Anaconda + PyTorch + PyCharm
检测是否已经安装成功:
python 进入python
import torch 无报错
torch.cuda.is_available() 返回True
dir()打开某个工具箱(package)如Pytorch,即展示Pytorch内部有哪些模块
help()帮助函数,在jupyter中也可以使用()??来查看具体用法
两大类 :
Dataset提供一种方式去获取数据及其label,主要实现以下两种功能
如何获取每一个数据及其label
输入共有多少个数据
Dataloader为后面的网络提供不同的数据形式
Dataset用法from torch.utils.data import Dataset导入Dataset类
Dataset是一个虚拟类,每次使用需要用户重新定义其成员函数__getitem__()&__len__()
以下是一个常规定义pip install opencv-python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from torch.utils.data import Datasetfrom PIL import Image import osclass MyData (Dataset ):def __init__ (self, root_dir, label_dir ): def __getitem__ (self, index ):""" 返回指定index的图片和label """ open (img_item_path) return img, labeldef __len__ (self ):return len (self.img_path)
定义类之后的使用方式:
1 2 3 4 5 6 root_dir = "DataSet/hymenoptera_data/hymenoptera_data/train" "ants" "bees"
from torch.utils.data import DataLoader载入DataLoader工具箱
用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 test_data = torchvision.datasets.CIFAR10("./Dataset/CIFAR10_dataset" , train =False , transform =torchvision.transforms.ToTensor())dataset =test_data, batch_size =64, shuffle =True , num_workers =0, drop_last =False )"test_loader" )for epoch in range(2):step = 0for data in test_loader:"test_image{}" .format(epoch), imgs, step )step += 1
主要功能是可以展示深度学习中某一步的输出pip install tensorboard
使用from torch.utils.tensorboard import SummaryWriter导入SummaryWriter类
创建实例**writer = SummaryWriter("logs")**将内容保存到logs文件夹
writer.add_scalar()的用法:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def add_scalar ( self, tag, scalar_value, global_step=None , walltime=None , new_style=False , double_precision=False , """Add scalar data to summary. Args:一般只关心前三个参数 tag (str): Data identifier 图片标题 scalar_value (float or string/blobname): Value to save 图的纵坐标 global_step (int): Global step value to record 图的横坐标 walltime (float): Optional override default walltime (time.time()) with seconds after epoch of event new_style (boolean): Whether to use new style (tensor field) or old style (simple_value field). New style could lead to faster data loading.
具体用法:
1 2 3 4 5 6 from torch.utils.tensorboard import SummaryWriter"logs" ) for i in range (1 , 100 ): "y = x" , i, i)
在终端运行,–logdir为文件名,–port为端口名
1 tensorboard --logdir ="logs" --port =6007
writer.add_image()的说明:writer.add_image()输入的图像需要是tensor类型、numpy型或字符串等,需要使用opencv读取图像(numpy型),不能使用Image读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 def add_image ( self, tag, img_tensor, global_step=None , walltime=None , dataformats="CHW" """Add image data to summary. Note that this requires the ``pillow`` package. Args: tag (str): Data identifier 图像标题 img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data 图像 global_step (int): Global step value to record 这是第几步的图像 walltime (float): Optional override default walltime (time.time()) seconds after epoch of event dataformats (str): Image data format specification of the form CHW, HWC, HW, WH, etc. 高H宽W通道C,需要说明图像数据的顺序,opencv读取的图像是HWC格式
使用from torchvision import transforms导入工具箱
用法:一般是将由opencv或Image读取的图片转为tensor
1 2 tensor_trans = transforms.ToTensor()
tensor的数据类型可以理解为包装了神经网络所需要的一些信息,如后向传递、梯度、梯度方法
用法:正态分布的标准化,均值为0,方差为1 ?? 加快梯度下降的方法
output[channel] = (input[channel] - mean[channel]) / std[channel])
1 2 trans_norm = transforms.Normalize([0.5 , 0.5 , 0.5 ], [0.5 , 0.5 , 0.5 ])
可以处理PIL Image的图像(现在应该可以直接处理tensor)
1 2 trans_resize = transforms.Resize((h, w))
用法:将多个变换整合到一个序列中
Compose()的输入是一个列表,列表中的数据是transforms的类型
1 2 3 trans_resize = transforms.Reize(512 ) trans_compose = transforms.Compose([trans_resize, trans_toTensor])img_compose = trans_compose(img)
torchvision — Torchvision main documentation (pytorch.org)
torchvision属于pytorch的一个版本
下载和存储dataset的样例。其中train_set&test_set都是Dataset类的对象
1 2 3 4 5 import torchvision"./Dataset/CIFAR10_dataset" , train=True , download=True )"./Dataset/CIFAR10_dataset" , train=False , download=True )0 ]
使用print(test_set.classes)来显示所有成员
torch.nn — PyTorch 2.0 documentation
torch.nn.Moudle所有神经网络模块的基类,需要自定义一个子类来继承它
1 2 3 4 5 6 7 8 9 10 11 12 import torch.nn as nnimport torch.nn.functional as Fclass Model (nn.Module):def __init__ (self ):super ().__init__() 1 , 20 , 5 )20 , 20 , 5 )def forward (self, x ): return F.relu(self.conv2(x))
torch.nn.Sequential(arg: OrderedDict[str , Module ] )
将网络结构列成一个序列,然后input按照这个序列执行
1 2 3 4 5 6 model = nn.Sequential(OrderedDict(['conv1' , nn.Conv2d(1 ,20 ,5 )),'relu1' , nn.ReLU()),'conv2' , nn.Conv2d(20 ,64 ,5 )),'relu2' , nn.ReLU())
有两种调用方法,第一种是使用torch.nn.Conv2d调用 Conv2d — PyTorch 2.0 documentation
也可以通过import torch.nn.functional as F可以直接调用F.conv2d()
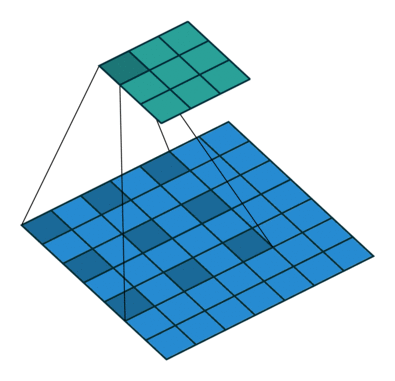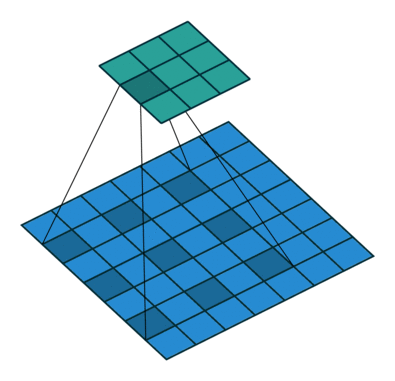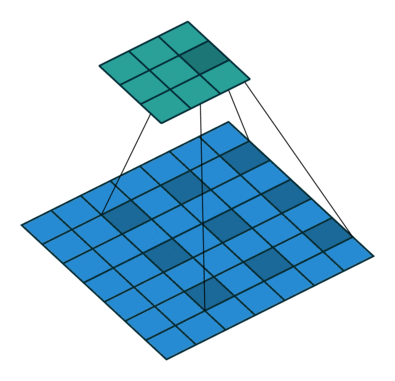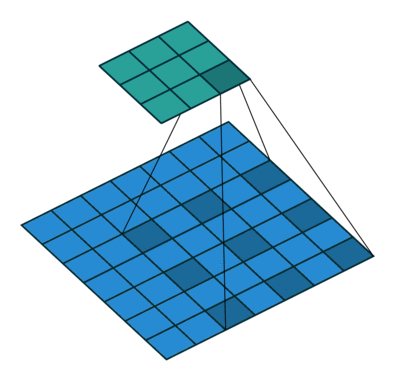
torch.nn.Conv2d(in_channels , out_channels , kernel_size , stride=1 , padding=0 , dilation=1 , groups=1 , bias=True , padding_mode=‘zeros’ , device=None , dtype=None )
kernel_size:定义卷积核的大小,一个整数或元胞数组,整数则是nXn的,数组(n,m)则是nXm的in_channel:指的是输入的图像有几层out_channel:指的是使用几个卷积核来卷积,一个卷积核作为一个通道的输出
dilation默认为1,可以根据这个公式计算论文中需要的一些参数
参数说明 torch.nn.functional.conv2d — PyTorch 2.0 documentation
stride卷积核的移动步长,可以是一个常数或者一个元组(横向步长,纵向步长)input需要输入(batch_size,通道数channel,图像高,图像宽),如果只是一个图像,则需要使用torch.reshape(input,(input_size))来修改size
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchimport torch.nn.functional as Finput = torch.tensor([[1 , 2 , 0 , 3 , 1 ],0 , 1 , 2 , 3 , 1 ],1 , 2 , 1 , 0 , 0 ],5 , 2 , 3 , 1 , 1 ],2 , 1 , 0 , 1 , 1 ]])1 , 2 , 1 ],0 , 1 , 0 ],2 , 1 , 0 ]])input = torch.reshape(input , (1 , 1 , 5 , 5 ))1 , 1 , 3 , 3 ))input , kernel, stride=1 )input , kernel, stride=1 , padding=1 )
nn.Conv2d初步构建神经网络1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import torchimport torchvisionfrom torch import nnfrom torch.utils.tensorboard import SummaryWriterfrom torch.utils.data import DataLoader"DataSet/CIFAR10_dataset" , train=False ,64 , shuffle=True , drop_last=True )class MyNet (nn.Module):def __init__ (self ):super (MyNet, self).__init__()3 , out_channels=6 , kernel_size=3 , stride=1 , padding=0 )def forward (self, input ):input )return output"nn_Conv2d_test" )0 for data in dataloader:"test" , imgs, step)128 , 3 , 30 , 30 ))"con2d_test" , output, step)1
使用print可以打印神经网络的结构:
1 2 3 MyNet(1 , 6 , kernel_size=(3 , 3 ), stride=(1 , 1 ))
torch.nn.MaxPool2d(kernel_size , stride=None , padding=0 , dilation=1 , return_indices=False , ceil_mode=False )
1 self.maxpool1 = nn.MaxPool2d(kernel_size=3 , ceil_mode=True )
ReLu&Sigmoid,非线性变换就是给网络引入非线性特征,非线性越多就可以拟合更复杂的曲线
torch.nn.ReLU(inplace=False )
inplace:当其为True时,会将input的数据直接进行替换且没有输出。通常令其为False
用法
1 2 3 m = nn.ReLU()input = torch.randn(2 )input )
torch.nn.BatchNorm2d(num_features , eps=1e-05 , momentum=0.1 , affine=True , track_running_stats=True , device=None , dtype=None )BatchNorm2d — PyTorch 2.0 documentation
在神经网络中,正则化层是一种用于控制模型复杂度和减小过拟合 的技术。正则化层通过添加额外的约束或惩罚项来限制模型的学习能力,从而提高其泛化能力。
常见的正则化层包括L1正则化(L1 regularization)和L2正则化(L2 regularization)。
L1正则化(L1 regularization):通过添加L1范数作为正则化项来惩罚模型中的参数。L1正则化有助于稀疏化 模型,即将一些参数置为零,从而减少模型的复杂度。
L2正则化(L2 regularization):通过添加L2范数作为正则化项来惩罚模型中的参数。L2正则化有助于减小参数的值,使其更加平滑 ,并减少模型对个别训练样本的敏感性。
正则化层的作用主要有以下几个方面:
控制模型复杂度 :正则化层通过限制模型的参数空间,避免模型过于复杂,从而减少过拟合的风险。减小过拟合 :过拟合是指模型在训练数据上表现很好,但在未见过的测试数据上表现较差。正则化层通过约束模型的学习能力,使其更加一般化,提高模型在未知数据上的性能。提高泛化能力 :正则化层可以帮助模型学习到更具有普适性的特征,从而提高模型在新样本上的泛化能力。
总之,正则化层在神经网络中起到一种正则化和约束模型的作用,有助于防止过拟合,提高模型的泛化性能。
torch.nn.Linear(in_features , out_features , bias=True , device=None , dtype=None )Linear — PyTorch 2.0 documentation
前一个层的某一个神经元为x,当前层的一个神经元为y,这两个神经元相连,计算方式是y = x A T + b y=xA^T+b y = x A T + b
torch.flatten(input)将input摊平为一维数组
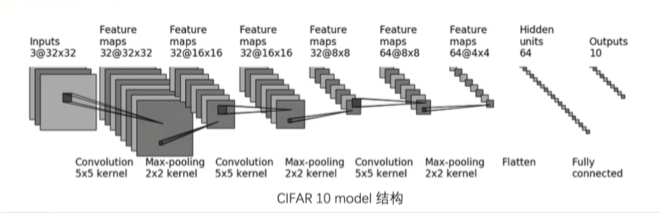
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import torchfrom torch import nnfrom torch.utils.data import DataLoaderimport torchvisionfrom torchvision import datasetsfrom torch.utils.tensorboard import SummaryWriterclass MyNet (nn.Module):def __init__ (self ):super (MyNet, self).__init__()3 , 32 , 5 , stride=1 , padding=2 ),2 ),32 , 32 , 5 , stride=1 , padding=2 ),2 ),32 , 64 , 5 , stride=1 , padding=2 ),2 ),1024 , 64 ),64 , 10 )def forward (self, input ):input )return outputprint (myNet)input = torch.ones((64 , 3 , 32 , 32 ))input )"logs/nn_seq" )input )
torch.nn — PyTorch 2.0 documentation
orch.nn.L1Loss(size_average=None , reduce=None , reduction=‘mean’ )L1Loss — PyTorch 2.0 documentation
1 2 loss = nn.L1Loss()input , target)
要求input和target是同维度的数组
reduction:有’mean’和’sum’,mean是总的loss除以总的个数,sum是总的loss相加
torch.optim — PyTorch 2.0 documentation
优化器的使用方法
构造一个优化器
1 2 optimizer = optim.SGD(model .parameters () , lr=0.01 , momentum=0.9 )Adam([var1 , var2 ], lr =0.0001)
使用案例
1 2 3 4 5 6 7 8 for input , target in dataset:def closure ():input )return loss
完整的模型验证套路_哔哩哔哩_bilibili
torch.save(vgg16, "path") & model = torch.load("path.pth")既保存了结构也保存了参数
torch.save(vgg16.state_dict(), "path") & model = torch.load("path.pth")只保存了模型参数(model是字典形式)
第二种方法是官方推荐的,文件会小一些,参数以字典的形式保存,因此需要对参数进行加载:
1 vgg16.load_state_dict(torch .load ("path" ) )
同时,第一种方法在另外的文件中导入时,仍然需要定义模型的类(module的那个),也可以直接import 这个类
只有网络模型初始化,损失函数初始化,和输入的imgs&targets需要使用GPU(即cuda)(有两种用法)
1 2 3 4 5 device = torch.device("cuda:0" )
注:Google提供了一种免费的GPU(有限时)https://colab.research.google.com/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 import torchfrom torch import nnimport torchvisionfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter"DataSet/CIFAR10_dataset" , train=True , transform=torchvision.transforms.ToTensor())"DataSet/CIFAR10_dataset" , train=False , transform=torchvision.transforms.ToTensor())len (train_set)len (test_set)print ("训练集和测试集的长度分别为{}和{}" .format (len_train, len_test))64 , shuffle=True )64 , shuffle=True )class MyNet (nn.Module):def __init__ (self ):super (MyNet, self).__init__() 3 , 32 , 5 , stride=1 , padding=2 ),2 ),32 , 32 , 5 , stride=1 , padding=2 ),2 ),32 , 64 , 5 , stride=1 , padding=2 ),2 ),64 *4 *4 , 64 ),64 , 10 )def forward (self, input ):input )return output"cuda:0" )"logs/train" )0 0 10 0.005 )for i in range (epoch):print ("------------------当前训练轮数:{}------------------" .format (i + 1 ))for data in train_dataset:1 if train_step % 100 == 0 :print ("训练次数:{},Loss:{}" .format (train_step, train_loss.item()))"train_100" , train_loss, train_step)0 1 0 with torch.no_grad():for data in test_dataset:1 ) == targets).sum ()print ("整个训练集的Loss:{}" .format (total_test_loss))"test_loss" , total_test_loss, test_step)print ("整个训练集的Precision:{}" .format (total_precision / len_test))"test_precision" , total_precision / len_test, test_step)"model/myNet_{}.pth" .format (i))print ("第{}轮模型已保存" .format (i))
labelimg软件 以及 VOC格式
使用../,../意味着从当前文件夹路径返回根目录(返回上一层目录),然后在根目录后重新访问另一个文件夹