Transformer学习笔记
Transformer学习笔记
普通的transformer框架
-
编码端输入:Embedding + Positional Coding,输出X
-
Encoder x L1:
- 多头自注意力机制,输出Y
- 将Y和X残差链接,并进行加法和层归一化,输出X1
- 前馈网络,输出Y1
- 将Y1和X1残差链接,并进行加法和层归一化,输出X2
-
解码端输入:Embedding + Positional Coding,输出X
-
Decoder x L2:
- 多头自注意力机制,输出Y
- 将Y和X残差链接,并进行加法和层归一化,输出X1
- Encoder-Decoder attention,编解码注意力机制,查询使用解码器的输入X1,key-value使用编码器的输入,输出X2
- 将X1和X2残差链接,并进行加法和层归一化,输出Z
- 前馈网络,输出Z1
- 将Z1和Z残差链接,并进行加法和层归一化
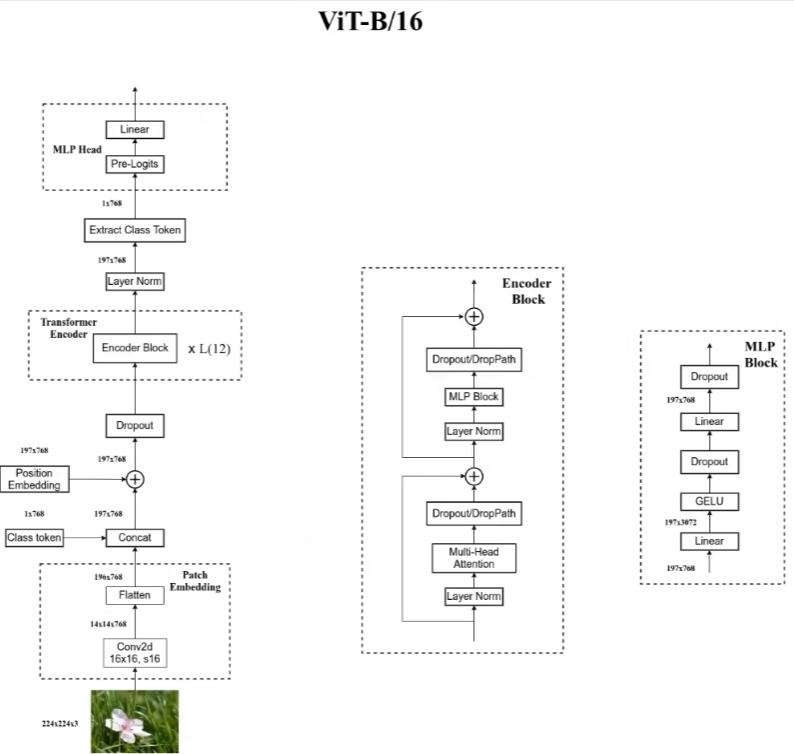
Vision Transformer(ViT)
![]()
对于一张图像来说,为了对图像编码成一个序列,将图像划分为多个Patch,然后对每个Patch展平处理成一个向量。对patch进行展平,是通过卷积核来实现的,该卷积核的kernel_size=patch_size且stride=patch_size
因为图像是二维信息,位置编码时可以考虑使用二维坐标来编码,如(x,y),或者就是一维编码,如1,2,3等。实验表明两者差别不大
ViT的Embedding阶段额外加入了一个0向量,这是为了整合其他所有向量的信息,也就是整合一个全局信息,这样处理通常是用在图像分类任务中。
ViT模型只有在非常大的数据集上进行训练才会获得很好的效果。所以平时可以直接使用官方提供的预训练权重进行迁移学习。
框架具体细化
SwinTransformer
https://blog.csdn.net/qq_37541097/article/details/121119988
SwinTransformer目录
![]()
SwinTransformer与ViT的对比
![]()
SwinTransformer与ViT的不同之处在于Swin进行不同尺度的下采样,以红框为边界,每个方框称为窗口(window),窗口间不进行注意力机制计算,以此减少计算量,但是窗口间的信息不会进行交互。窗口内划分patch。
SwinTransforme框架图
![]()
-
patch partition是对patch通过卷积核进行channel的展平处理
-
Linear Embedding是将48通道改为C通道,并进行layerNorm处理
-
SwinTransformer block是成对出现的,因为要分别使用W-MSA和SW-MSA
- W-MSA(Windows Self Multihead attention)也就是窗口内部的MSA,减少计算量,但是窗口间信息不交互
- SW-MSA(Shifted Windows Self Multihead attention)为了使窗口见的信息交互,而使窗口进行滑动
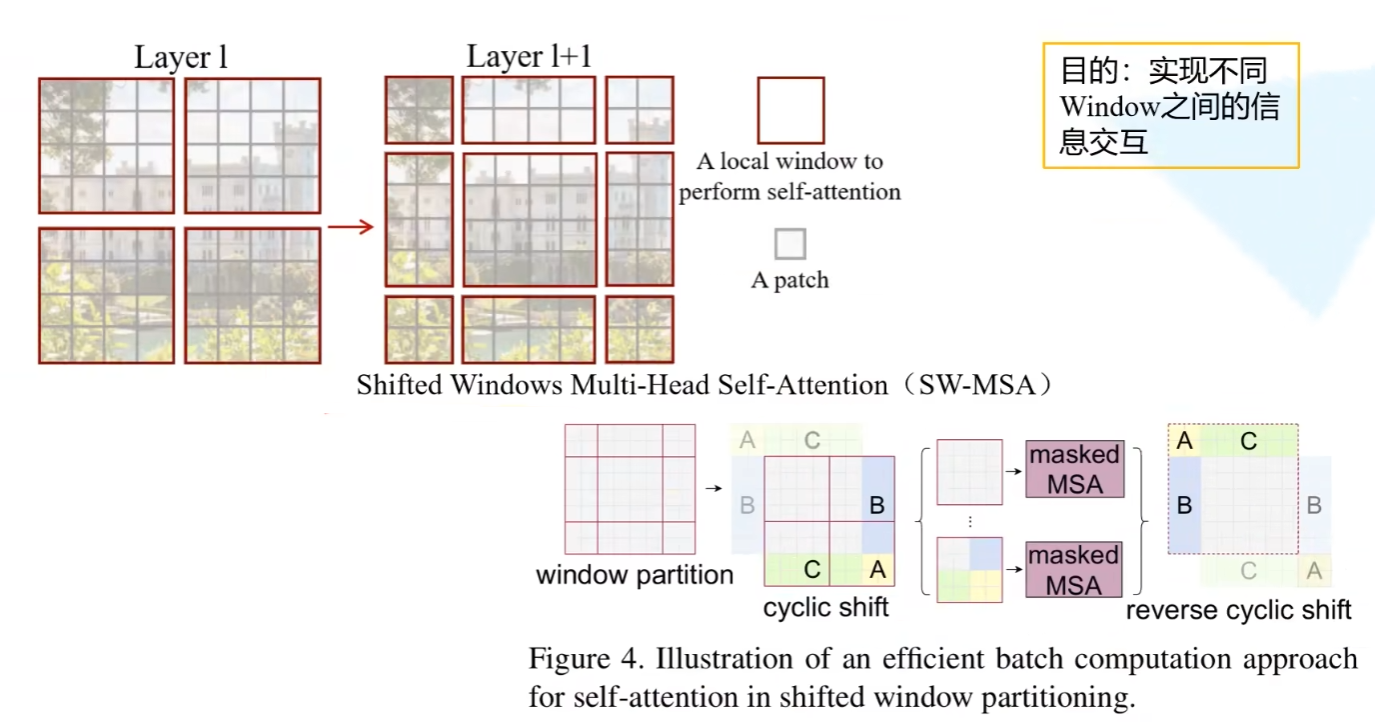
-
但是SW-MSA的窗口大小不一致,导致不能并行计算,为了使窗口尺寸一致,作者将A\B\C区域平移到了右下角,形成新的window,但是平移后的窗口与D区域实际上是不连通的,所以MSA时不能进行信息交互。为此,作者提出使用maskedMSA。
- 具体来说,对于每个会生成的权重矩阵,中会存在与所在区域不连通的权重,这时令其为-100,使得对应的权重为0
SwinTransformer参数设置
![]()