谱图像配准。
为了修改经典的 SIFT 方法,使其能够有效地配准多光谱或全色图像的跨波段,Sedaghat 等人。[173]在特征位置和尺度完全分布的情况下,改进了SIFT算法的特征选择策略,称为均匀鲁棒SIFT(UR-SIFT)。在该方法中,基于稳定性和独特性约束来限定和选择特征。随后,在投影变换估计期间利用初始交叉匹配过程和一致性检查策略来正确构建特征对应关系和图像对齐。测试数据涵盖了城市和农村地区从1到30 m的各种空间分辨率。[419]中引入了另一个 SIFT 改进,通过扩大描述符的池范围来适应多传感器遥感图像的特征。Fan 等人通过应用与改进 SIFT 类似的过程,使其可用于光学和 SAR 图像匹配问题。[175]描述了在多个支持区域下提取的特征,并引入了空间一致匹配策略以获得可靠的特征对应,然后通过RANSAC来估计用于图像配准的单应性模型。
(2)基于高级特征描述符的方法
越来越多的研究专注于设计有效的描述符来构建更可靠的特征匹配,以便可以正确估计变换参数。受到自相似策略 [367] 的启发,Sun 等人。[174]引入了多尺度自相似性(MSS描述符)来初步构造特征点集。然后,他们基于GMM模型进行相干点集分析,以对应仿射参数估计下的点集。这被认为是概率密度估计问题,与EM解决方案一起,该方法的优越性在城市的多光谱和可见光谱图像上得到了证明。
Sedaghat 等人遵循类似的流程。[207]使用UR-SIFT[173]来统一检测局部特征,并引入一种先进的自相似描述符,称为独特的基于顺序的自相似性(DOBSS描述符)来匹配检测到的特征点。然后通过描述符交叉来识别可靠的匹配,受投影变换约束的匹配和一致性检查策略。[420]中引入了基于秩的局部自相似性(RLSS)描述符,以解决光学图像和SAR图像之间严重的非线性辐射差异以进行配准。所提出的RLSS受到Spearman的秩相关的启发,系数,并进一步用于以基于块的 Harris 检测器从图像对中提取的点位置为中心的几个子区域的模板匹配。
提出了另一种策略,通过频域中的 PC 来描述检测到的特征,该策略通常用于与 PC 和经典特征嵌入方法相结合来设计高级描述符。叶等人。[421]将PC与方向直方图策略集成,以根据图像的结构特性描述提取的特征;,这个过程称为 HOPC。,作者首先通过基于块的 Harris 算子和top-k选择来检测控制点,然后在这些控制点周围应用快速模板匹配方案。名为的相似性度量是根据 HOPC 描述符的 NCC 定义的,以指导此匹配过程。通过投影变换模型中的全局约束消除不可靠的点匹配,并通过基于控制点的精细匹配的分段线性模型估计来实现最终的非刚性配准,该模型在多个可见光、红外、地图和激光雷达上进行了验证,数据覆盖城市和郊区。
范等人。[135]通过结合改进的 Harris 和相位一致性结构描述符(PCSD)提出了一种特征点检测、描述和匹配流程来配准 SAR 光学、光学激光雷达和红外光学图像。基于均匀非线性扩散的Harris特征提取旨在减少散斑噪声的影响。基于结构特征对模态变化不太敏感的观察,他们通过使用PC结构图像以分组的方式提出了PCSD。,利用PC方法在减轻模态差异方面的优势,对图像之间的辐射差异具有更强鲁棒性的多尺度PC(MS-PC)描述符[422]被用作相似性度量来实现对应关系构建。崔等人。[423]构建了基于非线性扩散函数的尺度空间,使所提出的方法适用于不同的分辨率。然后使用逐像素局部PC方法来提取独特的特征点。这些点特征通过提出的旋转不变性描述符进行匹配。
(3)基于共轭结构图的方法
除了专注于设计更好的特征检测器和描述符的方法之外,还有几种方法尝试首先提取共轭结构,例如梯度、边缘和计数器。在结构图的基础上,基于特征的匹配框架可以可靠地执行特征匹配和图像配准。
遵循这一想法并注册机载光学和 C 波段 SAR 图像,Huang 等人。[142]首先提取边缘特征来抑制噪声。随后,预处理后的特征被视为点集,并使用改进的 SC 进行匹配,随后用于估计仿射变换。文献[177]对经典的SIFT进行了修改,使用基于迭代水平集的分割方法来提取共轭特征,以避免由于特征提取不良而导致的配准失败;,这称为 ILS-SIFT。,该方法经过验证,可以使用所提出的改进 RANSAC 在多项式变换估计下配准光学图像和 SAR 图像。[424]中的另一种策略涉及基于受[425]启发的迭代线提取来执行光学和SAR图像配准,然后在从粗到精的配准方案下进行线相交匹配。在该方法中,利用Voronoi方法[426]和光谱点匹配策略[427]来提高匹配精度。
[428]提出了另一种新颖的光学和SAR图像配准方法,该方法基于直线特征提取和MI。,该方法首先使用不同的边缘检测器来执行光学图像和SAR图像中的线段。然后,通过霍夫变换和直线拟合,提取每幅图像的主直线,得到它们的交点作为候选匹配点。最后,采用 RANSAC 粗略配准图像对以生成补丁对,随后针对 MI 测量下的精细配准进行优化。
鉴于 PC 在共轭结构提取方面优于梯度 [429],Zhang 等人。[147]提出了一种配准多时相无人机图像的新方法。作者首先利用PC来描述图像的结构特征,在此基础上检测FAST角点,然后通过最大索引图构造的特征描述符的相似度进行匹配,然后采用RANSAC方法进行仿射模型,估计和失配消除。
考虑到图像之间的结构相似性可以很好地保留并用于跨不同模态的图像配准,Ye 等人。[143,430]首先基于现有的局部描述符(例如 HOG 和 LSS)生成密集描述的图像。然后,他们使用 3D-FFT 和定向梯度来定义频域中的相似性度量,通过模板匹配方案确定和匹配提取的 Harris 角点中的控制点。在三次多项式模型估计和一致性判断中执行迭代失配消除过程,并在基于TIN和局部仿射估计的分段线性变换模型下验证整个大尺寸图像对的最终性能。
受 MSER 和合并相位一致性理论的启发,Liu 等人。[431]提出了一种新颖的仿射和对比度不变描述符,称为最大稳定相位一致性(MSPC),它将仿射不变区域提取与结构特征结合起来以实现图像配准。特别是,首先通过 PC 图像的矩排名分析来检测兴趣点。结构特征是通过所提出的 SFE 方法从多方向 PC 构建的。随后,根据引入的MSPC描述符的相似度对提取的点进行匹配,然后通过RANSAC算法进行精细匹配、仿射模型估计和图像配准。基于类似的策略,[432]中的作者基于PC和重要性排序空间从尺度适应的红外和可见光图像中提取了共同的结构特征。随后将这些特征与所提出的核化相关滤波器进行匹配。
Li等人提出了一种基于PC和最大索引图(MIM)的更通用的方法。[148],即辐射不变特征变换(RIFT)。在RIFT中,作者首先根据生成的PC图检测到更好的重复角点和边缘特征点。然后,他们基于log-Gabor卷积序列进行MIM进行特征描述,从而通过构造多个MIM来实现旋转不变性。所提出的方法在匹配一般多模态图像(例如光学到 SAR、红外到光学、深度或地图到光学以及昼夜图像对)方面表现出了良好的性能。
(4)其他
一些研究主要集中在图像配准的制定和框架设计上。在[176]中,作者提出了一种用于多光谱遥感图像配准的两阶段(从粗到精)框架,称为预配准和精细配准。在粗略阶段,利用SR-SIFT [418]来初步估计和纠正几何差异,例如尺度和旋转。在第二阶段,从预先对齐的图像对中检测哈里斯角点,并基于局部自相似性描述符[367]构建点对应关系,然后采用全局一致性检查策略来消除错误匹配。最后,作者通过分段线性变换模型实现了配准,并在多光谱图像对上进行了测试。
光学图像和激光雷达图像之间的结构差异给检测这两种模式的重复点带来了困难。黄等人。[394]提出了一种有效的技术来对齐从高地牧场或城市地区捕获的光学和激光雷达图像。在该方法中,首先通过选择 Harris 提取器的顶部响应来检测 LiDAR 图像中的候选控制点(CP)。然后,通过局部特征映射变换优化和FFT加速来确定LIDAR和光学图像对之间的CP周围的一组区域对应关系,这是基于与局部区域的SSD成本度量的相似性匹配来进行的。他们还使用 RANSAC 算法来寻找可靠的特征对应关系,这些特征对应关系进一步用于估计非刚性变换模型,然后通过归一化直接线性变换(DLT)算法对齐图像对。此外,马科斯等人。[397]旨在通过为多传感器遥感图像中的每个超像素提取域不变特征表示来执行域自适应。他们提出了一种基于光谱邻居空间分布的中层表示,并在通过迭代条件模式算法优化的 MRF 模型中表述了这一点。
最近,考虑到传统的匹配方法由于多源图像之间存在较大的辐射和几何失真,无法构建大量和高比例的正确点匹配,Deng 等人。[433]受到图论的启发,提出了一种两阶段失配消除方法。他们首先使用聚类策略来表示局部几何相似性,而不预先考虑任何全局几何模型。该簇是由完整图形公式中的匹配三角形构建的。然后,他们使用TIN来近似完整的图,这可以大大简化计算复杂度。
3.2.3 基于深度学习
越来越多的研究集中在具有深度技术的遥感图像MMIR上。此类方法的常见策略是(1)生成深层和高级图像表示以获得更多重复特征点和/或高级描述符以获得高数量和高比例的准确特征匹配;(2) 学会将一种模态转移到另一种模态,从而使传统方法能够成功执行 MMIR;(3)直接预测端到端范式中的底层转换模型。
更直接的方法是将 CNN 集成到传统的图像匹配流程中,例如生成可训练的特征检测器、描述符或相似性测量,以增强配准性能。杨等人。[434]提出了一种基于CNN特征的多时相遥感图像配准方法,通过学习多尺度特征描述符并逐渐增加内点的选择来提高配准性能。多尺度特征描述符由预训练的 VGG 网络生成,并集成 TPS 模型来解释 GMM 和 EM 框架下的非刚性变换和估计。为了弥补经典 SIFT 仅使用局部低级图像信息的弱点,[196]旨在通过采用新兴 CNN 的优势并融合 SIFT 和 CNN 特征来开发中级或高级信息。简单相似变换下的多光谱和多传感器图像配准。同样,马等人。[197]将配准任务视为两阶段框架中从粗到细的问题。他们最初使用基于图像特征层的深层架构来近似空间关系,例如使用 VGG-16。,该深度模型可以作为特征提取器来实现金字塔特征检测。后来,作者结合使用深度和手工局部特征以及RANSAC方法进行精细特征匹配和变换估计,提高了配准的准确性。此外,[435]中引入了密集连接的 CNN,用于可见光和红外遥感图像配准。具有密集连接的卷积构建块的通道堆叠网络被设计用于捕获低级特征并驱动模板匹配。此外,提出了增强的交叉熵损失来指导训练过程,具有更好的学习能力和稳定性。
[436]中引入的另一种学习策略涉及解决训练所需的海量数据的需求。作者提出了一种生成匹配网络(GMN)来为真实 SAR 图像生成耦合模拟光学图像或为单个光学图像生成伪 SAR。,然后将这些生成的补丁对输入深度匹配网络,以利用多模态补丁对之间的潜在且连贯的特征来推断其匹配标签。该方法在[230]中得到了完善和改进,提出了一种端到端架构,可以直接从生成的补丁对及其匹配标签中学习以供以后注册。[437]中采用了类似的想法,其中作者结合了条件 GAN(cGAN)和几种手工方法(例如 NCC 度量、SIFT 或 BRISK)来提高光学和 SAR 图像的配准性能。其核心思想是使用 cGAN 进行训练,从光学图像中生成类似 SAR 的图像块,从而实现模态统一,使其适用于许多为单模态图像匹配而设计的方法。最终的细化特征匹配是通过带有底层仿射模型约束的 RANSAC 获得的。
考虑到经典方法的特征设计困难和梯度下降优化缓慢,Zampieri等人。[438]设计了易于训练的全卷积神经网络来学习特定尺度的特征,从而在线性时间内实现非刚性 MMIR。,该方法可以直接预测微分同胚建模的最佳变形参数,从而避免了迭代过程。这个想法在建筑物或房屋的注册可见图像和二进制地图上得到了验证。
我们可以看到,针对遥感应用MMIR设计的基于CNN的方法并不像医学领域那样丰富和活跃。主要原因是难以捕获足够的多模态遥感图像用于训练和测试,以及遥感图像的复杂性,如高分辨率、混合噪声和大的几何方差。这些挑战要求研究人员更加关注收集可用数据集,并引入更有效的深度配准框架、损失函数和训练策略,以获得多模态遥感图像的高级匹配性能。
3.3 视觉
在计算机视觉领域,图像匹配最活跃的研究涉及单峰图像对。核心挑战是如何处理大的几何变形以及由视点变化和负成像条件引起的低图像质量。典型的障碍包括图像旋转、缩放、仿射、局部失真、背景噪声、遮挡、异常照明和低纹理[2]。
在MMIM中,由于研究人员在通用图像匹配方面的巨大努力和成就,几何变形可以很容易地解决。在这方面,需要更多地关注严重的外观差异。在计算机视觉研究领域,MMIM的代表性类型可能是红外和可见光(IR-VIS)图像对,除了跨光谱、跨时间(例如跨天气/季节、昼夜)和其他图像对。方式。
3.3.1可见光到红外光
视觉领域最流行的主题是可见光-红外图像匹配,由于两种图像类型提供的互补信息,它被广泛应用于各种视觉应用(例如图像融合)[13]。可见光图像捕获反射光,而红外图像可以捕获热辐射,从而从不同方面提供同一目标/场景的信息或属性。然而,由于成像传感器的差异,可见图像通常具有较高的空间分辨率和相当多的细节和明暗对比,但它们受光线和天气条件的影响很大。相比之下,由于基于热辐射的成像的性质,红外图像不受这些干扰的影响,但它们通常分辨率低且纹理差。因此,红外和可见光图像匹配仍然是一个需要进一步关注的悬而未决的问题。
(1)基于区域
红外图像的细节很少。因此,许多技术首先从两幅图像中提取共同结构,然后使用上述基于区域或特征的匹配方法或直接设计深度学习框架来处理红外-可见光图像配准问题。
为了提取一致的特征并更好地应用 NMI 进行基于区域的配准,Yu 等人。[439]通过灰度加权窗口策略从图像对中检测边缘特征,以减少NMI的联合熵和局部极值,从而提高配准性能。[440]中的另一种方法快速准确地识别眼角区域以进行发烧筛查。作者提出了一种基于区域的 VIS-IR 配准方法,首先将原始图像对转换为边缘图。然后,他们使用仿射和FFD来解释粗配准和精配准的几何关系。该方法通过最大化边缘图之间 MI 度量的整体相似性来优化。
(2)基于特征
为了对从同一建筑物的轻微视点变化拍摄的红外和可见光图像对进行配准,Hrkać 等人。[441]进行了一项实验,其中场景是两个图像中的角点都更加稳定。他们从这两张图像中检测到哈里斯角,然后使用简单的相似性变换来配准红外和可见建筑图像。他们选择部分豪斯多夫距离作为相似性度量。马等人。[133]提出了一种用于配准可见光和热红外人脸图像的非刚性管道。在本文中,提取每幅图像的边缘图,然后将其转换为点集作为表示图像的固有特征。随后,对点集配准问题的高斯场准则进行了分析和验证,并在再生核希尔伯特空间下生成了该准则的正则化形式,用于刚性和非刚性配准。在[442]中,基于相位一致图像的极值矩提取角点,并用log-Gabor滤波器描述。然后,利用描述符的相似性进行匹配步骤,然后使用RANSAC方法来确定可靠的点对应关系。此外,[443]中提出了一种快速视觉显着特征检测器以及描述符重新排列策略来配准可见光和红外图像对。
在建筑诊断中,需要将红外和可见光图像结合起来以获得更全面的信息。作者[444]通过分割边缘线首先提取四边形特征来配准这两种模态的图像对,并引入前向选择算法来识别用于变换模型估计的可靠特征对应。考虑到不同成像传感器在分辨率和外观方面的显着差异,Du 等人。[141]提出了一种用于角点特征描述和匹配的尺度不变PIIFD。,此外,还耦合了局部性保留约束以消除错误匹配,从而更好地估计贝叶斯框架下的仿射矩阵。在[178]中,作者首先使用形态梯度方法提取边缘,然后在边缘图上应用C_SIFT检测器进行不同点搜索和BRIEF进行描述,从而实现尺度和方向不变的匹配。
敏等人。[445]提出了用于非刚性红外和可见光图像配准的增强仿射变换(EAT)。他们首先从输入图像的边缘图中提取兴趣点,从而将图像配准转化为点集配准问题,其中他们使用SC来描述点集的局部结构以简化配准过程。在该方法中,需要变换模型、目标函数和优化方法来实现有希望的性能。根据局部特征估计最佳 EAT 模型以解释全局变形,并通过使用图像对之间潜在的真实对应关系来建立和简化基于高斯场的目标函数来指导匹配过程。还设计并应用了基于拟牛顿法的从粗到细的策略,用于从红外和可见光图像的点集确定最佳变换系数。为了应对非刚性配准,Min 等人提出了一种基于特征点的方法。[446],其中引入高斯加权 SC 来快速从图像对的边缘图中提取匹配点对。
(3)基于视频序列的方法
红外和可见光图像匹配方法的另一个主要类别是基于视频序列的。其想法是利用目标跟踪信息,从而将时域与图像域结合起来,以提高整体配准性能。比洛多等人。[447]提出了一种基于轨迹点的配准方法和一种新颖的误差函数,用于在图像融合之前对齐两个多传感器图像。作者根据运动物体的轨迹检测特征点,这些轨迹是使用背景和简单的跟踪策略获得的。然后,他们使用基于 RANSAC 的方法和新颖的配准标准来匹配轨迹点。韩等人。[448]通过对齐混合视觉特征(包括直线和兴趣点)来注册红外和可见图像对,这些特征分别用于估计全局透视变换和局部变换适应。在[449]中,引入了一种策略,该策略使用噪声多边形顶点的局部形状进行帧对匹配,然后估计单应性变换以进行VIS-IR视频配准。为了注册红外和可见视频的序列,提出了一个集成的全局到局部框架[450]来解决这个动态场景匹配问题。两个序列的总体 MI 测量针对全局单应性估计进行了优化,并且执行帧到帧配准以细化每个帧对的局部变换。此外,使用平滑策略来强制时域中的时间一致性,从而平滑局部单应性。
类似地,结合运动和特征信息,提出了一种用于 VIS-IR 视频配准的从粗到细的框架[451]。通过曲率尺度空间关键点提取捕获的运动信息用于估计全局尺度和旋转以进行粗匹配。兴趣点被重新定位并与标准化描述符相匹配,以及基于一致性检查的不匹配消除策略以进行精细配准。这些描述符是根据边缘方向的直方图创建的。为了通过时空关联来配准平面可见光-红外图像序列,Zhao 等人。[149]绕过了特征提取的使用,同时首先使用运动矢量分布作为描述符来粗略地配准帧对,以呈现前景轮廓的时间运动信息。精细匹配阶段通过FAST角点匹配和相似变换估计来执行。[452]中提出的方法通过分割显着目标并匹配斑点特征来注册非平面可见光-红外帧对。
(4)基于学习的方法
在复杂的场景中,检测可匹配的特征或直接从红外和可见光图像中训练深度网络并不容易。王等人。[453]提出了一种两阶段对抗网络,其中包括域传输网络和几何变换器模块,以跨不同模态映射图像并获得精致的扭曲图像。巴鲁克等人。[454]旨在一步联合检测和匹配兴趣特征点。在该方法中,作者引入了一种由连体 CNN 和双非权重共享 CNN 组成的混合 CNN 架构,该架构可以很好地捕获和利用多模态图像块中的联合和不相交线索。
考虑到传统非线性优化流程中手工相似性测量的缺点,[455]中提出了一种无监督程序,以在两种给定模态上同时训练图像到图像翻译网络和配准网络。这种学习的翻译允许将一个图像域转移到另一图像,然后使用简单可靠的单模态度量来训练配准网络。鼓励生成器保留几何信息的 GAN 框架应用于平移任务,然后进行修改以生成平滑且准确的空间变换,从而完成配准任务。
(5)其他
考虑到图像融合质量不仅取决于算法的质量,还取决于所需图像配准算法的结果,[456]提出了一种称为 MIRF 的组合方法,它可以对基于区域的图像配准和融合多模态图像,配准和基于对象的图像融合。它是通过双树复小波变换来实现的。另一个同时解决注册和融合问题的集成框架。[457]中介绍了热视频和可见视频的人员跟踪。配准涉及通过使用 RANSAC 的轨迹特征匹配来估计仿射矩阵来最大化图像对的重叠区域。[23] 中提出了一种针对具有混合特征的红外和可见光图像的非刚性配准方法,并将其集成到 3D 重建方案中,以获得信息更丰富、更完整的 3D 模型。在[458]中,作者引入了一种长波红外和可见光光谱图像匹配方法来从这两种模式的图像中检测物体。该方法基于边缘检测和二元寺庙匹配策略,然后使用局部模糊阈值来识别高相似度的对象。
3.3.2 跨光谱图像
跨光谱图像匹配定义为从不同光谱带获取目标图像,例如多光谱和可见光到近红外图像匹配。
在多光谱匹配中,考虑到传统使用的测量指标(例如 SSD 或 SAD)计算效率高,但在多光谱图像对齐中表现不佳,Cao 等人。[459]提出了一种结构一致性增强(SCB)变换来增强多光谱/模态图像配准问题中的结构相似性。这种方法可以帮助避免由于成像设备移动或交替而导致光谱带之间未对准而导致的光谱信息失真。在[460]中,作者提出了RegiNet,它使用参考图像的梯度图来指导目标图像进行配准。该方法通过结构损失进行了优化,结构损失迫使网络有效地从参考图像中捕获梯度信息。实验部分使用PSNR和结构相似性(SSIM)作为评价指标。
另一种称为 NIR 的光谱图像可用于以非破坏性且有效的方式识别视觉目标的化学成分。许多研究人员研究近红外和可见光图像之间的匹配问题,并提出了有意义的技术。为了解决近红外和可见人脸图像匹配中的遮挡和异构问题,Yi 等人。[461]引入了边缘增强滤波来捕获不同模态图像对的共同结构,并对分割的图像块进行模板匹配。[462]旨在开发一种新的解决方案来满足基于人脸的生物识别的准确性要求。在分析近红外和可见人脸图像特性的基础上,从近红外-可见人脸对中学习近红外和可见人脸之间的相关性机制,然后使用学习到的相关性来评估相似性,以指导不同光照下的人脸配准,状况。
3.3.3 跨时间图像
另一种类型的多模态涉及由于时间变化而导致的外观变化,例如白天到黑夜、跨天气或跨季节。在这种情况下,由于图像对中共同细节和结构的消失,外观差异比不同传感器引起的外观差异更显着。从白天和晚上捕获的图像对可能在夜间图像中具有较少的细节,但在白天图像中具有更多的细节。幸运的是,建筑物或树木的轮廓在白天和夜间图像中明显共存,或者夜间图像中的纹理细节是由人造光揭示的。对于跨天气或跨季节的图像匹配,同一场景的外观会发生很大的变化,例如雨天和晴天、夏天和冬天的雪天。这些方法对于变化检测、图像定位和地点识别的应用具有重要意义。
为了研究视觉应用的良好跨时间匹配,Shrivastava 等人。[8]研究了不同领域图像之间的视觉相似性,例如不同季节拍摄的照片、绘画和素描。继[463]中的工作之后,作者假设图像的重要部分是那些在视觉世界中更独特或罕见的部分。受到经典的基于强度恒定的图像对齐方法和现代 GAN 技术成功的启发,Zhou 等人。[6]提出了一种跨天气图像对齐的潜在生成模型。在该方法中,图像配准任务被公式化为具有基于强度恒定性和图像流形属性的使用的潜在编码过程的约束变形流估计问题。
至于与白天和夜晚等不同照明条件的匹配,罗等人。[5]通过将局部块相似性约束与检测点的空间几何约束相结合,提出了一种可训练的点描述符,实现了多模态图像对的良好匹配性能。为了检测由不同天气和照明条件引起的外观剧烈变化的可重复点特征,Verdie 等人。[182]通过使用手工制作的 DoG 进行训练集收集,然后训练通用回归器以生成特征得分图,从对齐的图像对训练多个分段线性回归模型。关键点被识别为具有非极大值抑制的该图的局部最大值。
3.3.4 其他
除了上述用于匹配或配准的模态对之外,计算机视觉界还研究了由数据类型或域引起的非线性强度方差。这种方法通常表现为图像-绘画-素描匹配、图像-点云匹配、语义匹配以及图像到文本的跨域匹配。
真实图像与绘画或草图的匹配是一项具有挑战性的任务,不仅因为外观差异很大,而且因为非刚性变形。早期的相关工作包括登记在不同季节拍摄的照片、绘画和素描。什里瓦斯塔瓦等人。[8]通过定义不同领域的图像之间的视觉相似性提出了一项有趣的工作。Aubry 等人提出的方法。[9],开发了一种新的复杂 3D 场景的紧凑表示。场景的 3D 模型由一小组有区别的视觉元素表示,这些元素是从渲染视图中自动学习的。
语义匹配表示具有不同目标但相似属性的输入图像对,例如狗和猫。这个问题引起了越来越多的关注,研究人员使用深度技术来理解语义相似性。蔡等人。[231]提出了UCN,通过使用深度度量学习来直接学习保留几何或语义相似性以进行语义匹配的特征空间。Rocco 等人提出了另一种称为 NCN 的方法。[464]。在这种方法中,作者使用半局部约束训练了一个端到端的深层架构,以创建可靠的特征对应。其他类似的语义匹配方法包括[232-235]。
另一个有趣的研究课题是真实图像和文本之间不同领域的匹配,这一直是近年来的热门话题。我们建议感兴趣的读者参考[10-12]进行详细阅读。
3.4 总结
MMIM 对医疗、遥感和计算机视觉研究领域的不同成像设备或条件有广泛的分类。不同模式中的方法通常偏向于特定类型的注册管道。例如,大多数医学图像可以在基于区域的框架下更好地配准,因为这些图像通常具有较大的重叠、轻微的图像变形和低分辨率。然而,由于两个视网膜图像中存在不同的血管结构,基于特征的策略可以实现更准确的配准结果。对于遥感和计算机视觉研究,用于匹配的图像通常具有高分辨率和大变换;,因此,基于区域的框架会导致精度低和计算负担高。因此,需要设计一种能够同时处理所有类型模态的图像匹配问题以满足不同应用需求的通用方法。为此,齐默等人。[466]试图开发一种基于图像图拉普拉斯交换律的通用度量,以指导合成数据、可见光到红外数据和医学数据的MMIR优化。上面回顾的典型方法总结在表1 2 3中,分别对应于医学、遥感和计算机视觉领域。表中列出了模态对、方法分类、转换模型、测试图像的场景或目标以及每种方法的核心思想。在每个表中,我们使用“-”来表示其文献中无法查询到的信息。为了更好地查看,我们使用了许多缩写,可以很容易地从正文中推断出这些缩写。
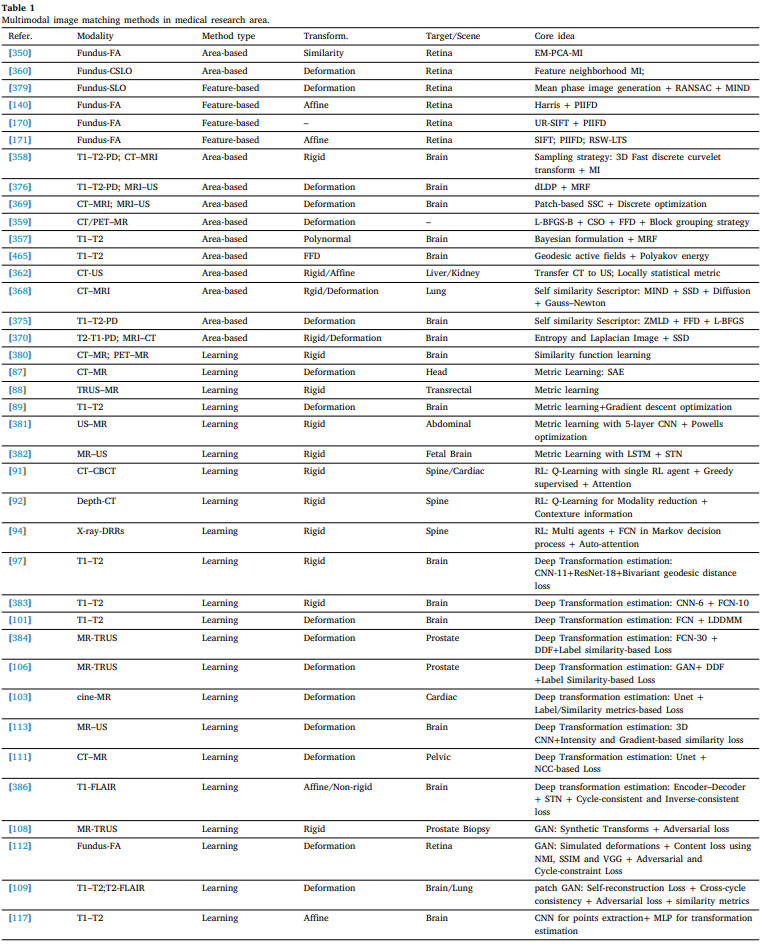
表1医学研究领域的多模态图像匹配方法。
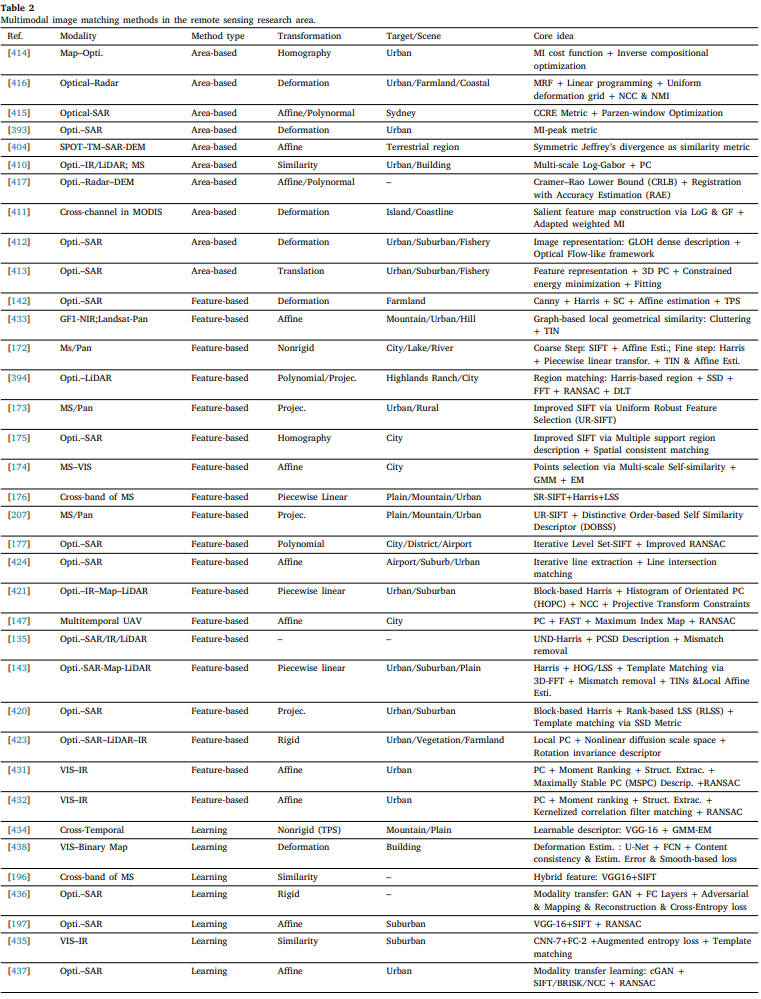
表2遥感研究区多模态图像匹配方法。
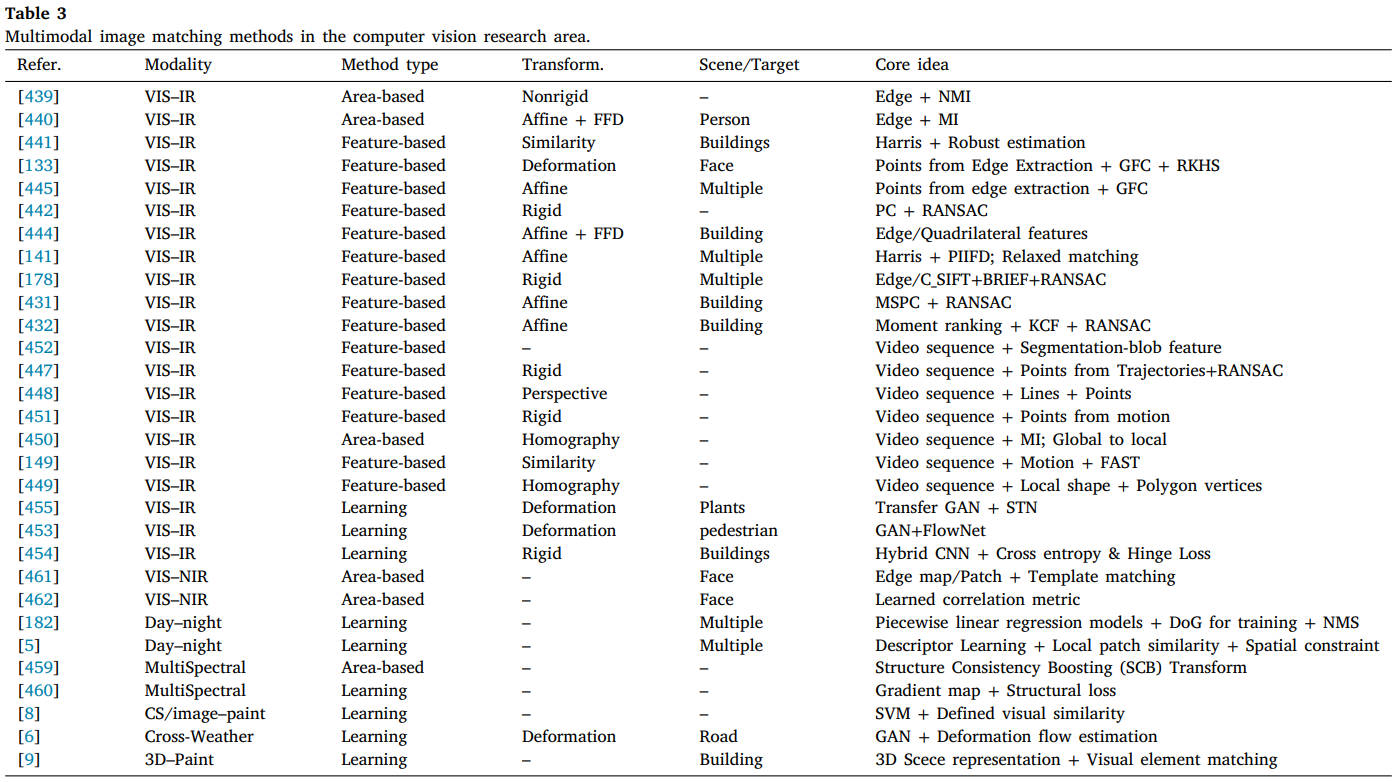
表3 计算机视觉研究领域的多模态图像匹配方法。
4 实验评估
在过去的几十年里,MMIM 在医学、遥感和计算机视觉领域引起了越来越多的关注,成为图像融合、图像定位、目标识别和跟踪等许多高级应用的先决程序。因此,已经开发了许多不同的匹配方法来解决两个或更多个多模态图像的非线性强度方差和几何变形。因此,这些典型的、最近开发的方法需要进行定性和定量比较,以确定它们的优点和缺点。
然而,由于不同研究领域的多模态图像对具有独特性,据我们所知,还没有此类文献对医学、遥感和计算机视觉领域的 MMIM 方法进行详细的全面综述。现有的相关调查通常集中于单一研究领域的通用方法,无论是一般医学图像配准、视觉图像匹配还是基于应用的审查。许多调查论文对方法介绍和分类进行了综合分析,但忽视了实际的实验评估。研究人员也很难在公共 MMIM 上以统一标准直接评估他们的技术。
在本次调查中,我们尽最大努力从公共网站收集多模式图像对,以确保涵盖研究人员使用的所有典型模式。接下来,我们将介绍构建的MMIM数据集的实验细节、评价指标以及典型方法在特征检测、特征描述与匹配、失配去除和图像配准方面的评价性能。
4.1 构建评价数据库
为了满足我们的实验评估要求并为未来的研究构建统一的标准,我们收集了一个完整的数据库,涵盖医学、遥感和计算机视觉领域的所有典型多模态图像对。收集的数据库包含18个模态对:(1)医学研究数据库包括MR T1、T2和Pd加权图像、MRI-PET、SPECT-CT以及不同成像方法的视网膜图像的交叉匹配;(2)遥感研究数据库包含无人机跨季节影像对、光学昼夜影像对、LiDAR深度光学影像对、红外光学影像对、地图光学影像对、光学跨时空影像对、SAR光学影像对;(3)计算机视觉相关研究数据库由VIS-IR图像对、可见光-NIR、可见光跨季节、昼夜、图像-油漆图像对组成。我们总共创建了 164 个图像对用于实验评估。下面详细介绍我们收集的数据库及其来源
- BrainWeb [467](https://brainweb.bic.mni.mcgill.ca/brainweb/).BrainWeb 也称为模拟大脑数据库(SBD),其中包含由 MRI 模拟器产生的一组真实的 MRI 数据体。使用三个序列(T1、T2 和 PD 加权)和各种切片厚度、噪声水平和不均匀强度水平来模拟完整的 3D 体积。在此数据库的基础上,我们构建了 T1、T2 和 Pd 加权 MR 图像作为测试数据的一部分。
- Atlas(Atlas: http://www.med.harvard.edu/aanlib/home.html.). 该数据库由真实的 CT、MRI、PET 和 SPECT 脑体积组成,我们从中选择 10 个 MRI-PET 和 SPECT-CT 切片对。对于每个图像对,我们使用随机仿射矩阵扭曲移动图像,从而刺激几何变形。
- 视网膜 [330]。该数据库由 65 个经过非刚性变换的视网膜图像对组成,这些图像在不同的血管造影技术下成像。在这个数据库中,对于一些有轻微变形的图像对,我们可以使用仿射模型来解释它们的几何变换,从而将其保留为我们用于特征检测和描述的测试数据。
- CoFSM.(CoFSM: https://skyearth.org/publication/project/CoFSM/.) 这是一个新发布的多模态遥感图像数据库,由 6 种模态对组成,即光学-光学(跨时空)、红外-光学、深度-光学、地图光学、SAR-光学和夜间,-天。这些原始图像对帮助我们构建遥感社区的测试数据。还收集了720云平台(720Yun: https://720yun.com/.)的几对无人机跨季节图像对进行实验评估。
- 可见光-红外 VIS-IR(VIS–IR: https://www.flir.com/oem/adas/adas-dataset-form/.)。我们自己收集了这个 VIS-IR 子数据集。包含道路、车辆、行人等丰富的道路场景。这些图像是 FLIR 视频中具有高度代表性的场景。5 从这些图像对中,我们还构建了一个可用的图像融合数据集,(VIS–IR Fusion: https://github.com/jiayi-ma/RoadScene.)该数据集通过使用我们手动标记的地标和计算的仿射矩阵进行注册。
- VIS-NIR [468].(VIS–NIR: https://ivrlwww.epfl.ch/supplementary_material/cvpr11/index.html.)该数据集包含 9 个类别的 477 张图像,这些图像是使用带有可见光和 NIR 滤光片的改良单反相机单独曝光拍摄的。场景类别包括乡村、田野、森林、室内、山地、老建筑、街道、城市和水。从每个类别中,我们选择几个典型的原始图像对作为我们的测试数据。对于每个图像对,我们同样使用随机仿射矩阵扭曲移动图像,从而刺激几何变形。
- WxBS [469].(WxBS: https://pgram.com/dataset/cmp-wxbs-dataset/home/.) 宽基线数据集由 31 个图像对组成,同时结合了几何、照明和红外-可见光等多个干扰因素。每个图像对都已经提供了真正匹配的地标(点)用于评估,我们从中选择经历昼夜和跨季节变化的地标作为我们评估数据集的一部分。
- Vision Cross-Weather/Season.(Vision Cross-Weather/Season: https://www.visuallocalization.net/datasets/.)该数据集包含大量经历昼夜、天气或季节变化的配对图像,最初用于地点识别或视觉定位。按照周等人的描述。在[6]中,我们从费城通勤道路场景(PRS)数据集、诺德兰铁路场景(NRS)数据集[470]和RobotCar Seasons(RCS)数据集[471]中选择一些代表性图像对作为测试数据,用于跨天气或季节图像匹配。
- image–paint [8].(image–paint: http://graphics.cs.cmu.edu/projects/crossDomainMatching/)在这个数据集中,作者最初为跨域图像匹配提供了丰富类型的多模态图像对。我们使用绘画查询以及从互联网收集的一些查询作为我们的测试数据。使用的图像是 8 个地点或目标,包括伦敦塔桥、悉尼歌剧院和凯旋门。每个目标都包含真实的图像、草图、绘画或图画。
从这些收集的原始图像对中,我们为每个图像(WxBS 数据集除外)手动标记 15 到 20 个匹配的地标(即点位置),这可用于根据这些匹配的地标的距离来评估配准精度。在我们的实验中,我们首先尽力手动标记这些分散且独特的匹配地标,以估计仿射矩阵以最好地配准每个图像对而没有任何明显的未对准,然后保留这些地标和仿射参数作为我们的 ground truth 。特别地,我们使用Matlab工具箱“cp2tform”估计基于直接线性变换(DLT)的仿射参数。根据每个图像对的变换矩阵,我们可以知道哪两个点在固定和移动中匹配,图像,并判断特征描述符创建的匹配点是否正确。而对于非刚性情况或仿射模型无法再解释几何变换,我们只是将这些匹配的地标保留为基本事实,并且仅将它们用于,图像配准测试。事实上,非刚性案例的假定匹配的正确性可以一一手动标记,如参考文献[2,333]中执行的那样。并且配准是在TPS等非刚性模型下进行的[336] ,]. 所有收集到的数据及其真实地标以及变换矩阵均已集成并可在 11 处获取(https://github.com/StaRainJ/Multi-modality-image-matching-database-metrics-methods)。该数据库中的一些选定的原始图像对如图 4 所示。
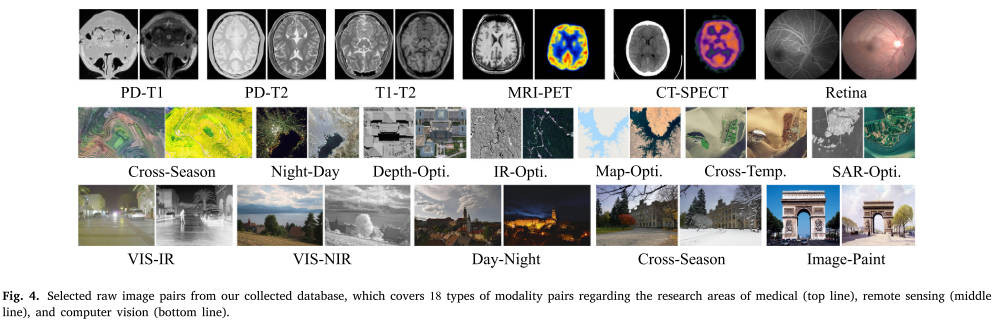
图4。从我们收集的数据库中选择原始图像对,其中包括18种模态对,涉及医学(上),遥感(中)和计算机视觉(下)的研究领域。
4.2 特征检测评估
基于我们收集的多模态图像数据,并借助这些给定的变换矩阵,我们首先进行特征检测的性能比较。考虑到图像匹配方面的现有文献[129,236],关键点检测任务中的性能评估常用三个指标,即重复性repeatability(Rep.)、熵entropy(En.)和效率或运行时间runtime(RT)。
假设特征检测器分别从固定图像和运动图像中提取 𝑀 和 𝑁 关键点。因此,检测到的点数 (DPN) 定义为 𝐷𝑃𝑁 = 𝑀 + 𝑁。可重复点数(RPN)被确定为现实世界中具有相同位置的可匹配点的数量(在两个图像中同时提取),这些点是通过我们给定的 ground truth 变换矩阵通过将这些点变换为运动中来测量的。然后在像素距离阈值(在我们的实验中,阈值等于 5)内搜索固定图像中最近的点。根据这些定义,可重复性可以定义为

熵可以在空间分布方面评估检测器对描述符的影响,它衡量检测到的关键点在图像中是否充分分布。该指标的高值表明提取的点由于其非聚集特性而更容易被局部描述符区分[472]。按照[472,473]中的说明,我们首先创建特征点的 2𝐷 均匀间隔的分箱,并将每个分箱的中心表示为 𝑝 = (𝑥, 𝑦)。每个点对给定 bin 的贡献根据其到 bin 中心的距离通过高斯加权。位置 𝑝 处的 bin 可以用 计算,其中 𝑚 是检测到的兴趣点的全套 𝑀 中的关键点,𝐺,是一个高斯函数。添加常数 以使所有 bin 的总和等于 1。从这些 bin 中,我们可以得到

在本实验中,我们选择了12个典型的检测器来代表角点特征、斑点特征和可学习特征的检测。比较的方法包括 Harris [118]、FAST [144] 和 BRISK [209]。我们使用三个角点检测器和相位一致性图的输入,正如许多其他研究人员[147,148,432](即 PC-Harris、PC-FAST 和 PC-BRISK)所执行的那样。用于比较的斑点特征检测器是 DoG (SIFT) [121]、SURF [122] 和 MSER [128]。对于基于学习的检测器,我们选择 TILDE [182]、LFnet [188]、SuperPoint [185] 进行评估。Harris、FAST、BRISK 和 SURF 直接使用 MATLAB 工具箱实现,其中我们通过选择顶部响应将每个图像中检测到的特征数量限制在 2𝑘 内。DoG (SIFT) 和 MSER 是用 VLFeat ToolBox12 [474] (https://www.vlfeat.org/)实现的。我们直接使用作者的源代码在我们的评估中应用这些基于学习的检测器。所有手工制作的检测器均在配备 4.0 GHz Intel Core i7-6700K CPU、16 GB 内存的台式机上执行。深度方法在具有 2.0 GHz Intel Xeon CPU、128 GB 内存的服务器上执行。
代表性特征检测器在典型多模态图像对上的定性结果如图 5 6 7所示。对于每个图像对,阈值在 3 和 5 像素以下的重复点分别用蓝色和绿色星表示,而距离超过 5 像素的不可匹配点用红点表示。

图5。医学研究领域典型多模态图像对的12个特征检测器定性结果。(蓝色=阈值为3像素的重复点,绿色=阈值为5像素的重复点,红色=不匹配点)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)

图6。12个特征检测器在遥感研究领域典型多模态图像对上的定性结果。(蓝色=阈值为3像素的重复点,绿色=阈值为5像素的重复点,红色=不匹配点)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)
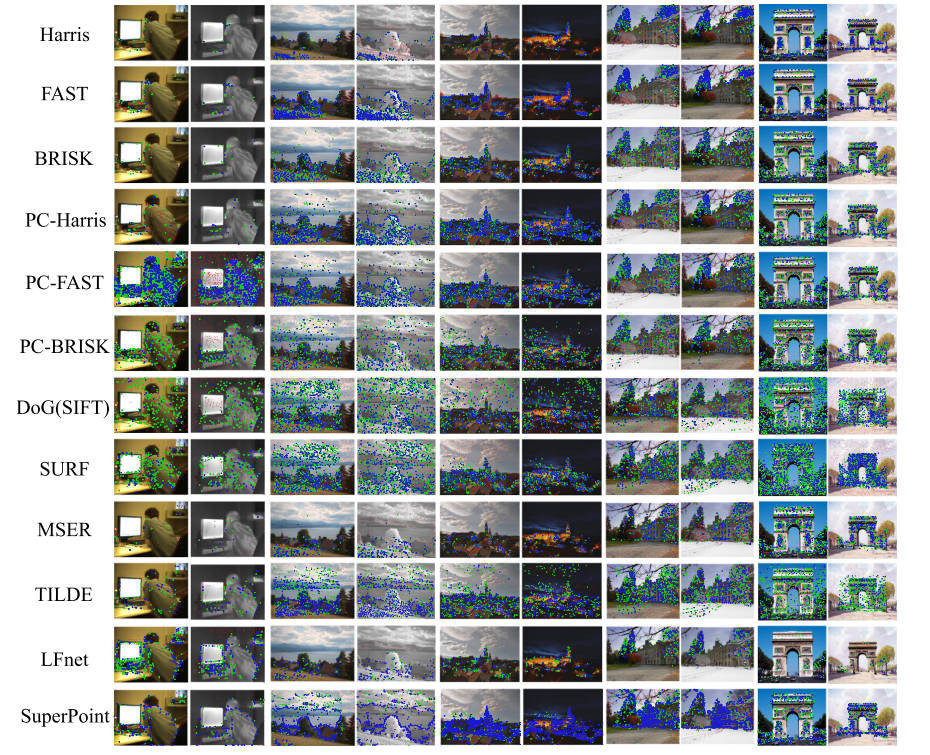
图7。计算机视觉研究领域12个特征检测器对典型多模态图像对的定性结果。(蓝色=阈值为3像素的重复点,绿色=阈值为5像素的重复点,红色=不匹配点)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)
18个数据集的所有定量结果如表4-9所示,分为医学、遥感和计算机视觉社区三个部分。对于每个数据集,每种方法的平均DPN、RPN、Rep.(%)、En.、RT(ms)都被描述在表上。表的末尾还显示了这三个研究团体的整体检测性能,第一、第二和第三最佳结果分别以粗体红色、绿色和蓝色表示。
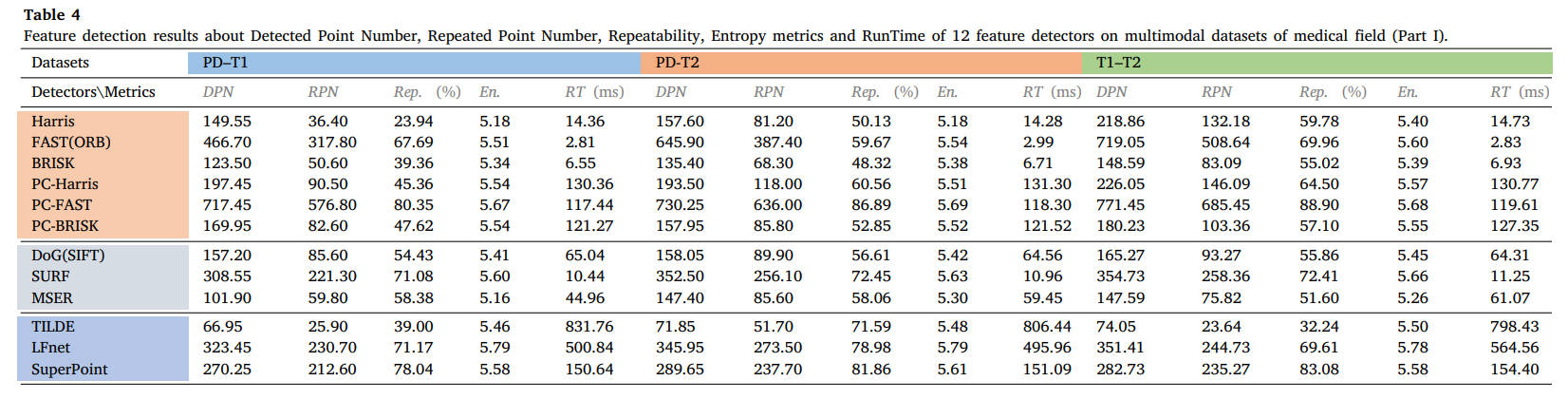
表4 12种特征检测器在医学领域多模态数据集上的检测点数、重复点数、可重复性、熵指标和运行时间特征检测结果(第一部分)。
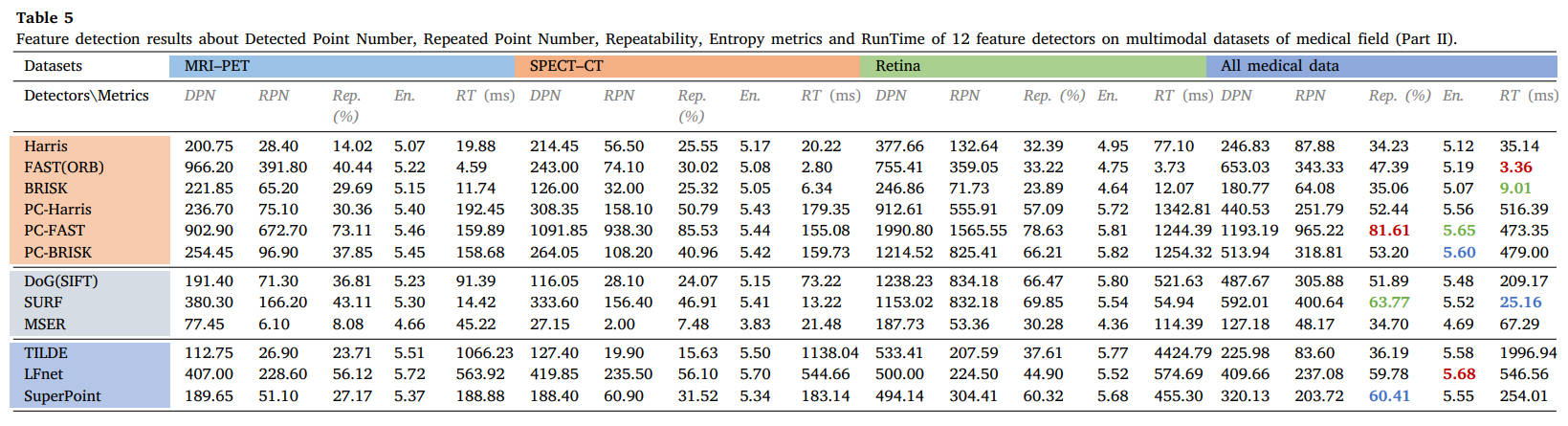
表5 12种特征检测器在医学领域多模态数据集上的检测点数、重复点数、可重复性、熵指标和运行时间特征检测结果(第二部分)。
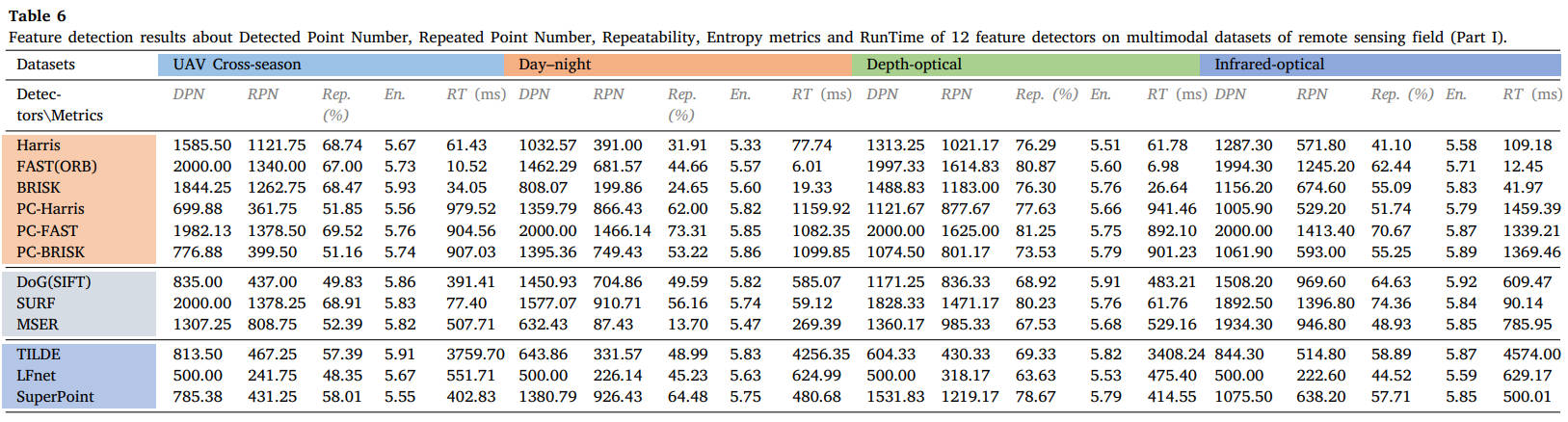
表6 12种特征检测器在遥感领域多模态数据集上的特征检测结果(第一部分):检测点数、重复点数、可重复性、熵指标和运行时间。
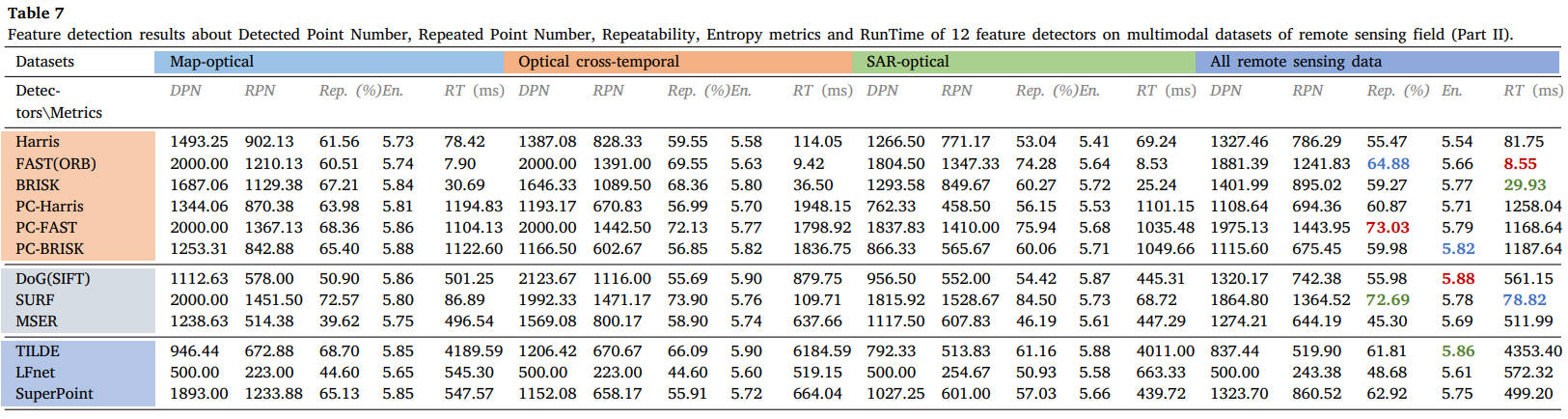
表7 12种特征检测器在遥感领域多模态数据集上的特征检测结果(第二部分):检测点数、重复点数、可重复性、熵指标和运行时间。
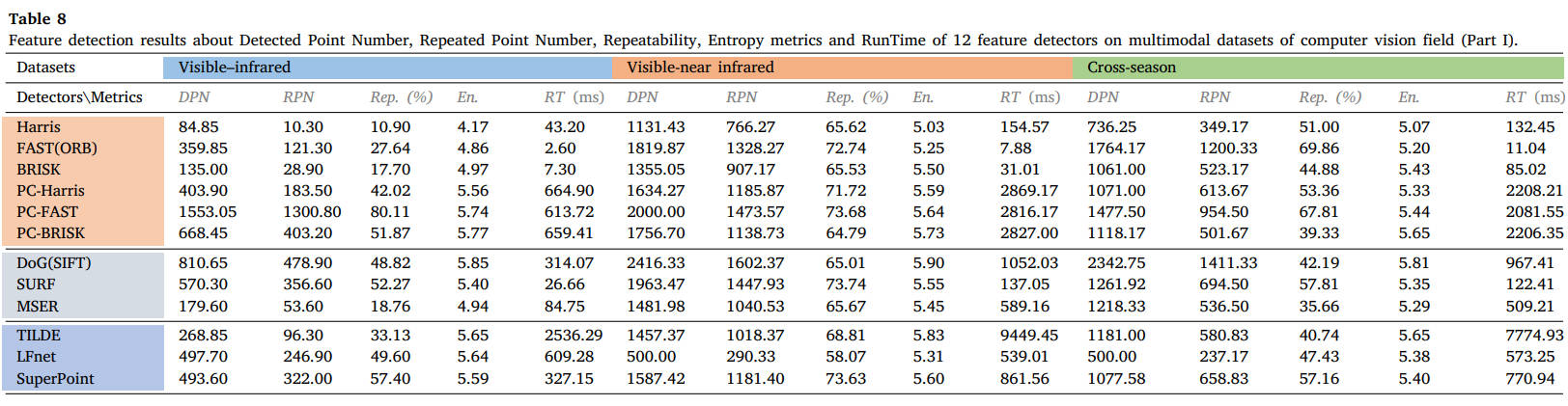
表8 12种特征检测器在计算机视觉领域多模态数据集上的检测点数、重复点数、可重复性、熵指标和运行时间特征检测结果(第一部分)。
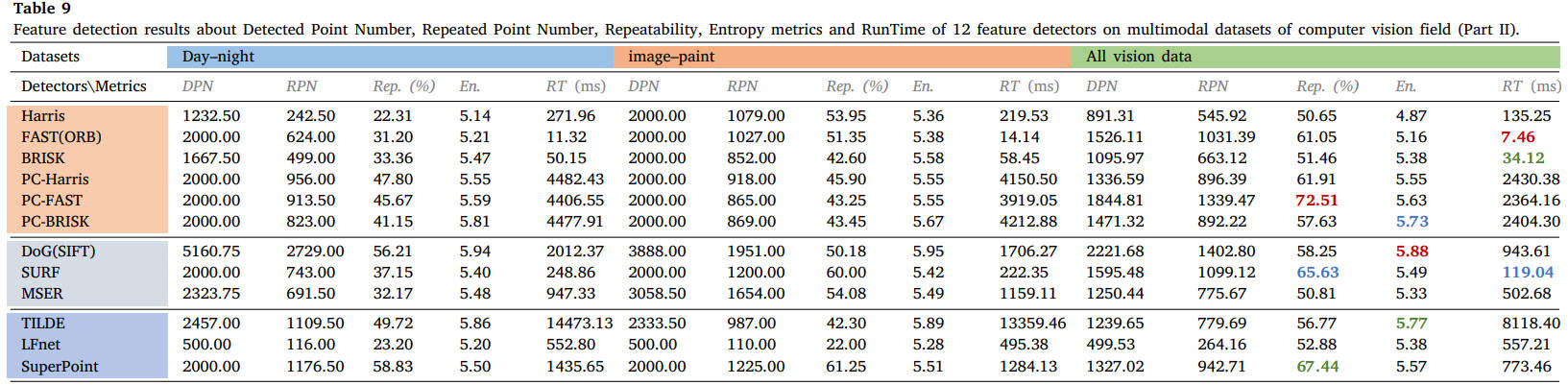
表9 12种特征检测器在计算机视觉领域多模态数据集上的检测点数、重复点数、可重复性、熵指标和运行时间特征检测结果(第二部分)。
从结果中我们可以看出,FAST和SURF检测器在MMIM中在可重复性和执行效率方面仍然可以实现有希望的检测性能。PC地图的结合可以极大地提高角点检测器的性能,但需要额外的计算负担。对于基于学习的方法,SuperPoint能够保持良好的泛化能力。读者可以参考表格获取更详细的结果,或使用我们的公共数据集和 ground truth 测试其他检测器。
4.3 对特征描述的评估
在这一部分中,我们将在这些多模态图像数据集上测试几个代表性的特征描述符。正如[472]中介绍的,主要使用三个指标进行评估,即匹配分数、精度和召回率。在评估之前,假设我们已经获得了由特征检测器和描述符组合创建的一组假定匹配,其中和是固定和移动中兴趣点的像素坐标,分别使用我们在像素距离阈值 内的真实变换来识别正确的匹配集 ,即 ,其中 和 表示真实几何变换,在我们的实验中, 等于 5。因此,推定匹配数 (PMN) 被定义为,假定的匹配集,即 。正确匹配数(CMN)定义为正确匹配集的基数,即 。基于这些定义,匹配分数(MS)可以计算为属于正确匹配的特征数量与所有检测到的特征数量之间的比率。精度,也称为内点率,定义了假定匹配集中正确匹配的数量,其计算公式为

召回率量化了通过描述符匹配实际找到了多少真实的正确匹配。受[472]的启发,我们将召回率定义为属于正确匹配的特征数量与所有可重复特征的数量之间的比率。整个特征检测和描述过程中的运行时间(RT)用于评估执行效率。
在本实验中,我们选择了计算机视觉领域中三个著名的经典特征匹配器进行比较,即SIFT [121]、SURF [122]和ORB [120],以及两个深度匹配器,即SuperPoint [ ,185]和LFnet[188]。两个广泛使用的针对多模态图像的描述符称为PIIFD [140](仅对医学数据进行测试)和RIFT [148]也用于比较。检测实验中测得的五个性能最好的检测器与PIIFD和RIFT结合使用进行评估。所选检测器有 SURF、PC-FAST、PC-BRISK、TILDE 和 SuperPoint。,与特征检测实验类似,SIFT是用VLFeat ToolBox实现的,深层方法是用作者自己提供的源代码实现的。ORB由OpenCV库[475]实现,其他由MATLAB Toolbox实现。所有手工方法均在具有 4.0 GHz Intel Core i7-6700K CPU、16 GB 内存的台式机上执行,而深度方法则在具有 2.0 GHz Intel Xeon CPU、128 GB 内存的服务器上执行。
典型多模态图像对上代表性特征描述符匹配方法的定性结果如图 8,9,10所示. 对于每个图像对,阈值在 3 和 5 个像素以下的正确匹配分别用蓝线和绿线表示,而距离超过 5 个像素的错误匹配则用红线表示。
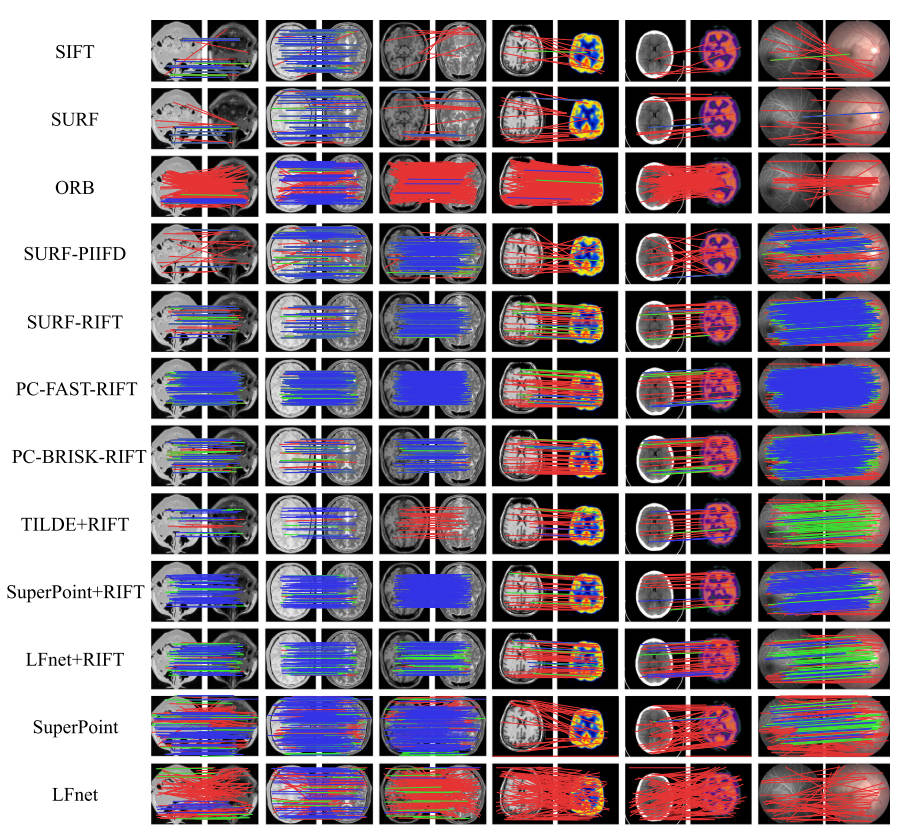
图8。医学研究领域典型多模态图像对的12种定性描述符匹配结果(蓝色=阈值为3像素的正确匹配,绿色=阈值为5像素的正确匹配,红色=不正确匹配)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)

图9。10种方法对遥感研究区典型多模态图像对的定性描述符匹配结果(蓝色=阈值为3像素的正确匹配,绿色=阈值为5像素的正确匹配,红色=不正确匹配)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)

图10。计算机视觉研究领域中典型多模态图像对的11种定性描述符匹配结果。(蓝色=阈值为3像素的正确匹配,绿色=阈值为5像素的正确匹配,红色=不正确匹配)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)
表10-15列出了18个数据集特征描述符匹配的所有定量结果,分为医学、遥感和计算机视觉界三个部分。对于每个数据集,每个方法的平均正确匹配数、假定匹配数、匹配分数 (%)、精度 (%)、召回率 (%) 和运行时间 (ms) 均列在这些表中。这三个研究团体的总体描述符匹配性能显示在表的末尾。第一、第二和第三最佳结果分别以粗体红色、绿色和蓝色表示。
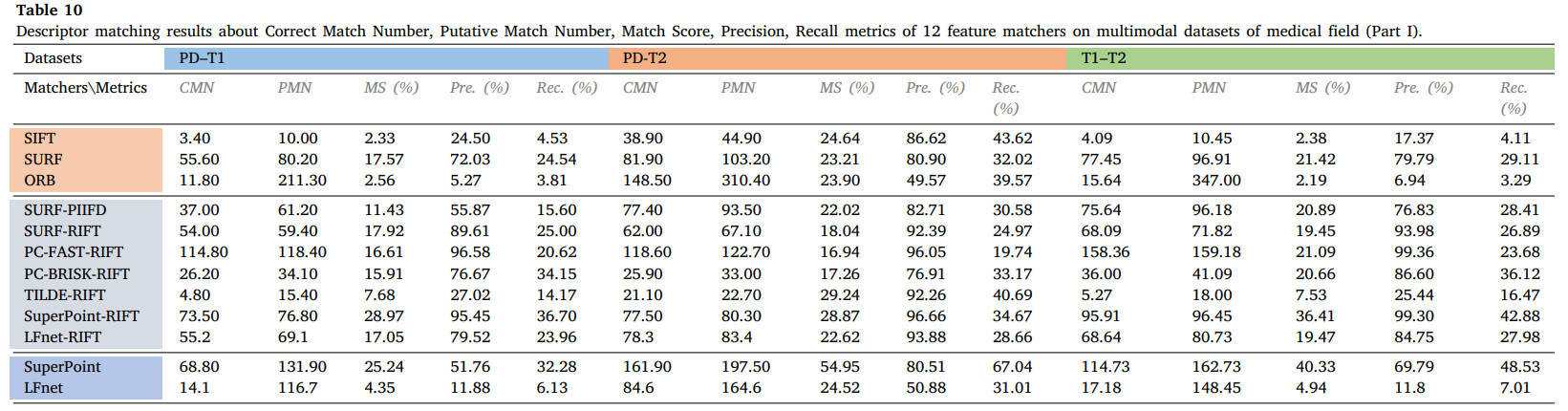
表10 12个特征匹配器在医学领域多模态数据集上的描述符匹配结果(第一部分):正确匹配数、假定匹配数、匹配得分、精度、召回率。
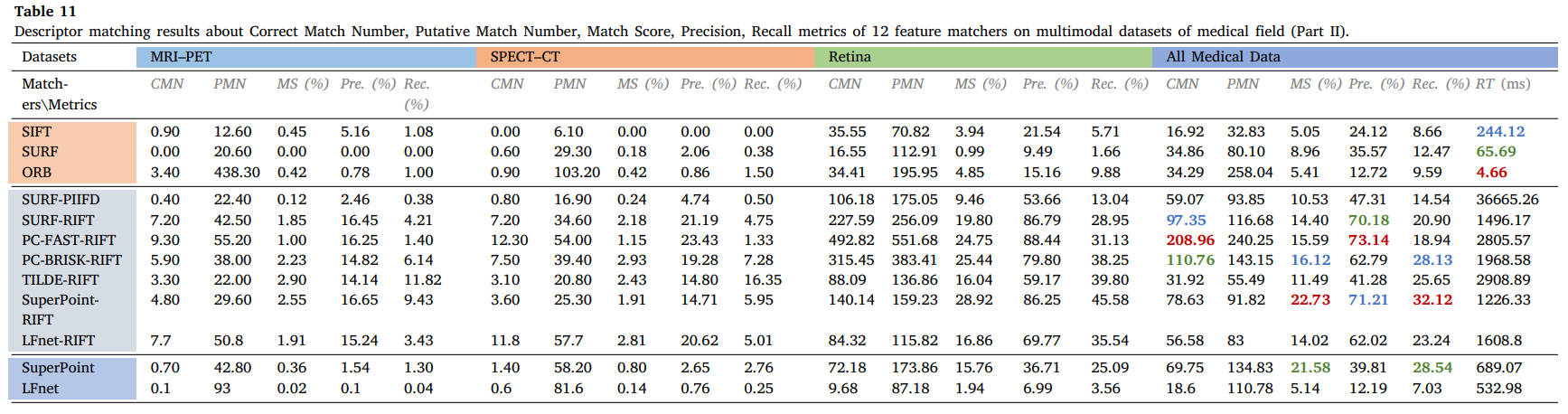
表11 12个特征匹配器在医学领域多模态数据集上的描述符匹配结果(第二部分):正确匹配数、假定匹配数、匹配得分、精度、召回率。
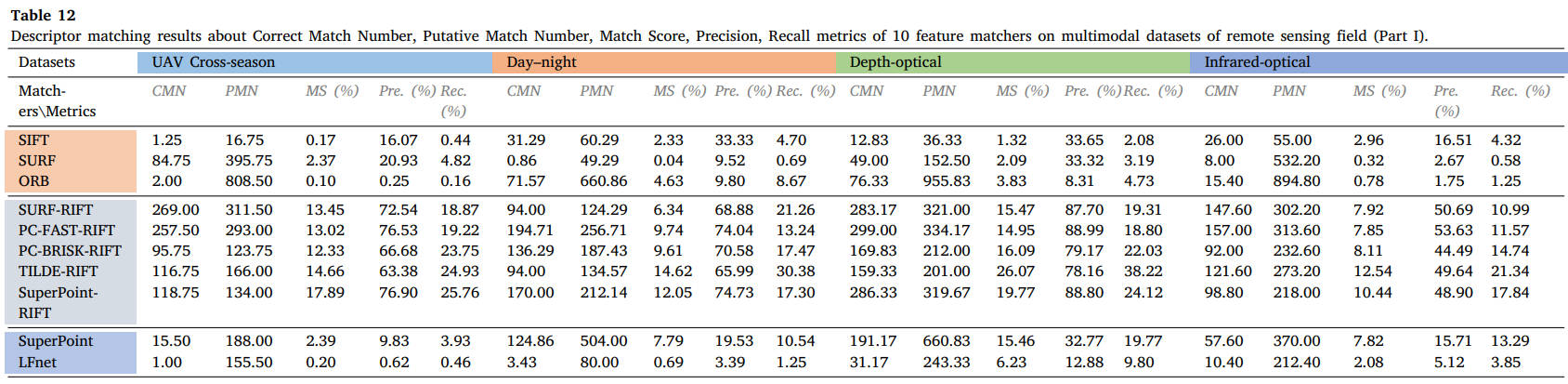
表12 10个特征匹配器在遥感领域多模态数据集上的描述符匹配结果(第一部分):正确匹配数、假定匹配数、匹配得分、精度、召回率。
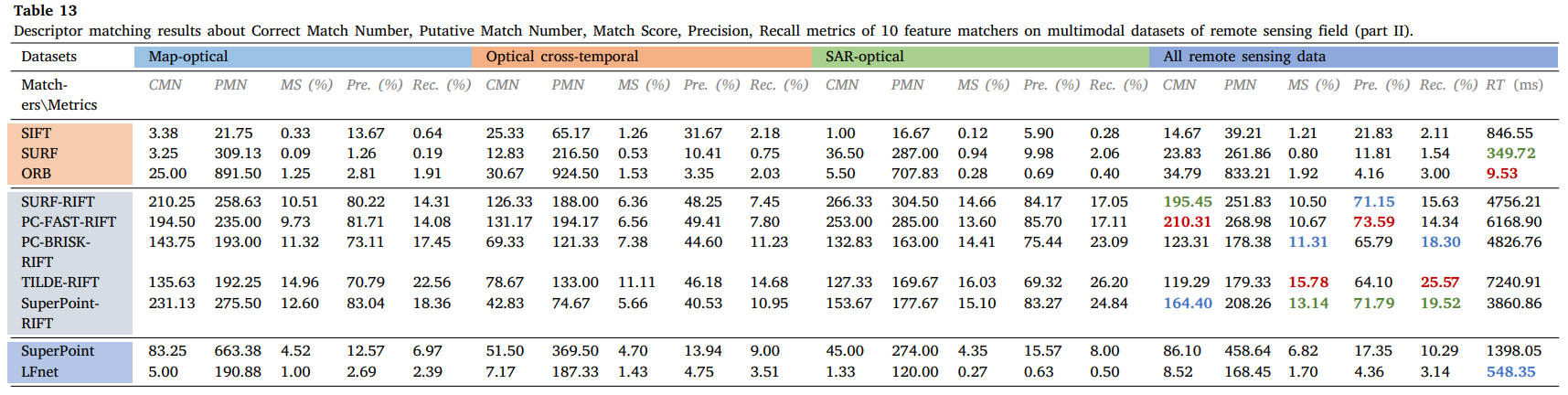
表13 10个特征匹配器在遥感领域多模态数据集上的描述符匹配结果(第二部分):正确匹配数、假定匹配数、匹配得分、精度、召回率。
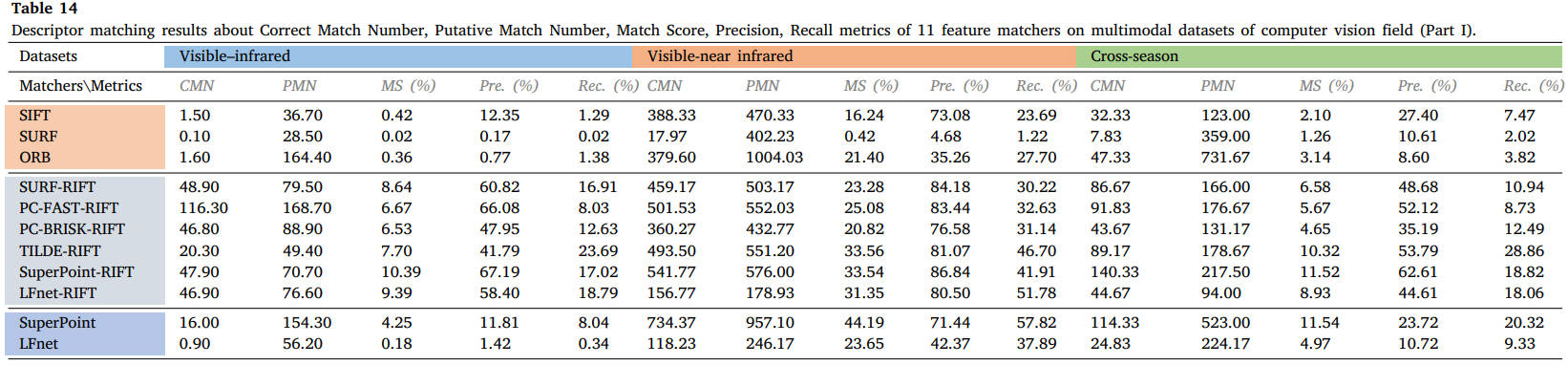
表14 11个特征匹配器在计算机视觉领域多模态数据集上的描述符匹配结果(第一部分):正确匹配数、假定匹配数、匹配分数、精度、召回率。
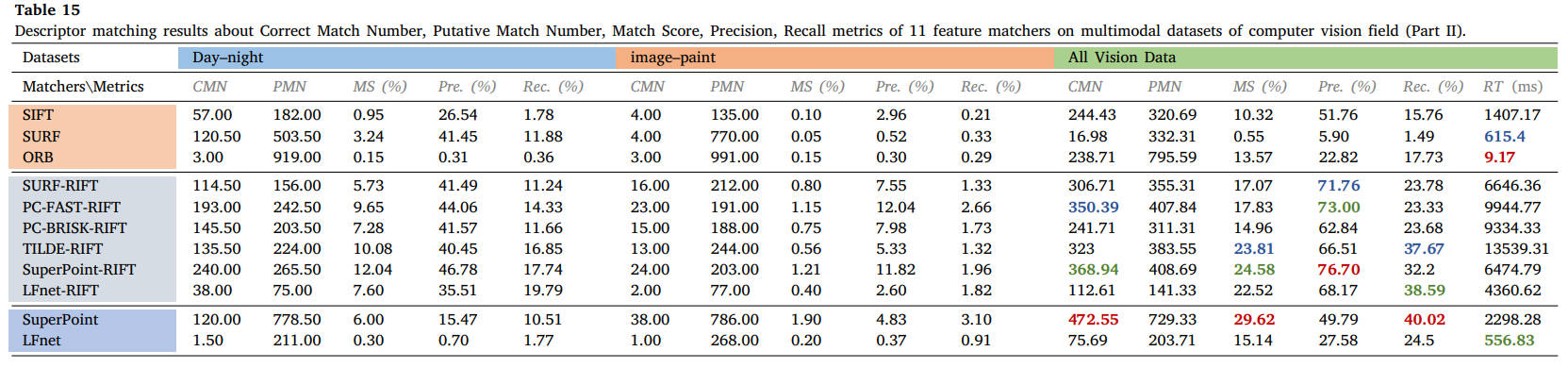
表15 11个特征匹配器在计算机视觉领域多模态数据集上的描述符匹配结果(第二部分):正确匹配数、假定匹配数、匹配分数、精度、召回率。
从结果中我们可以看出,SIFT、SURF 和 ORB 等经典描述符在大多数多模态情况下不再适用,而 RIFT 和 SuperPoint 可以处理大多数类型的 MMIM 任务,但 RIFT 通常非常耗时。特别是对于医学数据,由于两种模态之间结构信息的良好保存,可以成功实现不同加权MR图像的特征匹配。相比之下,MRI-PET 或 SPECT-CT 模态对的匹配并不容易实现,因为即使使用手动匹配,在这两种情况下也能使用很少的线索。对于视网膜图像,RIFT可以达到令人满意的性能,而PIIFD也可以表现良好,但消耗太多时间。在这些数据集中,我们使用 PC-FAST 检测器和 RIFT 描述符来构建假定的匹配集,以用于后续的失配消除和图像配准。遥感数据集的对比实验表明,只有 RIFT 描述子才能获得良好的性能,并且正确匹配的数量和比例很高。我们还选择 PC-FAST 和 RIFT 来构建假定的匹配集。这种优势在视觉领域是截然不同的。由于图像强度差异不显着,针对视觉应用提出的几种匹配器在可见光-近红外、跨季节和昼夜图像匹配中保持了可行性。在我们的评估和可见光-红外图像匹配中,只有 RIFT 能够实现有希望的性能。在图像与绘画的配合处理上还需要多下功夫。在这些视觉数据集中,我们使用 SuperPoint 的检测器和 RIFT 来创建假定的匹配。
4.4 错配消除评估
从基于局部描述符相似度的特征匹配结果可以看出,仅使用图像局部信息来搜索匹配的兴趣特征将不可避免地产生大量且高比例的错误匹配。这种情况可能会极大地损害图像变换或变形估计的准确性,并显着影响配准。需要集成不匹配消除程序以找到尽可能多的正确匹配并将不匹配保持在最低限度。我们首先为上一个实验中介绍的每个图像对创建一组假定的匹配,从中我们可以提前知道哪个匹配是正确的,参考正确匹配集的定义。这个正确的匹配集将作为我们在错配消除实验中的基本事实。基于假定的匹配集和正确的匹配标签,采用三个评估指标,即精确度、召回率和F-score。,通过验证错配消除方法识别的匹配与真实正确匹配集之间的一致性,我们可以获得真阳性(TP)、真阴性(TN)、假阳性(TP)和假阴性(FN)的数量。因此,Precision 和 Recall 可以通过以下方式获得
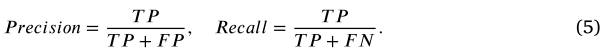
而F-score作为准确率和召回率的汇总统计,计算公式如下:
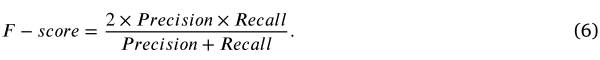
本实验使用了12种错配去除方法进行比较,分别是RANSAC[301]、MAGSAC++[317]、ICF[323]、VFC[319]、LLT[325]、GS[243]、SM[241]、 ,LPM [330]、GMS [329]、mTopKRP [332]、LFGC [341] 和 LMR [342]。这些方法代表了基于重采样、基于非参数模型、基于图、宽松和基于学习的方法。所有方法均使用作者提供的源代码在具有 4.0 GHz Intel Core i7-6700K CPU、16 GB 内存的台式机上执行。
典型多模态图像对上代表性失配消除方法的定性结果如图 11 12 13 所示。为了可见性,在每个图像对中,最多呈现 100 个随机选择的匹配项,并且不显示真正的负例。这三个图中的蓝线、绿线和红线分别代表 TP、FN 和 FP 匹配,由评估的错配消除方法保留。每个数据集上的 Precision、Recall、F-score 和 RunTime 的所有定量结果如图 14 所示。使用重采样或非参数模型的方法可以实现令人满意的精度,因为它们对这些线性测试数据的全局几何约束,转变。基于图的方法也是可以接受的,但它们受到巨大的计算负担的限制。GMS 和 LPM 等宽松方法由于其宽松的几何约束而易于实现且效率惊人。基于学习的方法通过从稀疏点集学习在失配消除任务中显示出有前途的能力。LMR 还可以取得令人满意的结果,因为手工制作的高维匹配表示可以轻松学习识别异常值。然而,通过使用深度卷积方法(例如 LFGC)直接学习几何属性来指导网络过滤异常值仍然是一个具有挑战性的问题。
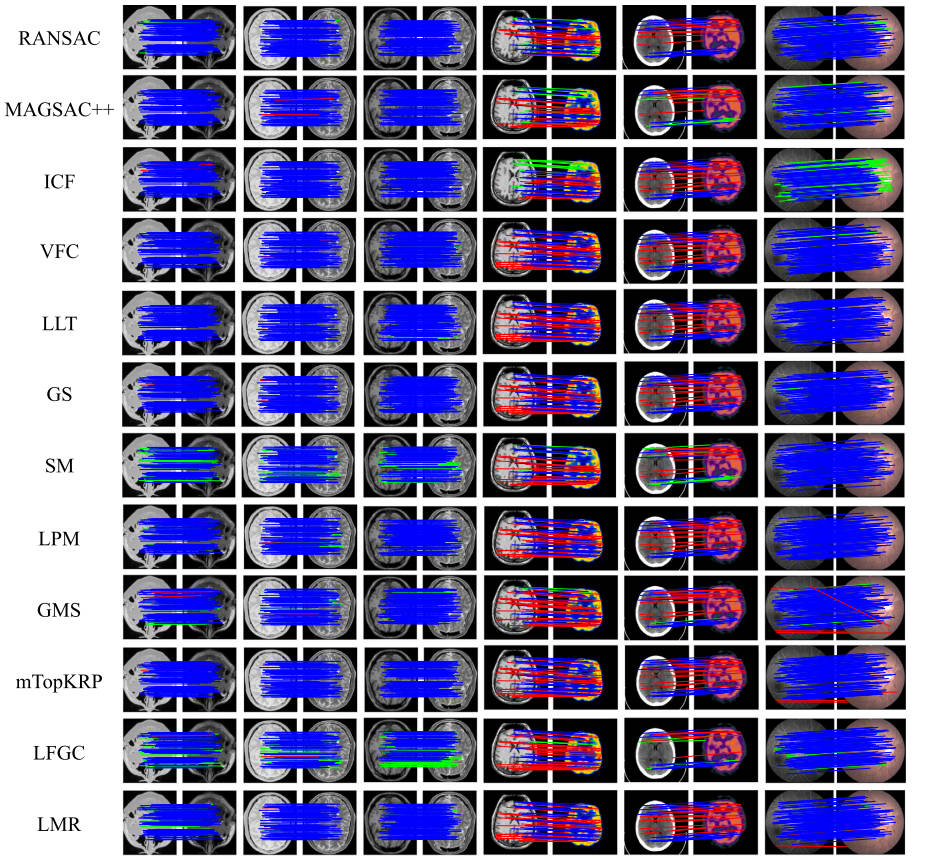
图11。12种去错配算法对典型医学多模态图像对的定性结果。为了提高可见度,在每个图像对中,最多只显示100个随机选择的匹配,而不显示真实的底片。(蓝色=真阳性,绿色=假阴性,红色=假阳性)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)
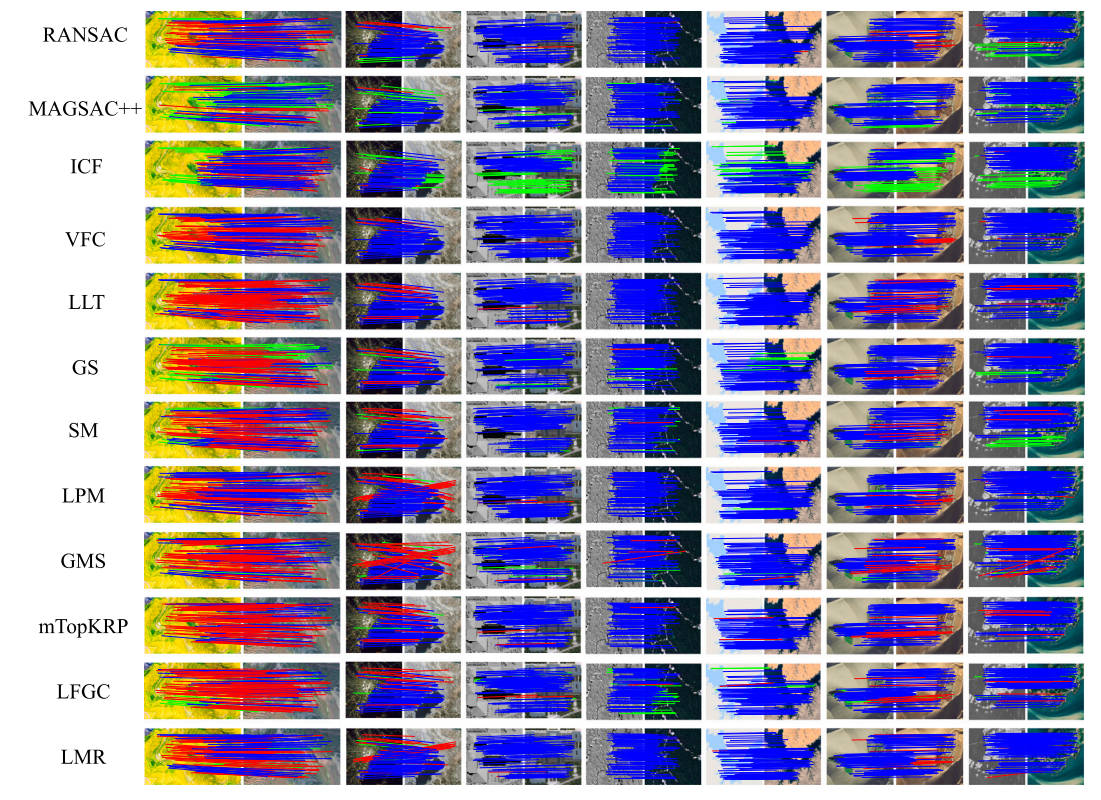
图12。12种算法在典型遥感多模态图像对上的失配去除定性结果。为了可见性,在每个图像对中,最多随机选择100个匹配,并且不显示真实的底片。(蓝色=真阳性,绿色=假阴性,红色=假阳性)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)

图13。计算机视觉领域12种典型多模态图像对错配去除算法的定性结果。为了可见性,在每个图像对中,最多随机选择100个匹配,并且不显示真实的底片。(蓝色=真阳性,绿色=假阴性,红色=假阳性)。(对于图例中有关颜色的解释,请参阅本文的网页版本。)
如参考文献中所示[2,333]。并且注册是在TPS等非刚性模型下进行的[336]。
4.5 图像配准评估
在这一部分中,我们将使用上述特征检测器、描述符和不匹配消除方法创建的最终匹配特征来测试图像配准性能。如上所述,对于具有真实仿射矩阵的图像对,我们直接使用直接线性变换来估计其最佳变换参数。而对于非刚性情况,我们将它们的变换建模为 TPS,并直接估计非刚性配准的参数,如[336]中所执行的。为了评估配准准确性,选择了两种类型的指标。第一个是从我们的地面真实匹配地标的距离获得的,它受到[476]的启发并表示为TRE(即目标配准误差)。这种类型的指标对于测量配准精度更加客观[336]。在我们的实验中,这由具有以下定义的地标对之间的均方根误差 (RMSE)、最大误差 (MAE) 和中值误差 (MEE) 来表示:
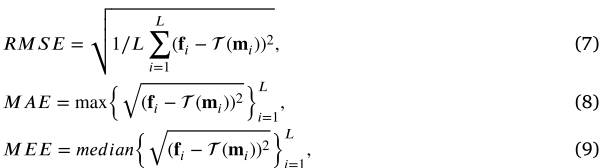
其中是第i个 ground truth 匹配地标,和分别从固定图像和运动图像注释。是从运动图像到固定图像的变换函数,𝐿表示使用的地标的数量,max(⋅)和𝑚𝑒𝑑𝑖𝑎𝑛(⋅)分别返回集合的最大值和中值。
另一种类型的度量通常是根据人类的感知来设计的,在没有地标或其他黄金标准可用于评估图像配准的准确性的情况下广泛使用。这些评估指标通常包括峰值信噪比(PSNR)、结构相似性(SSIM)[411]以及扭曲的运动图像和固定图像之间的互信息(MI)。
PSNR 是信号最大功率与影响其表示保真度的噪声功率之间的比率。它最常用于测量图像评估中重建误差的质量。SSIM通常用于对图像失真和损失进行建模,测量扭曲的源图像和原始固定图像之间的结构相似性。 MI 决定了两幅图像中图像强度分布的相似程度。这三个指标的值越高代表注册结果越好。我们建议读者参考[6,13,477]了解更多细节。在我们的评估中,我们首先将 RGB 空间中的所有图像(对于单通道图像,我们将该通道重复为三个以模拟 RGB)转换为 YCbCr,然后使用通道 Y 来计算这三个指标。
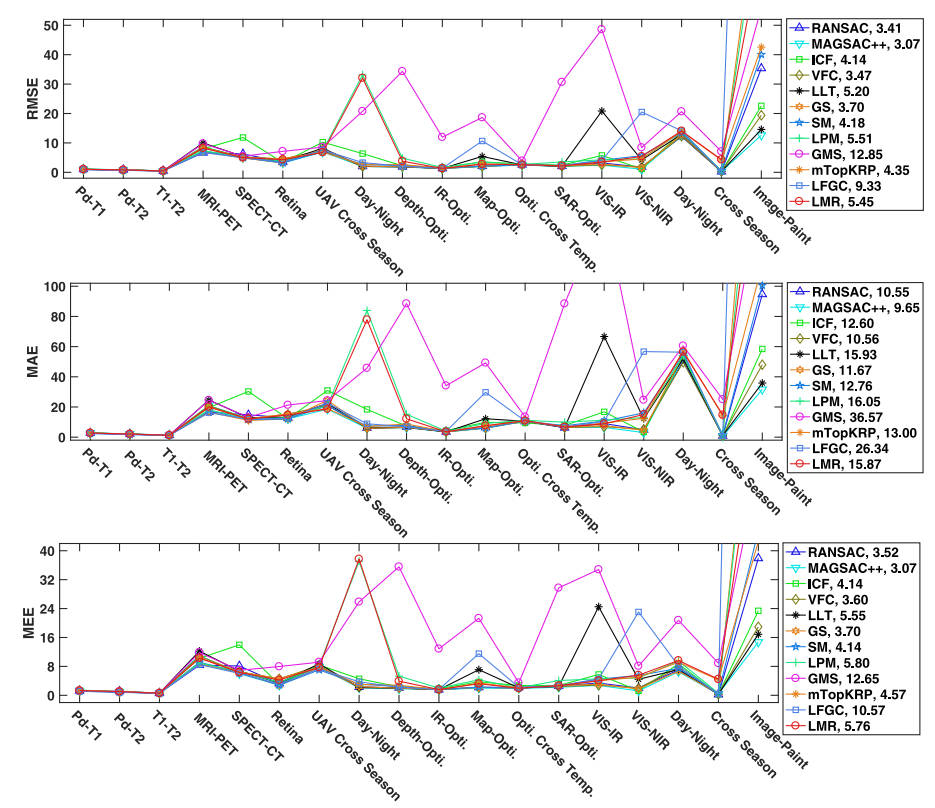
图15。在我们构建的18个多模态图像数据集上,12种具有代表性的去错方法的平均RMSE、MSE、MEE指标的配准结果。值越小越好
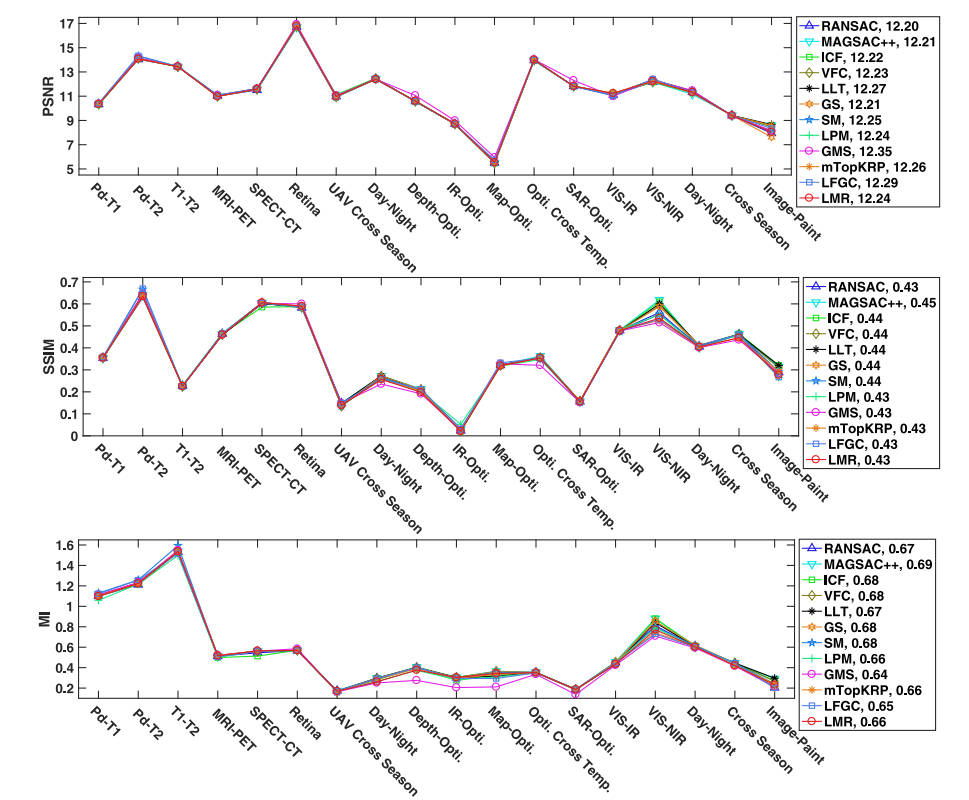
图16。在我们构建的18个多模态图像数据集上,12种具有代表性的错配去除方法的平均PSNR、SSIM、MI指标的配准结果。值越高越好。
图 15 16 显示了 12 种最先进方法的上述六个指标的平均结果。如图 15 所示,基于重采样的先进方法 MAGSAC++ 在基于距离的度量方面获得了最佳配准精度,其次是 RANSAC、非参数和基于图的方法,因为它们的全局几何或严格的局部图一致,限制。对于宽松的方法,LPM 和 GMS 由于其宽松的约束和假定匹配集中的主要异常值,在遥感、VIS-IR 和图像-绘画图像对中受到限制。mTopKRP 由于其增强的异常值过滤规则而更加稳健。基于学习的方法LMR由于其良好的失配消除性能也能取得令人满意的配准结果。然而,正确匹配查找的不良结果显然会导致执行 LFGC 时出现较大的配准错误。
图 16 表明这些方法之间的差异并不是那么显着,因为 PSNR、SSIM 和 MI 与图像配准任务中两幅图像之间的重叠区域高度相关,导致不同数据集之间的范围很大,特别是如果值,随着配准精度略有变化。MAGSAC++在SSIM和MI测量中取得了最好的结果。总体而言,在测量一般多模态图像对的配准精度时,这三个指标的辨别力和客观性低于基于地标的指标。请注意,在我们的早期测试中,基于区域的方法只能在医学数据(视网膜图像对除外)中实现有希望的配准性能,并且对于大尺寸的图像对,它们需要大量时间。因此,我们在医学、遥感和计算机视觉研究中忽略了基于区域的 MMIM 测试方法。此外,对于某些类型的模态,例如MRI-PET、SPECT-CT、遥感中的跨季节,即使特征匹配结果不太令人满意,我们仍然可以发现错误匹配可以与内点保持弱一致性,,允许准确估计变换模型,从而获得良好的配准结果,如图 15 所示的 RMSE MAE 和 MEE。
5 应用
在这一部分中,我们将简要介绍基于MMIM的几个典型应用,包括图像融合、变化检测、图像定位、目标识别和跟踪。这部分将为 MMIM 或注册的重要性提供更深入的理解。
5.1 图像融合
图像融合是图像配准技术最重要的应用之一[13,478]。形式上,图像融合从不同传感器或不同拍摄设置下获取的图像中提取最有意义的信息,并将这些信息组合起来生成单个图像,该图像包含更丰富的信息,更有利于后续应用[13]。然而,不同的传感器或拍摄设置可能会导致一些性能下降,例如不同的分辨率和运动模糊,这将使捕获的图像不对齐。因此,目前几乎所有的图像融合方法中,都已经默认对源图像进行了严格的配准,这也是后续特征提取、融合和重建的前提。根据传感器或拍摄设置,图像融合可以分为多种场景,包括红外和可见光图像融合、医学图像融合、全色锐化、多重曝光图像融合和多焦点图像融合。我们介绍这些融合场景并提供代表性作品。
红外与可见光图像融合的目的是保留红外图像的显着对比度和可见光图像的纹理,生成具有显着对比度和丰富纹理细节的单幅图像。马等人。[479]提出了一种名为FusionGAN的端到端模型,该模型在GAN的基础上生成具有主导IR强度和附加可见梯度的融合图像。通过保留更好的细节,[480]进一步改进了这一点。随后,他们引入了双重鉴别器来利用源图像中的结构信息[481]。张等人。[482]采用生成对抗网络来衡量像素级信息的有效性,从而自适应地指导模型产生全聚焦图像。医学图像融合致力于将机体代谢功能信息与组织结构信息相结合,生成更有利于病变诊断的复合图像。侯等人。[483]设计了一种基于CNN和双通道尖峰皮质模型的CT和MRI融合方案,可以保留源图像的显着特征和细节。全色锐化旨在融合低分辨率多光谱图像和高分辨率全色图像以产生高分辨率多光谱图像。杨等人。[484]提出了PanNet,其中网络在高通滤波域而不是图像域进行训练。他们将上采样的多光谱图像添加到网络学习到的残差中,生成最终结果,以加强空间结构的保存。马等人。 [485]首次使用GAN在无监督的情况下实现全色锐化。他们的模型由生成器、光谱鉴别器和空间鉴别器组成,它们一起工作以保留光谱和空间信息。
以上三种场景都是不同传感器捕捉到的图像的融合。对于融合不同拍摄设置下捕获的图像,最典型的两种场景是多重曝光图像融合和多焦点图像融合。多重曝光图像融合涉及融合曝光过度的图像和曝光不足的图像以生成适当照明的图像。有些方法可以产生有希望的结果。例如,Hayat 等人提出了一种使用密集 SIFT 描述符和引导滤波器的无重影多重曝光图像融合技术。[486],可以使用普通相机生成没有重影伪影的高质量图像。普拉巴卡尔等人。[487]提出了一种无监督深度学习框架,利用无参考质量度量作为损失函数来评估曝光质量,并可以产生令人满意的融合结果。多焦点图像融合作为一种图像增强方法,可以融合不同聚焦区域的图像以获得单一的全清晰图像。郭等人具有创新性。[488]提出使用条件GAN进行多焦点图像融合。与这些针对单个融合场景的方法不同,有些作品可以统一实现多个融合任务。张等人。[489]将多个图像融合任务统一为强度信息和梯度信息的提取和重建,并以统一的形式设计了损失函数,可以产生具有良好视觉感知的结果。同样,徐等人。[490]利用持续学习技术来保持网络的记忆容量,从而实现统一的图像融合。
上述方法均在对齐中进行特征提取,然后进行特征融合和图像重建。因此,空间配准直接决定融合性能。对此,高精度图像配准技术的研究对于图像融合领域具有重要意义。
5.2 变化检测
变化检测是指确定不同时间拍摄的同一场景的图像对之间的差异,引起了计算机视觉、医学和遥感越来越多的兴趣[491]。一般来说,变化检测广泛并成功地应用于环境监测[492]、损害评估[493]等。
在过去十年的遥感应用中,越来越多的变化检测技术被提出,用于对地球表面进行全方位观测的环境监测。根据所使用的图像是否具有相同模态,现有方法可以大致分为两类:即基于单传感器的变化检测和基于多传感器的变化检测。不同的拍摄时间(例如白天和夜晚、跨季节)和不同的传感器(例如光学和SAR)可能会导致成像差异,例如颜色和照明变化以及不同的分辨率。这些差异可能会给配准捕获的图像对带来巨大的挑战。因此,迫切需要多时相或多传感器图像的高精度配准,以避免产生明显虚假的变化检测结果。下面我们将针对上述两个类别推出代表性作品。
第一种类型的变化检测通常对单个传感器的图像系列执行。按照所使用的分析单元,这种类型的变化检测可以进一步分为基于像素的变化检测(PBCD)和基于对象的变化检测(OBCD)。前者利用像素作为图像分析的基本单位,利用其光谱特性来检测和测量变化,几乎不考虑空间上下文。一般来说,统计运算用于测量单个像素。塞利克等人。[494]应用PCA技术将不同图像中的局部邻域映射到高维空间,这是在几个定义的非重叠图像块上执行的。奎因等人。[495]提出了一种称为MIMOSA的变化检测方法,该方法是专门针对SAR时间序列设计的。王等人。[496]引入了一种利用三元组马尔可夫场的多时相 SAR 图像无监督变化检测方法。与PBCD不同,OBCD方法旨在利用图像分割和其他特征提取算法从源图像中提取对象,然后确定对应对象之间的变化。例如,米勒等人。[497]提出了一种 OBCD 算法来检测一对灰度图像之间的显着斑点(即对象)的变化。等人介绍的另一种方法。[498]通过使用相关图像分析和图像分割进行变化检测。
由于成像传感器的重大突破,不同传感器捕获的图像刺激了相关应用的研究不断增加,包括变化检测。现有的此类方法可以大致分为三类:基于差异图的方法、基于深度学习的方法和基于分类的方法。基于差异图的方法的核心思想是在阈值策略下产生差异图,然后发现这些图上的变化区域。阿尔伯格等人。[499]引入了一种相似性度量,该度量仅应用于图像共同配准以计算多传感器遥感图像的差异图。梅西埃等人。[500]提出了一种半监督方法,其基础是假设这两个图像中未改变的区域可能普遍存在某种依赖性。根据联结理论,通过分位数回归对依赖性进行建模。同时,利用对称的Kullback-Leibler距离来获取变化指数。普伦德斯等人。[501]提出了另一种半监督方法。他们使用混合分布对分析窗口中包含的对象进行建模。随后在[502]中,他们基于之前的工作引入了贝叶斯非参数模型,该模型成功克服了需要先验了解分析窗口中对象数量的缺点。基于深度学习的方法旨在通过使用深度神经网络来学习特征图,从而利用这些深度特征指导变化检测以获得更好的性能。例如,Zhang 等人提出了多空间分辨率变化检测框架。[503],它构建了一个映射神经网络来利用多传感器图像之间的内部关系。赵等人。[504]引入了一种近似对称的深度神经网络来检测两侧包含相同数量耦合层的多传感器图像之间的变化。对于基于分类的方法,常见的策略是分类后比较,这能够最小化不同传感器的影响。更典型的方法是[505],其中 Mubea 等人。应用最大似然和支持向量机对遥感图像进行分类。土地利用变化监测是通过比较相应年份的变化来实现的。
作为先决程序,多时相和/或多传感器图像的图像配准在基于图像的变化检测中发挥着重要作用。变化检测领域有必要更加重视MMIR的研究。
5.3 图像定位
图像定位旨在通过将视觉传感器捕获的当前位置图像与先前图像进行比较来识别已知位置。图像定位主要由图像处理模块、映射框架和置信生成模块组成[506]。随着环境(例如季节、天气、照明)的变化以及拍摄角度的调整,提高图像定位的准确性是一个重要但具有挑战性的问题[507]。可靠的注册是缓解环境和季节变化以及长期本地化的基石[508]。接下来,我们将简要描述一些代表性的图像定位方法。 接下来,我们将简要描述一些代表性的图像定位方法。
为了使机器人能够创建环境地图,同时使用这些地图来确定它们所在的位置(本地化),Milford 等人。[24]提出了一种称为 SeqSLAM 的方法,用于可视化变化条件下的导航。他们计算了每个局部导航序列中的最佳候选匹配位置,并通过识别这些局部最佳匹配的相干序列来实现定位,从而适应环境变化。为了减少各种季节差异的影响并处理地点重访和闭环问题,Naseer 等人提出了一种在室外环境中对移动机器人进行视觉定位的方法。[7]。他们将图像匹配制定为数据关联图中的最小成本流问题,以有效地使用序列信息并处理由于时间遮挡或访问新地点而导致的不匹配图像序列。在此基础上,他们引入了基于 HOG 特征和来自深度 CNN 的全局描述符的半密集图像描述,以实现鲁棒定位 [509]。他们还利用图像序列来解决大规模感知变化下的视觉定位问题。舍恩伯格等人。[510]设计了一种基于对世界的联合3D几何和语义理解的方法,该方法可以适应一些极端情况。他们利用生成模型进行描述符学习,并以语义场景完成作为辅助任务进行训练。除了室外场景定位之外,Taira 等人。[511]提出了用于室内视觉定位的 InLoc。InLoc 通过三个步骤,即有效检索候选姿势、使用密集匹配进行姿势估计以及通过虚拟视图合成进行姿势验证,可以缓解室内定位挑战,例如缺乏纹理、视点、场景布局和遮挡物发生显着变化。刘等人。[512]提出了一种根据预存的大规模3D点云图快速精确地定位图像镜头的位置和视角的方法。他们提出的方法利用查询图像内和地图中所有 3D 点之间显示的全局上下文信息,不仅考虑了各个 2D-3D 匹配之间的视觉相似性,还考虑了所有匹配对之间的全局兼容性。
总之,图像匹配在不同的领域中起着至关重要的作用。定位场景和高精度配准结果通常会带来可靠的定位。因此,研究优秀的匹配技术在图像定位领域具有重要意义。
5.4 目标识别与跟踪
识别的目的是解释场景或从图像中区分不同的对象,跟踪的目标是检测移动对象并通过估计其运动参数来追踪感兴趣的目标[513]。此外,自动目标识别(ATR)是一种通过将实时获取的图像与数据库中存储的数据进行比较来识别物体或目标的技术[458]。目标识别和跟踪常用于许多实际场景,例如视频监控和交通控制[514,515]。至于 ATR,它通常用于可增强导弹制导能力的一次性应用。在多源图像ATR任务中,由于不同传感器捕获的图像存在明显差异,需要对不同源图像进行配准,从而阻碍目标对齐,从而影响目标识别的准确性[516]。在目标识别和跟踪任务中,图像匹配是补偿背景运动的关键步骤[517]。随后,我们介绍了典型的目标识别和跟踪方法,以及图像匹配在其中的应用。
基于目标的可见图像可作为先验获得的假设,Cheng 等人。[458]提出了一种在各种条件下红外和可见光图像之间的物体识别算法。利用边缘检测和二进制模板匹配来初始化红外和可见光图像,然后使用局部模糊阈值来识别高度相似的物体。尹等人。[518]提出了一种在背景中前视红外图像中自动机载目标识别和跟踪的方法。他们采用图像分割和合并技术来检测复杂环境中的可靠目标,然后训练贝叶斯分类器以使用归一化惯性矩阵特征完成分类。最终,他们将联合检测和分类结合起来,以联合集成最高概率实现杂波中的多目标跟踪。为了从多角度监控视频中检测和识别移动目标,Zhou 等人。[519]研究了基于 HOG 检测和系统聚类的多视图前景匹配模型,使用背景减法、HOG 特征检测和系统聚类中偏差的最小二乘法。考虑到 RANSAC 选择的内点,过度集中于图像和目标区域中的特征点可能会妨碍准确配准并影响背景补偿。徐等人。[520]设计了一种独特的运动物体检测框架,其中利用特征点选择和配准精度预测来提高检测精度。Hu 等人提出了一种从视频序列中检测和跟踪多个移动对象的实用方法。[521]。在这种方法中,作者解决了在运动物体检测和跟踪中混合相机运动和物体运动的挑战。他们使用基于最小边界框中移动物体区域重心的卡尔曼滤波器来跟踪多个移动物体。
上述方法只是目标识别与跟踪领域的冰山一角。对于研究人员来说,致力于 MMIM 来实现该应用程序的先进性能具有重要意义。
6 结论以及未来趋势
多模态病例的图像匹配或配准在各个领域发挥着关键作用,包括医学诊断、遥感(变化检测、地图更新、数据融合)和计算机视觉(图像融合、目标识别和跟踪、图像定位或地点),认出)。在过去的几十年中,人们提出了越来越多且多样化的技术来提高性能。为了给相关领域的研究人员和工程师提供对MMIM的重要参考和理解,我们对MMIM方法及其应用进行了全面、系统的综述,涵盖了医学、遥感和计算机视觉研究中的典型案例。此外,为了进行实验评估并为未来的研究提供公共标准,我们提供了一个完整的数据库,其中包括我们收集和注释的 18 个模态对(164 个图像对)及其基本事实。为了更好地理解这个问题的意义,我们介绍几个与MMIM相关的典型应用。
尽管MMIM在理论和实践上都取得了巨大的进步,但它仍然是一个悬而未决的问题,未来的发展面临以下挑战:
- 在一般的MMIM任务中,不同模式的图像数据不足和不可用是一个重要的限制。
- 基于区域的方法很大程度上受限于两幅图像之间的小重叠和大变形。由于他们的迭代优化策略,计算消耗是另一个弱点,特别是对于高分辨率图像。
- 基于特征的框架在特征检测和描述中仍然存在很大的非线性强度变化,在某些场景下会产生很少甚至没有准确的对应。·用于变换参数估计的图像学习通常受到复杂的几何变形和图像内容的限制。
- 仅使用局部描述符来构建推定的匹配集将造成较高的错配率和错配率。因此,需要一种准确、稳健和高效的失配去除方法来提高假设匹配集中的内点和离群点之间的分类性能,从而保持对变换参数或变形场的准确估计。
- 无论是手工匹配还是深度匹配,能够处理所有类型的多模式图像的通用匹配方法仍然是一个悬而未决的问题。
- 现有的方法通常以连续的方式执行图像配准和后续任务。一个有价值的任务是尝试将匹配问题集成到组合优化的高级任务中[522,523],或者直接执行最终任务并绕过匹配或配准要求,例如从未对齐图像到图像融合。