深度学习的一些模型改进技巧
深度学习的一些模型改进技巧
[toc]
Group Convolution 组卷积 -> ResNeXt
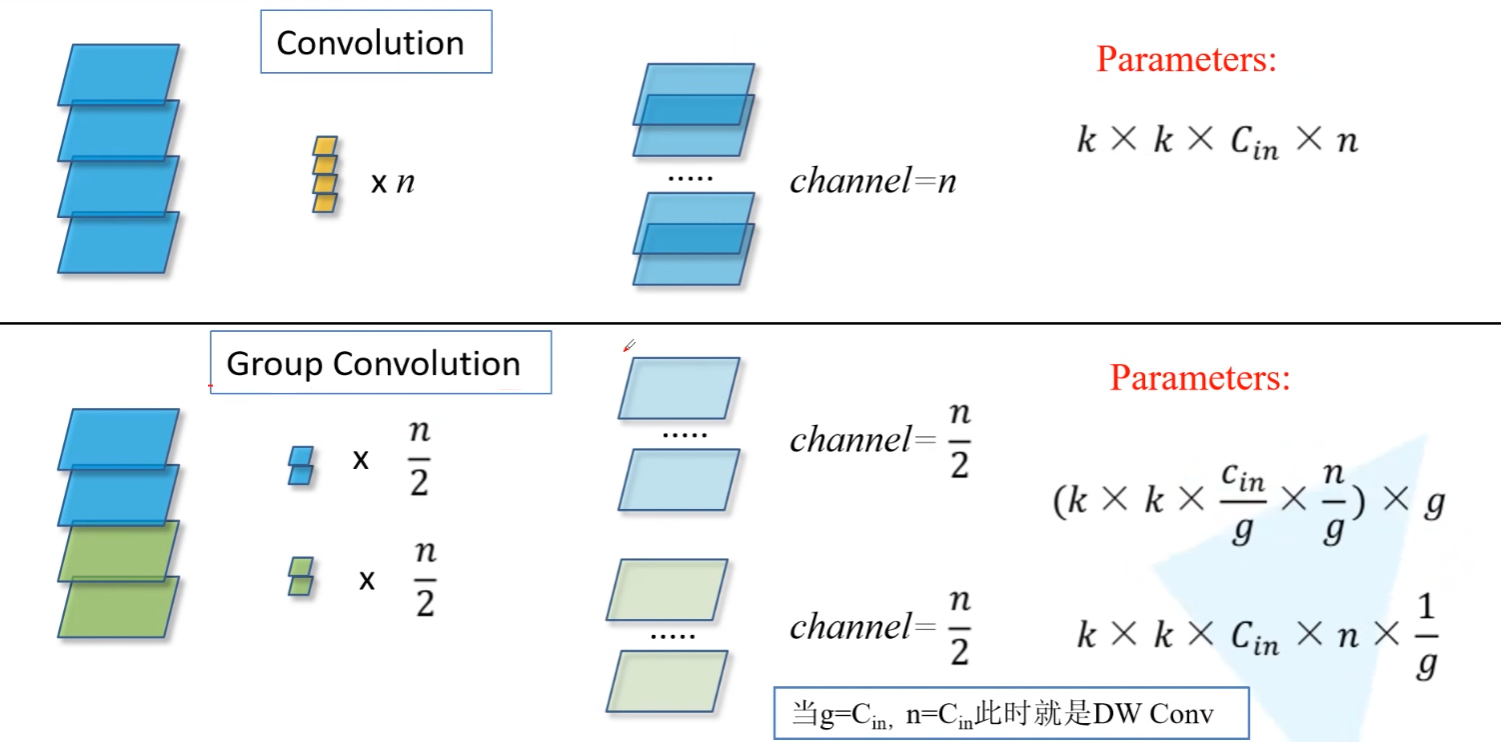
正常卷积,是将输入的所有通道都与同一个卷积核的不同通道卷积并相加,以此来生成一个输出的通道。
但是组卷积,则是将输入的通道进行分组,对于每组通道进行正常的卷积操作。因此卷积核参数量会减小,但是不同组的输入特征间没有进行信息的交互
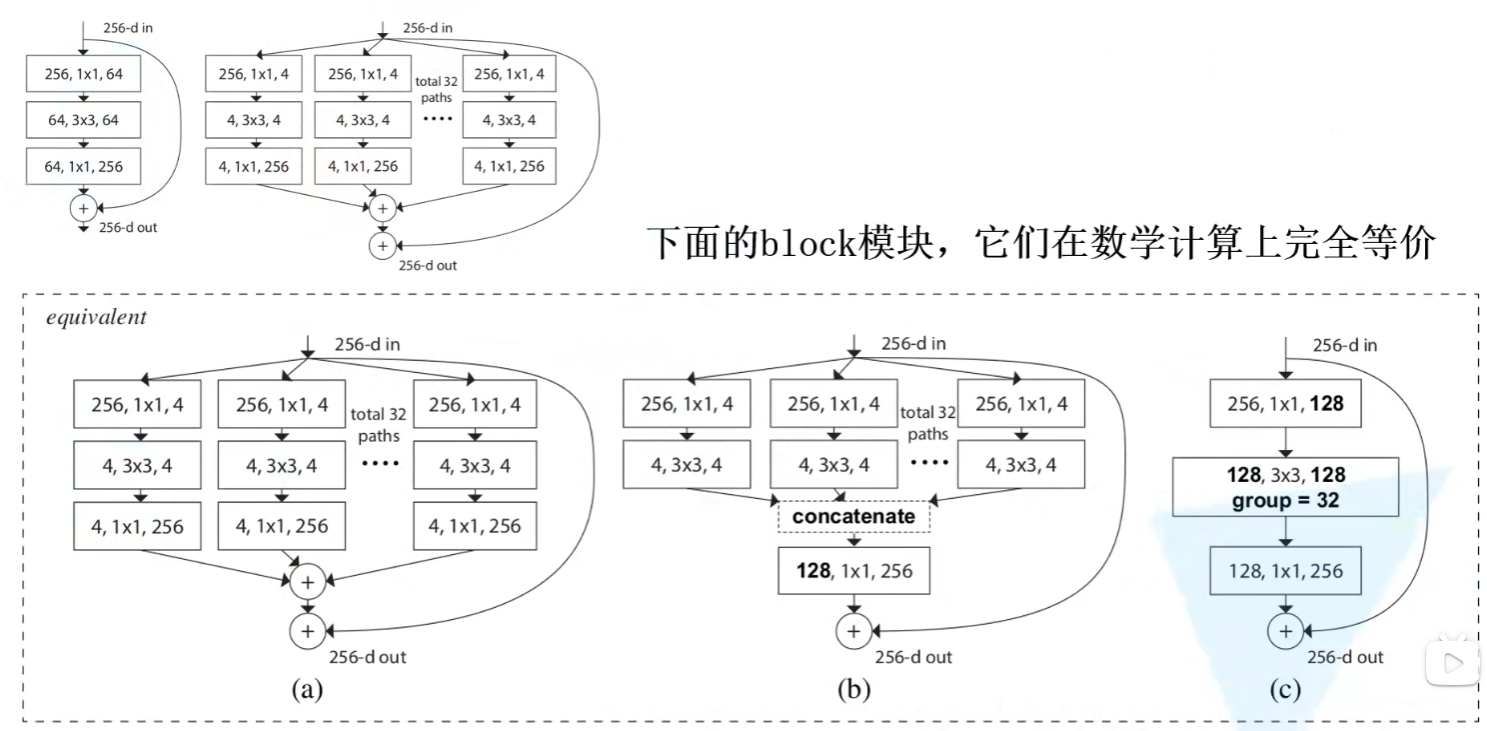
channel shuffle -> ShuffleNet
因为Gconv组卷积的组之间没有信息交互,所以为了进行组之间的信息交互,提出了channel shuffle
也就是在在进行一次组卷积之后,对通道重新分组

作者提出,使用组卷积之后ResNeXt网络主要计算量是在GConv前后的1x1卷积操作,为了降低这部分计算量,作者将1x1卷积也使用了GConv,并将channel shuffle操作放在1x1卷积之后
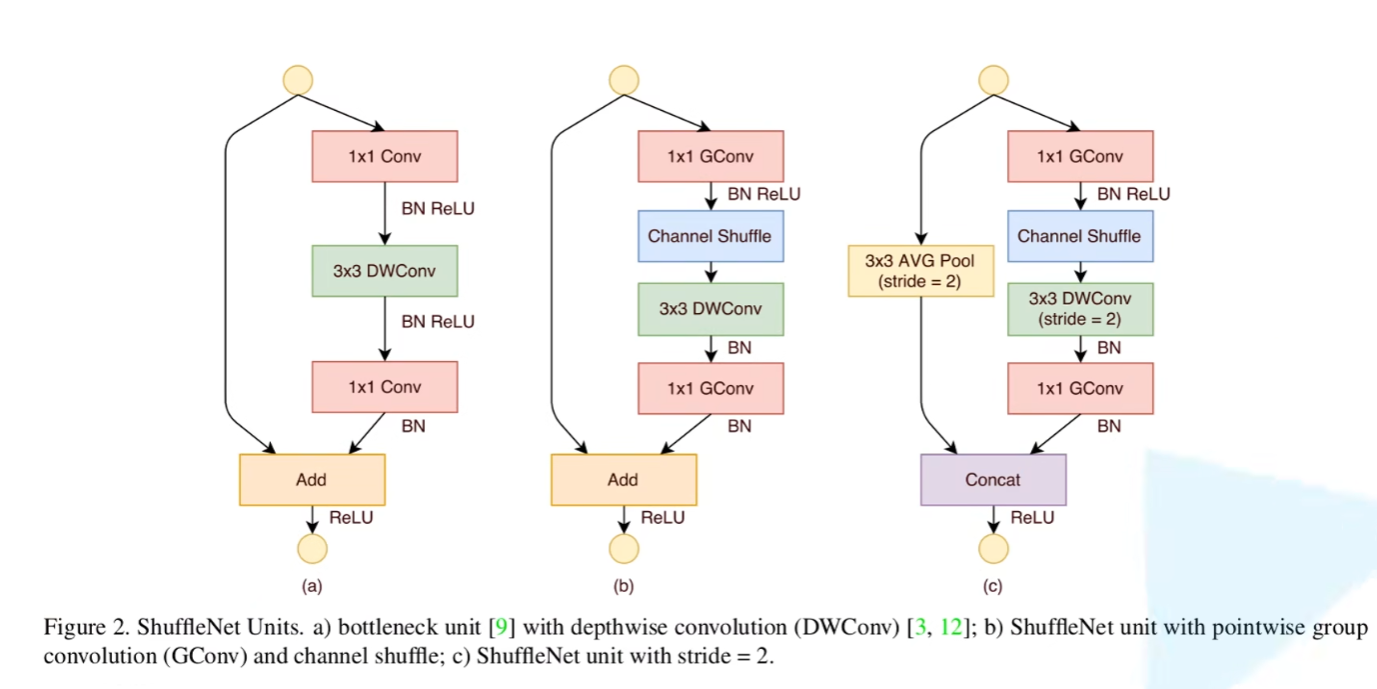
DepthWise Convolution -> MobileNet V1
DW和PW操作是为了降低计算量
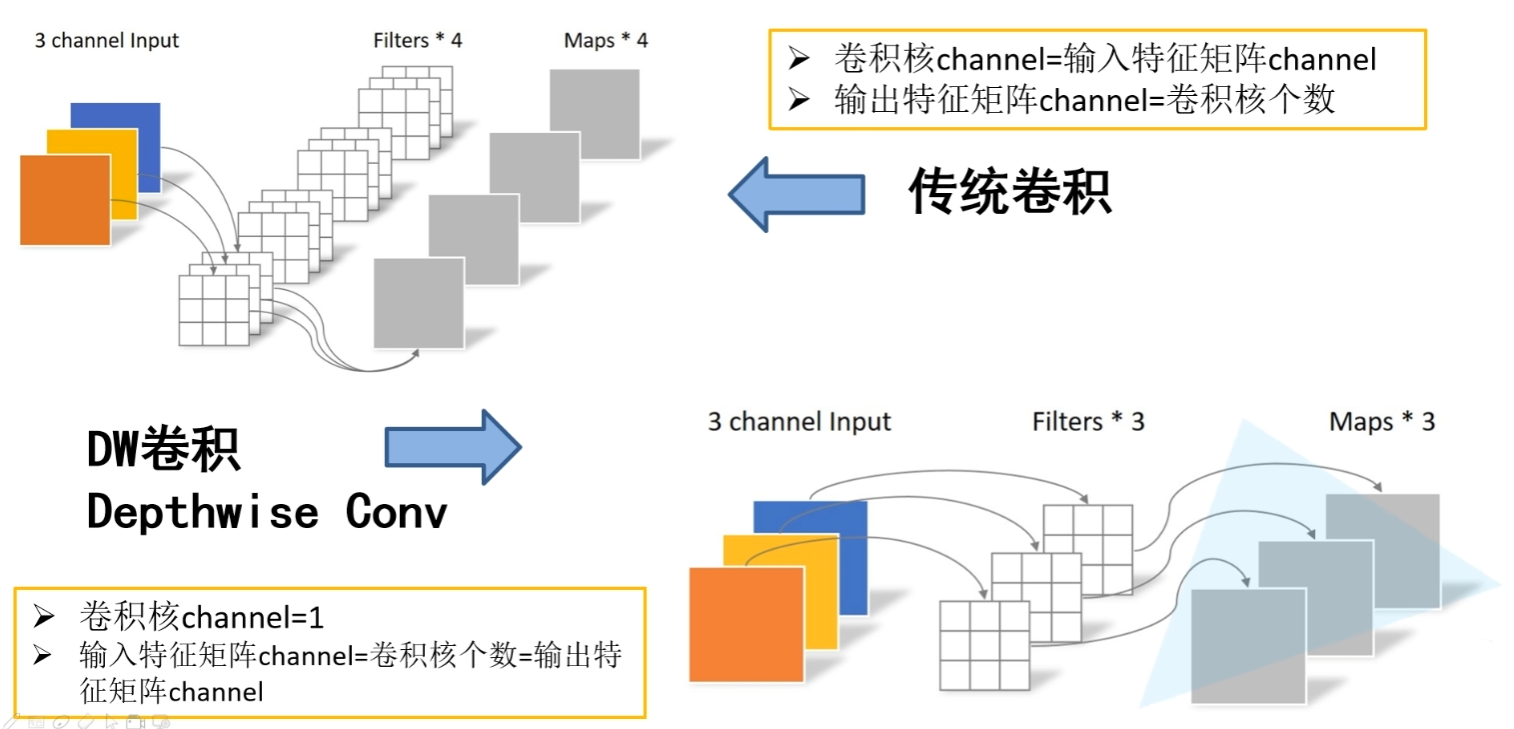
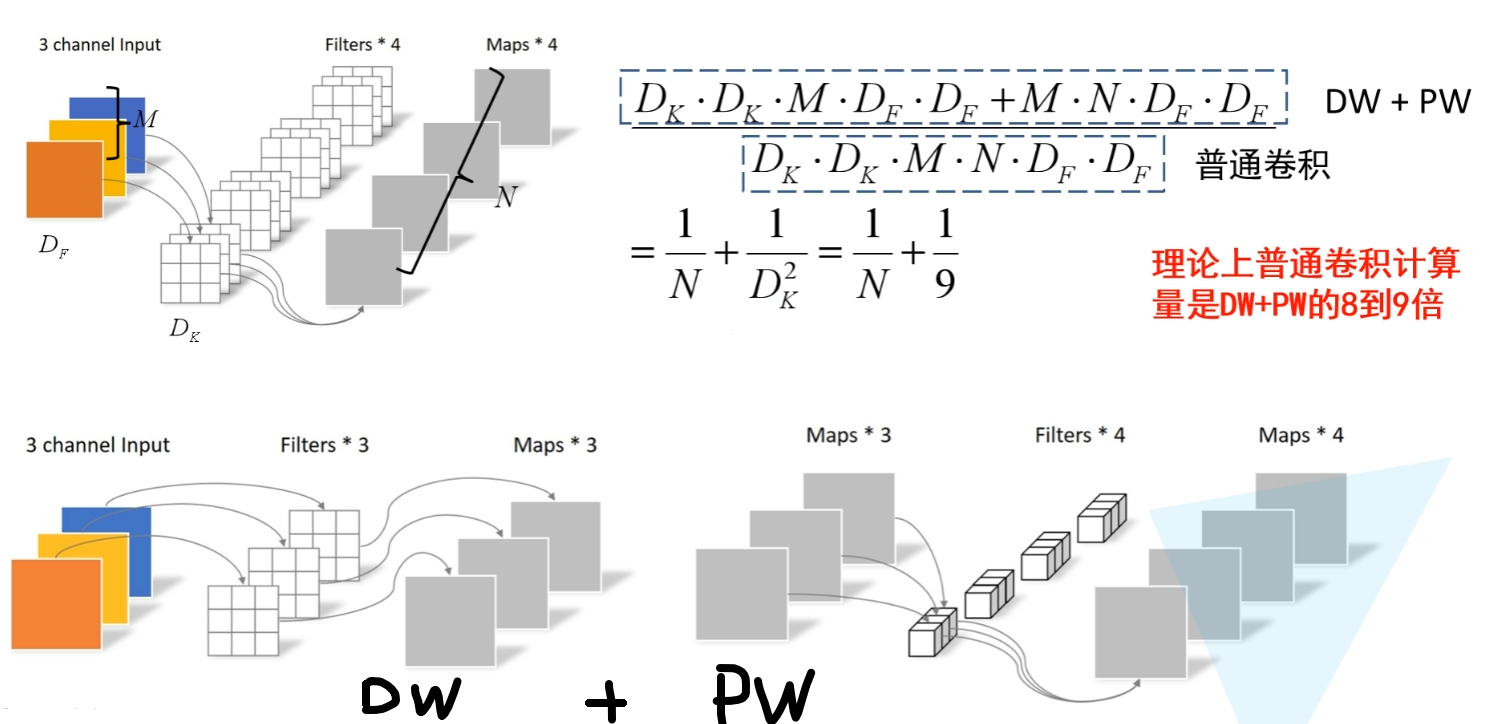
传统卷积的操作是提取特征和信息融合同时进行的
DW卷积可以看作是组卷积GConv的一种特殊形式,此时DW完全放弃了通道间的信息整合,只是单纯的提取的特征
然后使用PW来整合通道间的信息,也就是使用1x1卷积进行信息融合
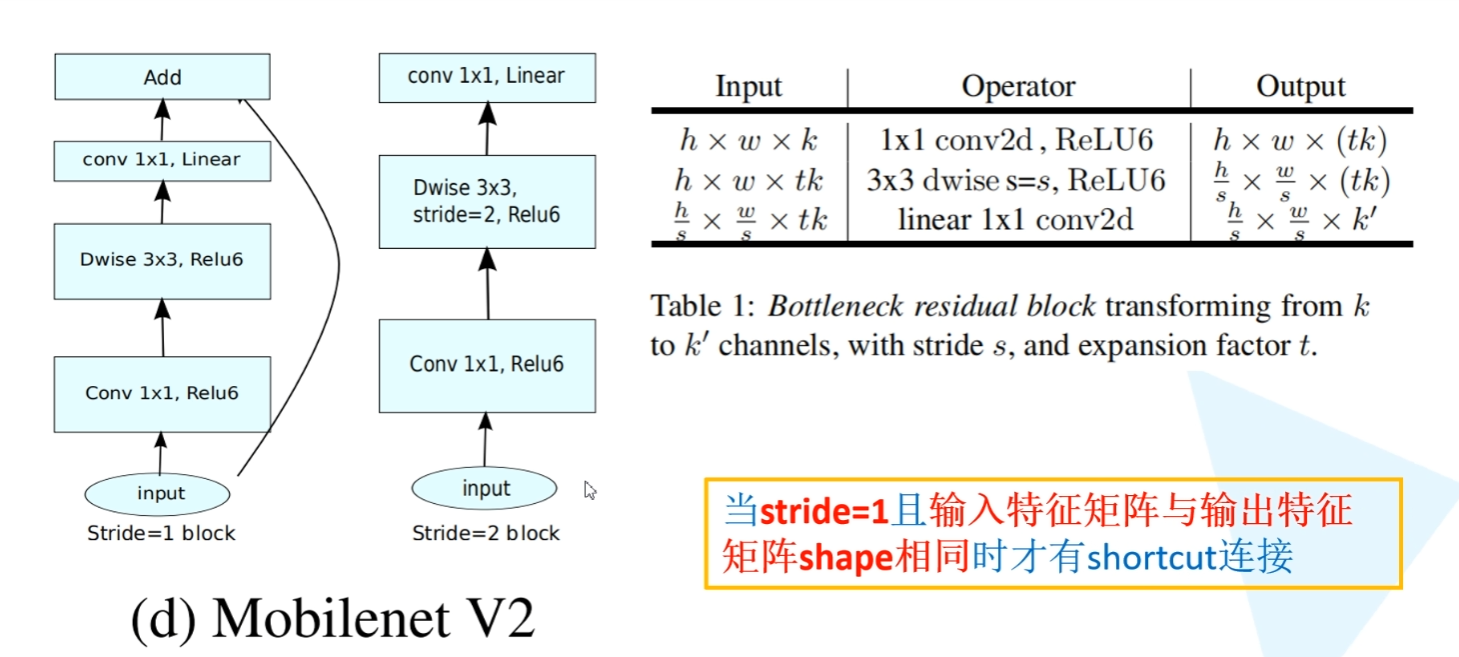
Inverted residual block 倒残差结构 ->MobileNet V2
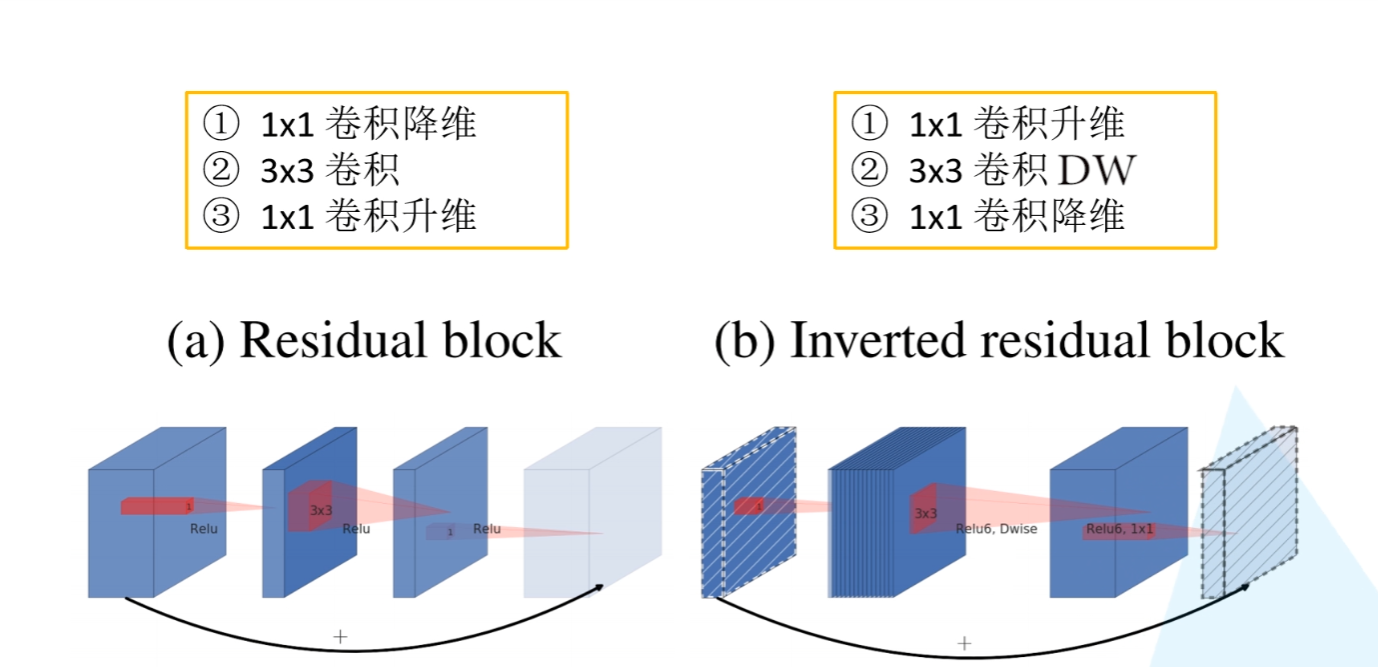
作者提出ReLu激活函数对于特征维度来说,特征维度越高越不容易损失信息,特征维度越低损失的信息越多
因此提出先升维再降维的操作,并且在降维后使用线性激活函数而非ReLu
通道注意力机制SE -> SENet
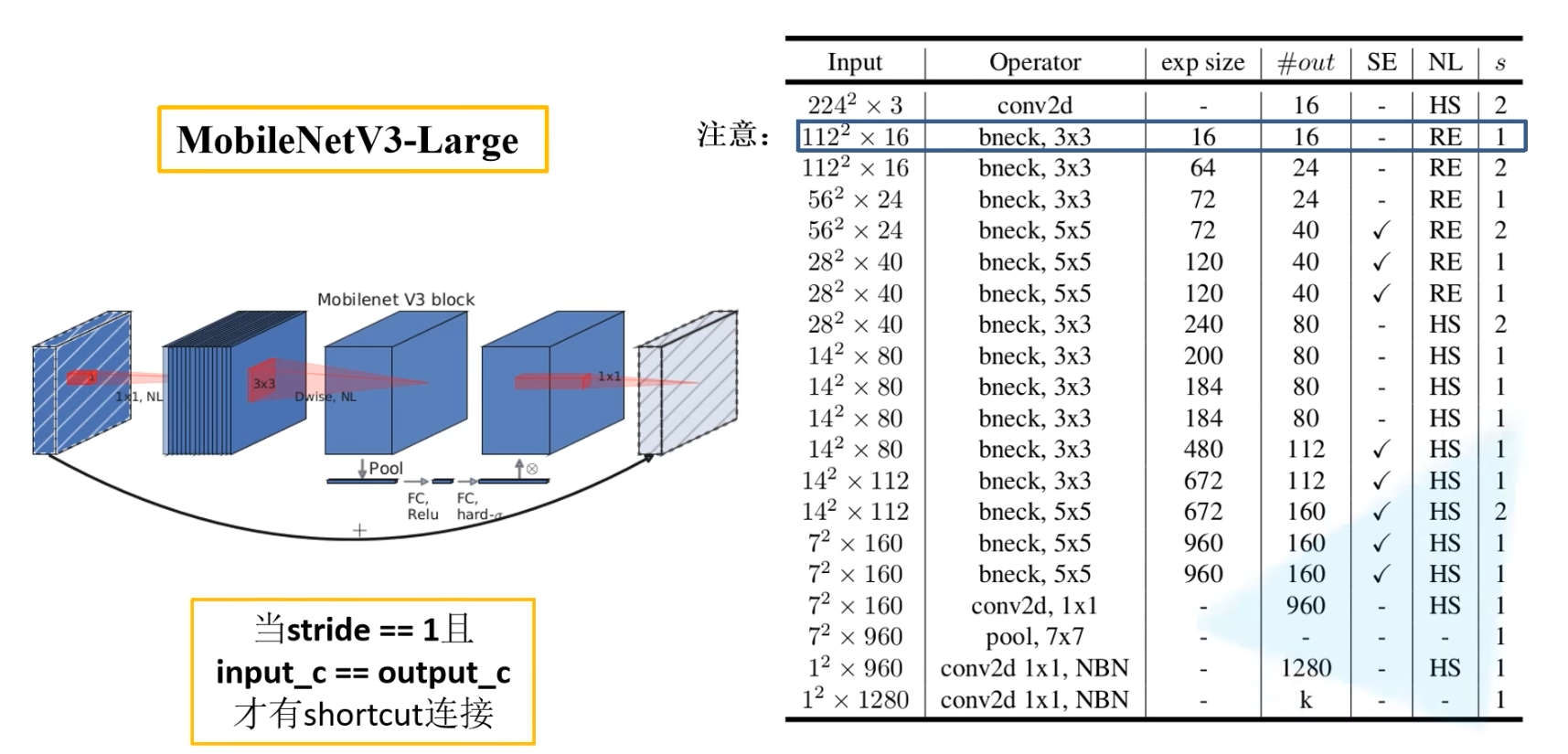
MobileNet V3中对block进行了改进,在block中加入了SE模块
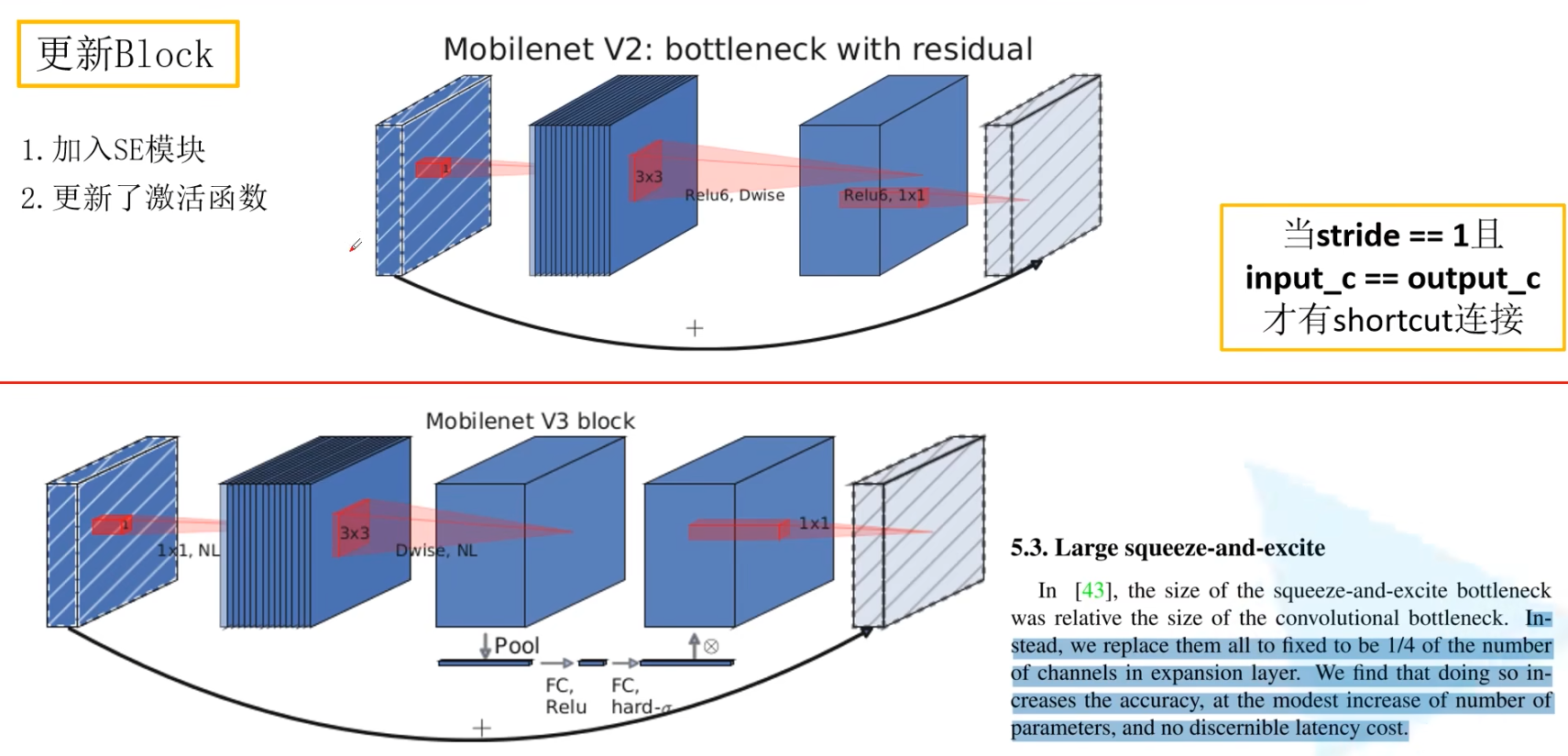
通俗理解就是,在V2中,对DW后的通道是平均处理,在V3中,是加权处理
通道注意力机制第一次出现在SENet中
- 首先通过全局池化,生成一个长度为通道数的一维向量
- 然后通过两个全连接层,输入与输出是相同长度
- 最后输出的长度为通道数的一维向量是表示每个通道的权重

hard-swish 激活函数 -> MobileNet V3
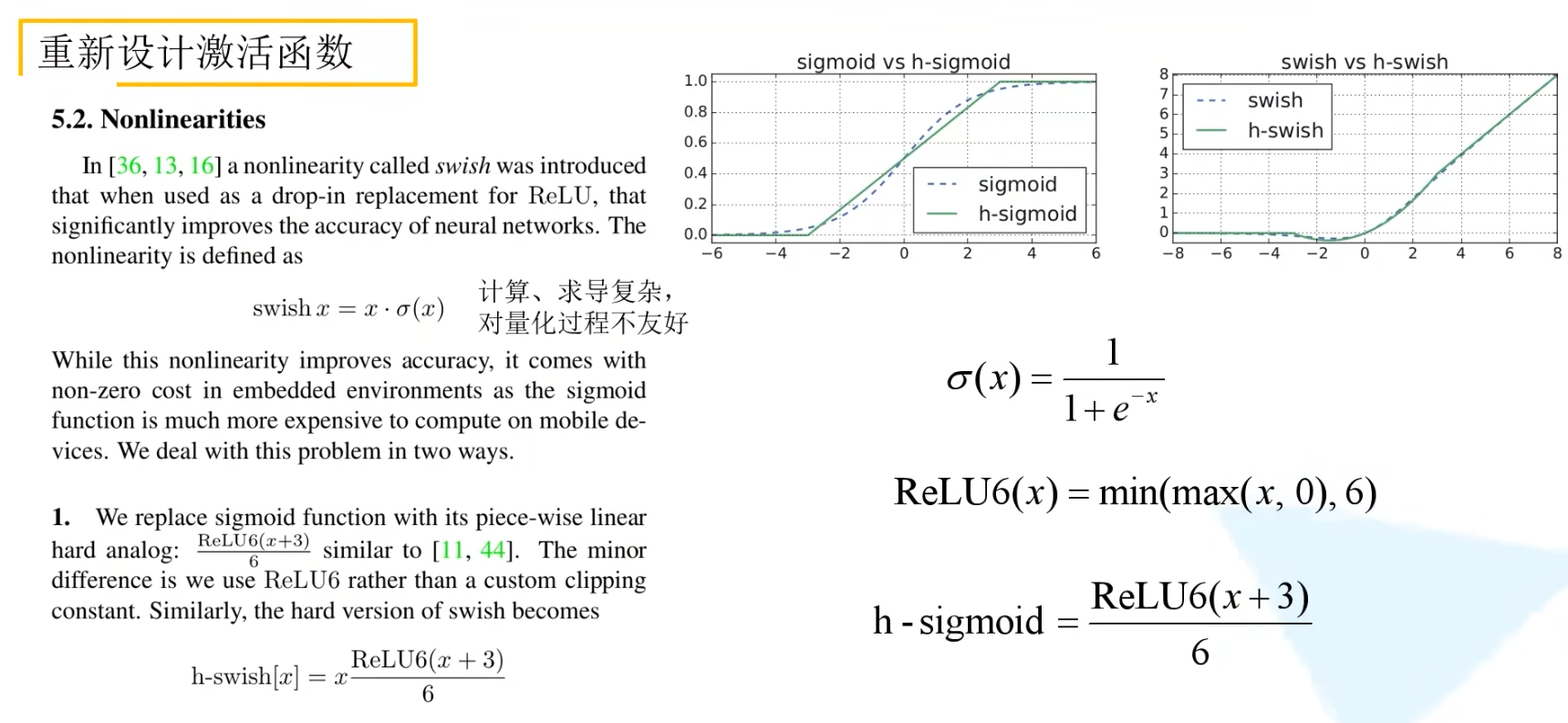
量化是指将模型部署到硬件时,具体将浮点型数定义数据类型,如int8、float32等
将激活函数替换为hard-swish和hard-sigmoid,会对模型的推理速度和量化有帮助
下图是MobileNet V3的网络结构表
四条设计高效网络的准则 -> ShuffleNet V2


G1:相同的通道宽度最小化内存访问成本(MAC)

这里特指的是1x1的卷积操作
是指输入特征高h宽w通道数c1所占的内存空间,同理是指输出特征所占的内存空间
1x1卷积核的通道数是,共有个卷积核,所以卷积核所占内存空间为
这个公式指出,当输入特征的通道与输出特征的通道相等时,所占MAC最小
G2:过度的组卷积会增加MAC

G3:网络碎片化降低了并行度

碎片化可以理解为网络的分支程度,分支越多速度越慢。模块并行理解为分支,但是串行同样也是碎片化的,串行越多,碎片化程度越严重
直观的理解就是,对于GoogleNet的Inception模块,执行一个Inception模块,需要将内部所有分支都运行结束,也就是说先运行完的分支需要等待后运行完的分支,这会大大降低模型的并行度
G4:元素操作是不可忽略的

作者提出如ReLu激活、Add操作等对元素进行的操作都会有较大的耗时.GConv也属于这类操作
总结
作者提出的设计网络的建议:
- 尽可能使输入特征的通道与输出特征的通道保持比值为1
- 虽然增大Group的数目可以减低计算量,但是会增加计算成本
- 降低网络碎片化的程度
- 减少对元素的操作

图中a、b是V1的模块,c、d是V2的模块
对于c来说,
- 使用Channel Split操作来划分通道,使得右分支的输入通道和输出通道保持一致
- 将ReLu激活移到右分支上,减少了一半的元素操作
- 将1x1GConv换成了普通卷积,也就是Group为1
- 使用Concat来替换Add操作,减少了元素操作
结构重参数化 -> RepVGG
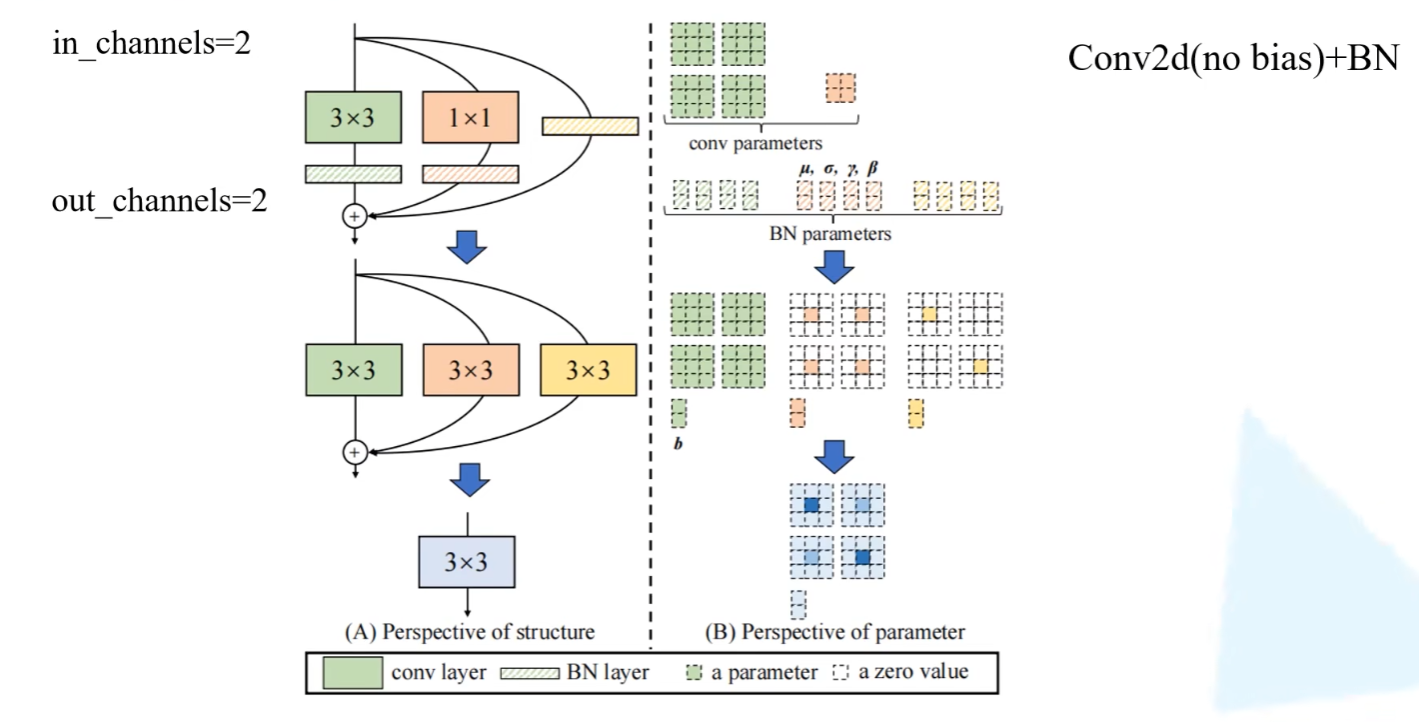
ShuffleNet V2指出结构的分支越多,推理速度会越慢
为此,RepVGG提出,在测试环节将结构的三个分支整合为一个分支,即结构重参数化
实验证明结构重参数化的输出结果与操作之前的结果是一样的
具体来说,就是将每个分支的卷积层和BN层整合为一个3x3的卷积层
融合Conv2d和BN

是融合后的卷积核权重,是卷积核的偏置