IPLV:一种基于帧的鲁棒对应概率局部验证方法

IPLV:一种基于帧的鲁棒对应概率局部验证方法(2022)
摘要:
在两组特征之间建立可靠的特征对应关系是图像处理中的一项基本任务。在本文中,我们提出了一种新的概率局部验证方法来拒绝错误的特征匹配。我们利用局部仿射框架来计算重投影误差,并开发一种新的概率模型来根据误差估计对应置信度。通过基于两层混合模型计算后验概率来评估对应置信度。可以通过交替最大化和更新第二个下界函数来自适应地估计所提出方法的关键参数。我们还建议相邻的内部邻居是好邻居,从而提出了一种置信距离比策略来平衡内部置信度和空间距离。我们的方法在无人机定位任务的成功率上比其他最先进的方法大多超过十个百分点,在多个公共测试数据集上的 F-measure 上超过六个百分点。该代码可在 https://github.com/shenliang16/Iterative-Probabilistic-local-Verification 获得。
关键词:位置保持匹配、 鲁棒特征对应、 异常值剔除、 失配去除、 无人机定位、 基于图像的定位、 特征匹配
1. 引言
匹配给定场景的两个或多个视图是图像处理任务中的一个基本问题,例如图像配准和基于图像的定位。该任务的第一个解决方案是使用基于区域的方法 (Ma et al., 2021a, 2015),例如互相关,来计算相似度以找到最相似的对应关系。该解决方案通常对成像条件和几何变形敏感,并且计算成本高(Ma et al., 2021a)。为了解决这些问题,**基于特征的匹配(FBM)**得到了广泛的研究,旨在建立从图像中检测到的两组局部特征之间的可靠特征对应关系。 FBM 方法通常包括两个连续的步骤——特征检测和特征匹配。1 前者从图像中提取显着特征,后者在两个特征集之间进行匹配以建立对应关系。在特征检测中,最著名的方法可能是 SIFT (Lowe, 2004)。它包括DoG检测器和SIFT描述符,是尺度和旋转不变的。 SIFT 的一个流行替代方案是 SURF (Bay et al., 2006),它使用 Haar 小波的响应来加速 SIFT 算子。在实时应用中(MurArtal et al., 2015),FAST 和 ORB 被更普遍地使用,它们通常比 SIFT 快几个数量级。
近年来,基于深度学习的检测器和描述符变得越来越流行。 2017 年,田等人提出了 L2-Net (Tian et al., 2017),它使用渐进式采样策略优化了基于欧几里德距离的损失函数。 HardNet (Mishchuk et al., 2017) 使用铰链三元组损失优于 L2-Net,这在比较研究中被证明是最先进的 (Jin et al., 2020)。 HesAffNet (Mishkin et al., 2018) 可以学习局部仿射协变区域,以解决视点变化的鲁棒性。其他流行的基于学习的检测器包括 D2-Net (Dusmanu et al., 2019)、R2D2 (Revaud et al., 2019)、SOSNet (Tian et al., 2019) 和 ContextDesc (Luo et al., 2019)。在这些方法中,DeTone 等人(2018)提出了超点自发表以来受到广泛关注,实现了检测器的自监督训练。与著名的强力胶结合使用时,它显示出非常有前途的性能(Sarlin 等人,2020)。此外,最近变压器也被用于这项任务(Jiang et al., 2021; Sun et al., 2021)。
特征检测之后,问题就变成了如何匹配特征并验证对应关系。有多种方法可以解决这个问题(Wang 等人,2014;Jiang 等人,2019a;Sarlin 等人,2020;Jiang 等人,2021),其中最常见的解决方案可能是使用两个-step 框架(Ma et al., 2018b; Bian et al., 2005; Ma et al., 2014; Lin et al., 2018; Ma et al., 2019, 2015)。在两步框架中,第一步是通过计算特征相似度来建立假定的对应关系。由于图像变换和重复模式,假定的对应集不可避免地包含许多错误匹配,即异常值。要解决此问题,需要进行不匹配消除的后处理。
错配去除 (Ma et al., 2013),也称为异常检测 (Cavalli et al., 2020) 和对应选择 (Zhao et al., 2020),是指去除错误匹配并保留正确匹配,即内点,在假定的对应集中。该任务的一个基本方法是比率测试 (Lowe, 2004)。它认为可靠的对应关系应该比第二近的对应具有明显更近的描述符距离 (Lowe, 2004)。比率测试方法虽然简单高效,但缺乏鲁棒性,仅用作粗略的预处理技术(Lin et al., 2014; Ma et al., 2018a)。为了进一步提高鲁棒性,通常需要检查假定对应的几何一致性。 RANSAC (Fischler, 1981) 是该任务中最具代表性的一种,它假设某个全局变换模型并重复估计模型参数以拒绝高重投影误差的匹配。最近,邻域共识因其简单和高效而受到广泛关注(Bian et al., 2019b, 2005; Ma et al., 2018b)。这些方法在许多任务中都表现出了最先进的性能,例如图像配准(Ma et al., 2018a)、基本矩阵估计(Bian et al., 2019b)和宽基线匹配挑战(Cavalli et al., 2019)。 , 2020)。然而,当存在大规模几何变换或严重异常值时,邻域共识通常难以衡量。同时,当前许多邻域共识方法都非常依赖于经验参数设置,例如 LPM (Ma et al., 2018b)、GLPM (Ma et al., 2018a)、LGSC (Jiang et al., 2022)、mTopKRP (姜等人,2019b)。为了解决这些问题,本文提出了一种自适应且鲁棒的邻域共识方法来消除不匹配。我们利用局部仿射框架、描述符相似性和空间距离来有效地验证假定对应关系的局部一致性。所提出的方法的亮点是:
-
我们提出了一种概率局部验证方法来衡量邻域共识。该方法具有很强的适应性,因为可以在没有经验设置的情况下估计关键参数。
-
利用自由的局部仿射框架信息来测量邻域一致性,使该方法对几何变换具有鲁棒性。这种开发也提高了适应性,因为由于局部仿射框架的仿射不变性,不需要经验多尺度过程。
-
我们建议相邻的内部邻居是好邻居,并提出了一种置信距离比策略来平衡空间相关性和正确的置信度。
所提出的方法明显优于许多最先进的方法,如 LPM、GMS-SR、OA-net 和 AdaLAM,尤其是在基于图像的无人机定位任务方面。该提议对大规模几何变换和初始参数设置也非常稳健。该代码可在 https://github.com/shenl iang16/Iterative-Probabilistic-local-Verification 获得。
2. 相关工作及准备工作
2.1 相关工作
在本节中,我们将回顾错配消除的相关方法。相关方法可分为参数和非参数两种。参数方法搜索由参数几何模型定义的一致对应关系。代表性的参数化方法包括著名的随机抽样共识 (RANSAC) (Fischler, 1981) 及其变体 — 渐进抽样共识 (PROSAC) (Chum 和 Matas, 2005)、极值抽样共识 (EVSAC) (Fragoso et al., 2013) ,随机样本共识的通用框架 (Raguram et al., 2013)、LO-RANSAC (Chum et al., 2003) 和 MAGSAC (Barath et al., 2019)。 RANSAC 不断选择一些随机样本来计算试验全局变换,并通过计算具有低拟合误差的对应数量来评估试验全局变换。然后根据最佳全局变换下的拟合误差去除不匹配。 PROSAC 采用加权抽样策略而不是随机抽样来确定样本。高有希望的对应关系更有可能被选择,从而提高了效率。 EVSAC 使用极值理论来加速假设的产生。在 MAGSAC 中,作者提出了一种称为 𝜎-consensus 的方法来自动确定 RANSAC 中的距离阈值。此外,一些方法(Ma et al., 2017; Yue et al., 2018)还使用粒子群优化算法等进化算法来寻找最优解,成功率高但效率低。当可以对所研究图像之间的真实变换进行全局建模(例如,投影变换)时,上述参数方法是有效的。但是,当转换过于复杂而无法使用参数模型进行建模时(尤其是在具有局部变形的情况下),参数方法变得无效并且需要非参数方法。
代表性的非参数方法包括谱技术(Leordenu 和 Hebert,2005)、基于图的匹配(Wang 等人,2014;Rana 等人,2018)、非参数插值方法(Ma 等人,2014; Tao and Sun, 2015; Ma et al., 2015)、邻域共识方法 (Ma et al., 2018b; Bian et al., 2005; Cavalli et al., 2020) 和基于学习的方法 (Yi et al., 2018;赵等人,2019;张等人,2019)。具体来说,Leordenu 和 Hebert (2005) 提出的光谱技术 (Leordenu 和 Hebert, 2005) 采用基于亲和矩阵的几何约束来使用 𝓁2 范数来区分异常值。在基于图的方法中,重加权随机游走算法 (Cho et al., 2010) 是一种众所周知的方法,它使用马尔可夫链来解决问题。在阿尔巴雷利等人。 (2012),不匹配消除问题通过博弈论框架解决,称为博弈论匹配(GTM),其中内点选择是通过强制一些半局部几何约束来引导的。 Ma等人(2014)提出的VFC在两个点集之间插入一个向量场来估计共识。 Ma 等人(2015)开发了一种局部线性变换策略保留局部性并拒绝遥感图像上的不匹配。深度学习也被用于这项任务(Yi et al., 2018; Zhao et al., 2019; Zhang et al., 2019)。 Yi等人(2018)的作者使用多层感知通过分类预测匹配的正确性。赵等人提出了一个分层网络,通过挖掘可靠邻居来消除错误匹配。张等人(2019)提出了一个订单感知网络(OAnet)来推断正确性的概率并回归基本矩阵。
最近,邻域共识方法变得越来越流行,例如基于网格的运动统计(GMS)(Bian et al., 2005)、局部保持匹配(LPM)(Ma et al., 2018b)及其变体(Ma等人,2018a;Jiang 等人,2019b,2022;Ma 等人,2022)和自适应局部仿射匹配(AdaLAM)(Cavalli 等人,2020)。这些方法验证本地邻域共识以消除不一致的匹配。背后的想法是只有相邻的内点在转换前后是一致的,这样我们就可以通过测量一致性来识别内点。在这些方法中,首先考虑为相邻的内点对应保留局部结构。然后,他们依次验证每个对应关系的共识。具体来说,GMS (Bian et al., 2005) 通过将运动平滑假设建模为统计测量来选择置信对应。它假设内部对应具有比异常值更多的支持邻居。 GMS 的缺点是需要先验的缩放和旋转信息来确定支持区域,导致难以处理复杂的几何变换。与 GMS 不同,LPM 由于物理约束,假设相邻对应的拓扑和结构是一致的,可以处理旋转和缩放。但是,当存在大量异常值时,LPM 可能会退化(Ma et al., 2021b),如果局部区域包含的异常值太少,则可能会出现问题(Zhao et al., 2020)。为了解决严重的异常值,Zhao 等人(2019)建议通过搜索兼容的邻居来提高邻居的质量。然而,这种方法需要为每一个对应关系详尽地搜索兼容的邻居,非常耗时。 AdaLAM (Cavalli et al., 2020) 是一种涉及邻域共识 (Sattler et al., 2009) 和几何验证 (Fischler, 1981) 的集成方法。 AdaLAM 利用尺度和方向信息来选择可靠的邻居。但是,它需要很好地预设参数和阈值,有时会导致准确率和召回率之间的平衡不足。总体而言,当存在大量异常值和重大转变时,当前的邻里共识措施通常会变得无效。此外,许多相关方法需要良好的参数集,缺乏适应性。
2.2 准备工作
局部仿射帧 (LAF) 由仿射协变检测器检测,例如 MSER (Matas et al., 2004)、Hessian-affine (Mikolajczyk and Schmid, 2004),以及像 HesAffNet (Mishkin et al., 2018) 这样的学习型检测器)。它在宽基线匹配中非常有效,因为它是仿射不变的(Vedaldi 和 Fulkerson,2008;Mishkin 等,2018;Eichhardt 和 Barath,2019)。如图 1 所示,LAF 可以表示为一个定向日食,其中中心是特征位置,半径和线方向分别表示尺度和方向。如果我们有一个 LAF 对应关系,我们可以计算一个局部仿射变换,表示两个匹配特征周围的两个局部图像区域之间的相对变换。局部仿射框架可以看作是相关单应矩阵的一阶局部近似(Baráth and Kukelova,2019)。即使真正的全局变换是投影,它也可以有效地对变换进行局部建模(Barath et al., 2019; József et al., 2014)。
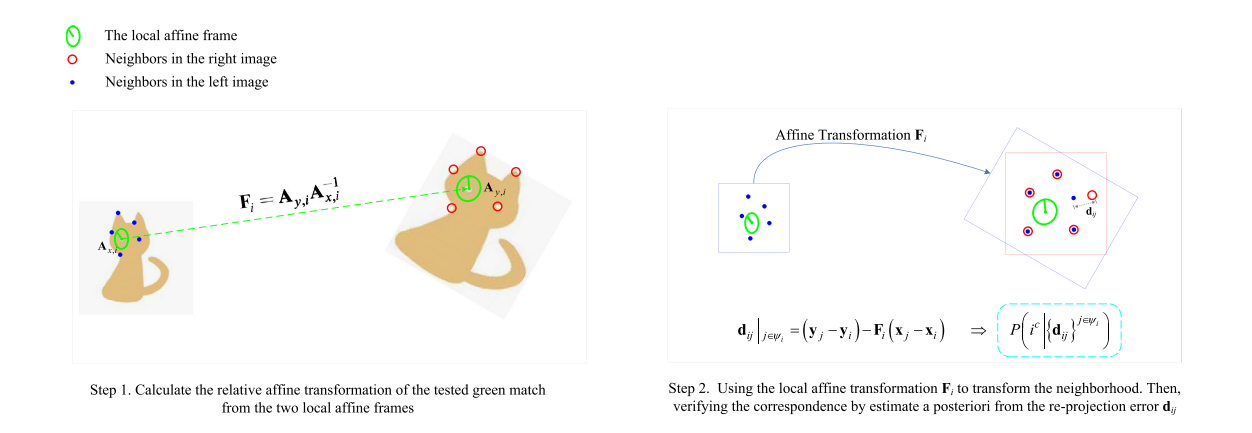
图1. 我们基于 LAF 的局部验证的图示。我们首先从两个匹配的局部仿射帧计算局部仿射变换。然后,基于局部仿射变换,局部一致性通过重投影误差来衡量。由于局部仿射变换是仿射不变的,因此我们不需要经验多尺度过程。
请注意,比例和旋转不变检测器,例如SURF (Bay et al., 2006) 或 SIFT (Lowe, 2004),只有一部分仿射帧。4 在这种情况下,我们可以将 LAF 近似为,其中𝑠 ∈ R+ 是特征尺度,而𝐑 ∈ R2×2 是编码特征方向的旋转矩阵。
3. 提出的不匹配删除
本节分为三个部分。首先,我们利用局部仿射框架信息通过概率模型测量邻域共识。其次,我们提出了一种置信距离比策略来选择更好的邻居。最后对参数自适应进行了研究。
3.1 基于 LAF 的局部验证的概率建模
给定从图像和图像检测到的两组局部特征,首先使用SIFT等描述符建立假定的对应集。相应的 LAF也可以同时得到。然后,我们可以从两个对应的 LAFs 计算局部仿射变换

其中是一个没有平移的线性映射,描述了两个匹配特征周围两个对应的局部图像区域之间的局部几何变换。请注意,LAFs和局部仿射变换不需要翻译项,因为我们将在 (2) 中执行集中化。将对应关系的 𝑘 选定邻居表示为,其中是索引集。然后,我们将通过验证和之间的几何一致性来估计的正确性。
由于局部仿射变换是已知的,我们可以将邻域点从一幅图像重新投影到另一幅图像。因此,我们计算以下局部仿射重投影误差来衡量邻域共识,其中较小的值表示更好的共识和高概率是内部对应。

其中和对相邻特征点进行集中处理。与仅考虑空间位置的 LPM (Ma et al., 2018b) 中的距离测量不同,方程 (2) 基于局部仿射帧信息,本质上是仿射不变量,无需像 (Ma et al., 2021b; Li et al., 2019) 那样构建手工仿射不变量。
然后,我们提出了一个概率模型来衡量来自的一致性,以验证对应关系𝑖。为此,我们将重投影误差视为遵循某个分布的随机变量,并将视为观察值。然后,在先验分布的可选假设下,可以通过根据观察结果计算后验概率来评估对应关系。在下面的推导中,我们直接用𝑖和𝑗来表示要验证的匹配及其邻居。我们将上标𝑐和上标𝑓分别表示为正确匹配(inliers)和错误匹配(outliers)。
对于内点,我们考虑条件概率涉及两个子事件:(1)邻居 𝑗 是异常值; (2) 邻居 𝑗 是一个内点。让我们将它们与一个潜在变量联系起来:
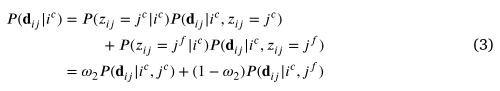
其中和分别表示两个子事件的概率;是表示选择内部邻居的先验概率的权重。对于异常匹配,我们忽略了内部邻居和异常邻居之间的差异,并简单地假设概率对邻居的正确性是不变的。然后,总概率可以通过进一步关联和与另一个潜在变量,其中表示已验证的对应关系是内点
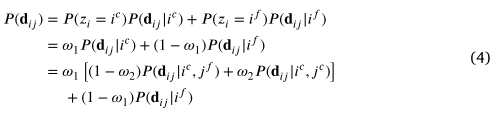
其中是表示匹配正确的先验概率的权重。基于 (4) 中的概率,我们现在可以通过使用贝叶斯定理基于观察估计后验概率来验证每个对应关系
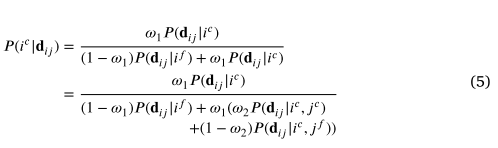
请注意,方程式(4)表示具有单个邻居的分布,因此,等式 (5) 中的估计由于缺乏观察,可能不可靠。为了提高鲁棒性,我们将考虑更多的邻居。考虑到有 𝑘 邻居,我们假设它们是独立的,并将从 𝑘 邻居计算的观察值表示为。那么, 的联合概率可以表示为:
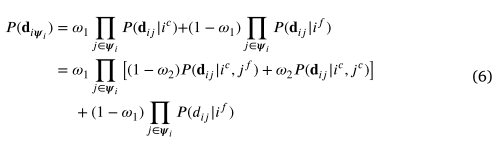
因此,后验概率变为
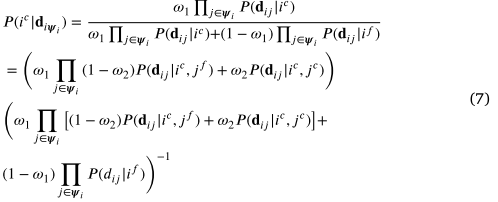
为了使问题易于处理,应该做出先验分布的假设。当验证的对应 𝑖 和邻居 𝑗 都是内点时,我们考虑二维高斯分布,否则考虑均匀分布。表示为高斯分布的方差,为均匀分布。然后,后验由下式计算
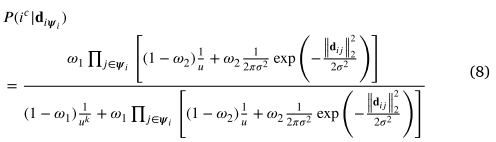
后验概率表示匹配正确的置信度。因此,我们将低置信度的对应视为不匹配,并将它们删除以实现稳健的对应。如算法 1 中所述,这种方法以线性时间和空间复杂度顺序工作(忽略使用 knn 搜索邻居的步骤)。
3.2 置信距离比邻居
邻域是基于局部共识的方法的基础。邻居质量差(即内部邻居太少)会显着降低性能。针对这个问题已经提出了许多好的策略(Ma et al., 2018a; Cavalli et al., 2020),我们还提出了一种平衡解决方案。
要选择更好的邻居,第一个问题是定义什么是好邻居。我们知道,我们想要选择更好的邻居是由于大量的异常值。如果异常值很少,我们可以使用最近的邻居,如 LPM 和 GMS(Ma et al., 2018b; Bian et al., 2005)。为了找到好邻居,我们考虑两个因素——内部置信度和空间距离。
- 内在信心。一般来说,邻域共识只对内点有效,而异常点通常不是共识(这就是为什么我们可以通过检查共识来区分内点和异常点)。因此,我们应该考虑如何选择具有更好内点置信度的邻居,这会导致鸡与蛋问题,因为我们的最终目标也是选择内点。
- 空间距离。在选择好邻居时还应考虑空间距离,因为通常只有相邻的对应关系是一致的。如果两个对应关系相距很远,则可能没有共识,如图 2 所示。

图2. 一个极端的例子来说明为什么我们应该选择相邻的邻居。图中四个对应都正确,但只有相邻的一致。例如,两个左上对应都是从左到右放大的,所以它们是一致的,因为它们经历了相似的变换。但是将它们与右下的进行比较,我们发现由于距离较大,我们没有达成共识(因为右下的被放大了)。
综上所述,这两个因素要求我们应该选择相邻的内部邻居来衡量邻域共识。为此,我们提出了一种简单的策略,称为 Confidence-Distance-Ratio (CDR)。该策略有点像进化算法中的适应度距离比策略(Peram et al., 2003; Li, 2007; Qu et al., 2014; Liang et al., 2014),它计算适应度和距离以寻找更好的局部邻居以在进化中学习。我们的 CDR 策略计算内部置信度和空间距离之间的比率,以平衡两个因素,如方程式(9) 显示。选择具有最高 CDR 分数的 𝑘 邻居。
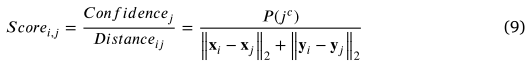
其中是邻居 j 的内部置信度,表示邻居正确匹配的概率。和是两幅图像的空间距离。在实现中,我们评估 50 个空间最近邻居的分数,以找到顶部 𝑘 CDR 邻居。
在策略中,问题是如何获得邻居的内部置信度。为了解决这个问题,我们首先利用基于描述符的比率测试值作为第一次迭代中内部置信度的先验指标(Ma et al., 2018a; Cavalli et al., 2020)。(比率越小,是内点的可能性越高)

其中𝑟𝑗是对应关系𝑗的比率检验值。该策略的效果如图 3 所示。
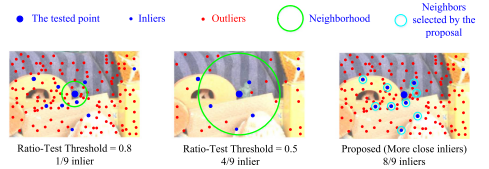
图3. 使用 CDR 策略找到相邻的内部邻居(在第一次迭代中)。左图找到了具有宽松比率测试阈值的空间最近邻居。它找到空间上近邻,但只有 1 个内点。中间的数字使用严格的阈值,发现更多的内点。但是几个相邻的内部邻居丢失了。右图显示 CDR 策略平衡了空间相关性和内部置信度。
在第一次迭代之后,我们可以通过等式 (8)中估计的后验来定义内部置信度。
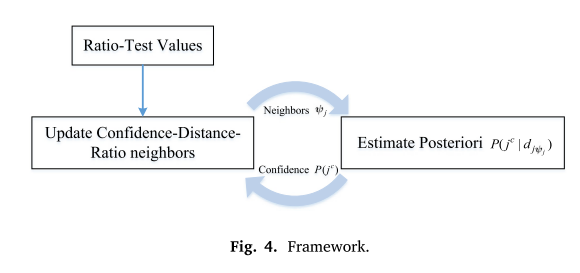
现在,我们可以交替搜索和更新更好的邻居来解决鸡生蛋问题,同时考虑内部置信度和空间距离。该算法通过交替估计内部置信度(后验概率)和搜索置信距离比邻居来运行,如图 4 所示。在实践中,我们发现 2 次迭代就足够了。
3.3 参数适配
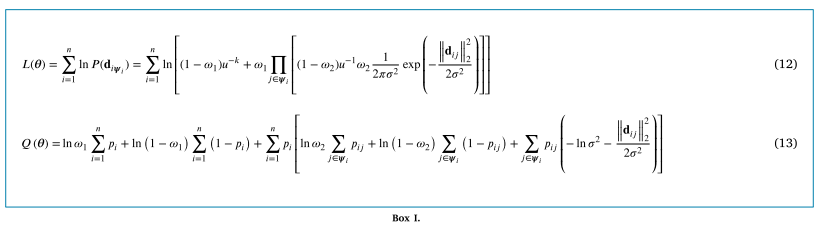
基于上述推导和讨论,该提案已经可以使用给定的参数,如 LPM (Ma et al., 2018b) 和 GMS (Bian et al., 2005)。但是为了提高适应性和鲁棒性,我们进一步估计了参数。让我们将𝜔1、𝜔2和𝜎重新参数化为𝜽,并基于i.i.d数据假设在(12)中编写对数似然函数。
然后可以通过最大化(12)来估计参数。期望最大化 (EM) 是优化的常用解决方案,但它不能像 (Ma et al., 2014; Myronenko and Song, 2009) 那样直接在这里使用,因为存在两层潜在变量。为此,我们将通过两次应用 Jensen 不等式来生成 𝑄 函数来构建“第二个”下界函数 (13)。方程 (12) 和 (13) 在方框 I 中给出。
(13)中的是(8)使用先前参数计算的后验概率。是邻居𝑗成为内部邻居的后验概率。在这里,我们简单地分别处理它们,并在第二层通过贝叶斯定理计算,如(14)所示。
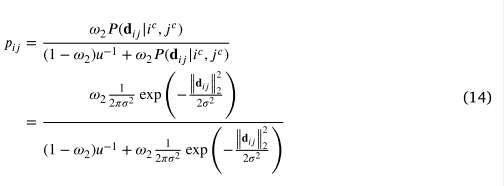
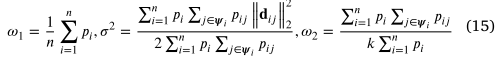
通过让 𝑄 的相应导数为零来估计参数,如 (15) 中给出的。在实现中,该算法交替使用(8)和(14)(E步)计算后验概率,并通过使用(15)(M步)最大化第二个下界函数来更新参数,直到收敛。显然,迭代逐步更新并最大化下界函数以最大化(12),这是单调和有界的。
4. 实施和实验设置
4.1 成果
我们将所提出的方法命名为迭代概率局部验证(IPLV)。算法1中给出了实现。由于自适应估计,我们应该只设置参数的初始值,具体为𝑘 = 8,𝜔1 = 𝜔2 = 0.3,和𝜎 = 10−2。请注意,性能对初始参数不敏感,如第 5.3.3 节所示。在运行 IPLV 时,我们在 IPLV 的最大迭代次数为 5 或目标函数的相对变化小于 10−2 时停止迭代。最终的概率决策阈值为 0.5。在运行该方法之前,首先根据 Hartley 和 Zisserman (2003) 对关键点进行归一化。此外,第 5.3.1 节还进行了消融研究,以展示算法中组件的有效性。

4.2 实验装置
本节定量评估所提出的方法。三个大型无人机定位数据集和四个额外的公共数据集被选为测试数据。表 1 和图 5 显示了数据集的描述和一些示例图像。


三个大型无人机定位数据集来自 Mughal 等人(2021 年)。数据集分别来自 NUST、伊斯兰堡、DHA、拉瓦尔品第和古杰尔汗区,总面积为 182.6 万平方米。这三个数据集共包含 2252 个图像对。查询图像大小为 336 × 224,而地图大小如表 1 所示。这些数据集中的主要挑战是特征少、光照变化和重复模式。
四个附加数据集用于对常见图像进行综合评估。四个流行的数据集是 VGG (Mikolajczyk et al., 2005)、Heinly (Heinly et al., 2012)、Symbench (Hauagge and Snavely, 2012) 和 COLMAP (Zhao et al., 2019)。 VGG 数据集包括 8 个不同挑战的场景,涉及模糊、视点变化、光线变化、JPEG 压缩等。**根据给定的单应矩阵生成 ground-truth,误差阈值为 5 个像素。**Heinly 用于测试几何变换的性能。它是根据 Heinly 等人(2012)提出的数据集建立的 ,包括 29 个图像对。有四个场景 - “威尼斯”、“森佩尔”、“罗马”和“天花板”,其中“威尼斯”涉及缩放,其他三个涉及旋转。地面实况也是根据提供的单应变换矩阵生成的,误差阈值为 5 个像素(Zhao et al., 2020)。 Symbench 数据集 Symbench 是一个非常具有挑战性的数据集,具有大量异常值,主要是由于显着的外观变化。有 46 个图像对,提供的单应变换也用于确定准确度,误差阈值为 5 个像素。 COLMAP 数据集是一个著名的 Structure-from-motion 数据集(Zhao et al., 2019)。该数据集也非常具有挑战性,因为有许多重复的模式,例如窗户和砖块,这通常会导致比率测试无效。它由大量连续图像组成,我们从人物子集中选择前 200 个图像对进行实验。在评估中,ground truth 由相应的极线距离确定,阈值为 0.003,使用 Bian 等人的方法(2019b)。
对于定量评估,主要使用 Precision §、Recall ®、Fmeasure (F)、Localization Success Rate (LSR) 和 Run Time 等指标进行评估。精度定义为最终保留对应集中的真阳性的比率,而召回率是指保留的真阳性与假定对应集中所有潜在真阳性的比例。 F-measure 是准确率和召回率的加权调和平均值,显示了整体性能。它由下式计算
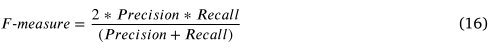
有效的定位需要良好的精度和最少数量的正确匹配来计算相对变换。因此,如果至少有五个正确匹配且精度高于 50%,我们认为定位是成功的。然后,数据集上的 LSR 由下式计算
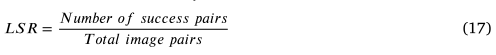
在提案和五种最先进的方法之间进行比较,包括 LPM (Ma et al., 2018b)、GMS (Bian et al., 2005)、GMS-SR (Bian et al., 2019a)、OA- net(Zhang 等人,2019)和 AdaLAM(Cavalli 等人,2020)。 AdaLAM 和学习方法 OA-net 在宽基线图像匹配挑战中显示出最先进的性能。比较方法的所有代码均来自公共资源,其中 LPM 和 IPLV 在 MATLAB、AdaLAM 中实现用python实现,GMS和GMS-SR用C++实现。 VLfeat 工具箱(Vedaldi 和 Fulkerson,2008)中的 covdet 检测器和 SIFT 描述符用于检测特征。假定的对应集在比率测试中粗略选择,阈值为 0.9,以排除极差的对应集。
5. 实证结果分析
5.1 无人机定位数据集的结果
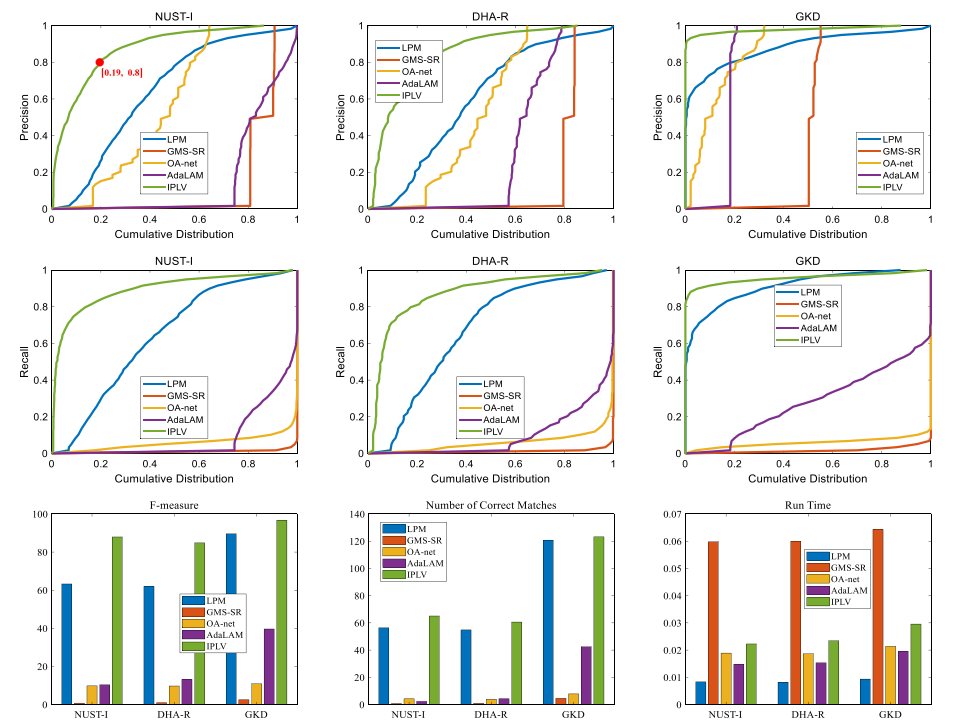
图6. 三个无人机定位数据集的定量性能。在前两行中,这些数字显示了准确率和召回率的详细累积分布。例如,左上图中线条上的红点 [0.19, 0.8] 表示对于 IPLV,精度小于 0.8 的结果的比例为 0.19,即𝑃(𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 < 0.8) = 0.19。曲线向左上方弯曲得越多,其性能就越好。从结果中,我们看到 IPLV 在所有情况下都比其他方法获得了很大的改进。在底行中,绘制了平均 F 测量值。此外,还比较了方法的正确匹配数和运行时间。
首先,我们分析无人机定位数据集的性能。由于很难单独呈现所有 2252 个图像对的结果,我们在图 6 的前两行中绘制了所有精度和召回值的累积分布。图中,纵坐标表示度量阈值,而横坐标表示累计比例。曲线向左上方弯曲得越多,它表示的性能就越好。
总体而言,我们看到 IPLV 在比较中占主导地位,其累积分布曲线位于前两行所有子图中的最左上角。它不仅显着优于所有比较方法,而且很少得到坏结果(证据是 IPLV 的曲线在所有子图中都显着增长,表明 IPLV 的坏结果比例,例如精度/召回率 < 0.4,非常低)。至于比较方法,发现OA-net在所有三个数据集上都显示出相当的精度,但它的召回值非常低。 AdaLAM 仅在数据集 GKD 上的精度表现相对较好,在所有其他情况下似乎无效。相反,LPM 在这项任务上似乎令人满意,显示出非常平衡的精度和召回率。此外,从图 6 的右下方,我们看到所有这些方法都非常有效。 IPLV 的计算时间接近于 OA-net 和 AdaLAM。
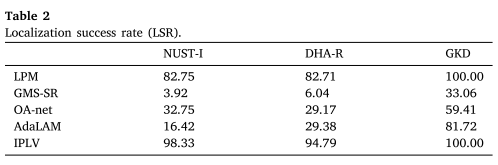
表 2 报告了 LSR 结果。提出的 IPLV 在所有数据集上均排名第一,分别成功定位了三个数据集中 98.33%、94.79% 和 100% 的图像对。 LPM 在 NUST-I 数据集和 HUA-R 数据集上分别比 IPLV 低 15.58% 和 12.08%,排名第二。从图 6,我们知道 OA-net 和 GMSSR 总是很少得到正确的匹配。结果,它们都显示出不好的结果。 AdaLAM 在 NUST-I 和 DHA-R 数据集上表现不佳,但在 GKD 数据集上相对令人满意。图 7 可视化了一些匹配和定位结果。

图7. 无人机定位数据集上匹配和定位结果的可视化。最上面一行显示了查询图像和地图之间的特征匹配,而最下面一行显示了所提出方法的部分定位结果。图中青色线条和圆圈是根据特征匹配的路线和估计位置。此外,一些相应的查询图像被放置在侧面。红色虚线表示查询图像在地图中的位置。
5.2 四个附加数据集的结果

在本节中,将在四个附加的综合数据集上进一步评估所提出的方法。表 3 显示了每个数据集的平均精度、召回率和 F-measure,其中最佳结果以粗体显示。我们首先可以发现,IPLV 在除 Symbench 之外的所有数据集上都优于其他方法,Symbench 表现出最佳的整体性能。 F-measure 值分别增加了 9.58%、7.04% 和 6.94%,在 VGG、Heinly 和 COLMAP 上位居第二。即使在 Symbench 数据集上,IPLV 也只输给了 OA-net,在所有指标上排名第二。 LPM 在 VGG、Heinly 和 COLMAP 数据集上显示了召回率和精度之间的平衡性能。然而,它在数据集 Symbench 上非常无效,准确率和召回率分别只有 12.11% 和 8.77%。就表 3 中的所有指标而言,GMS 在 VGG 和 Heinly 数据集上的性能最差,在 Symbench 和 COLMAP 上的性能倒数第二。与 GMS 相比,GMS-SR 实现了整体增强,但其结果都无法与 IPLV 相提并论。 AdaLAM 在精度方面表现出色,尤其是在 Heinly 数据集 (99.63%) 上。然而,它在所有四个数据集上的召回值都远低于 IPLV,四个数据集上的差异分别高达 26.33%、51.16%、24.63% 和 18.08%。图 8 可视化了一些匹配结果。

图8. 四个数据集上的示例视觉结果。正确匹配用蓝线表示,而错误匹配用红线表示。
5.3 进一步的分析
在本节中,我们进一步分析所提出的方法以验证其有效性。
5.3.1 消融研究
我们的方法包含三个组成部分——基于概率 LAF 的局部验证、CDR 策略和参数自适应。我们将研究这些组件以确认它们的有效性。为此,我们评估了三个版本——概率局部验证 (PLV)、迭代概率局部验证 (IPLV) 和具有置信度-距离-邻居的迭代概率局部验证 (IPLVCDR) 以检查差异。我们在图 9 中显示了所有三个无人机定位数据集的平均精度、召回率和 F-measure。通过将 IPLV 与 PLV 进行比较,发现参数自适应是有效的,因为精度和召回率都得到了提高。这与 CDR 策略相同,因为 IPLV-CDR 的性能也明显优于 IPLV。此外,这两个组件对于提高召回率都特别有用。
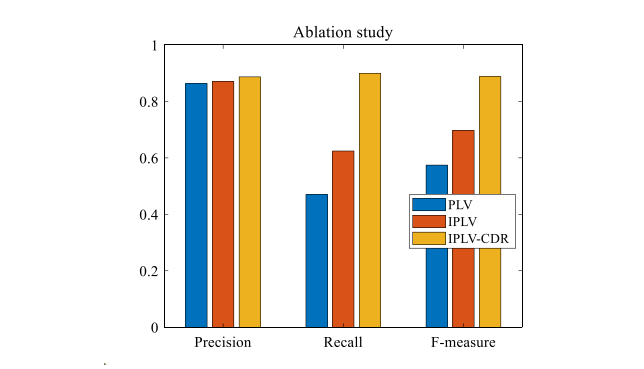
图9. 对所提出方法的不同设置进行消融测试。报告了三个无人机定位数据集中所有 2252 个图像对的平均精度、召回率和 F-measure。
- PLV:既没有CDR邻居也没有参数自适应的方法。
- IPLV:有参数适配但没有CDR 邻居的方法。
- IPLV-CDR:同时具有CDR 邻居和参数自适应的方法(这是前面部分中所谓的IPLV)。
5.3.2 大规模转换的性能
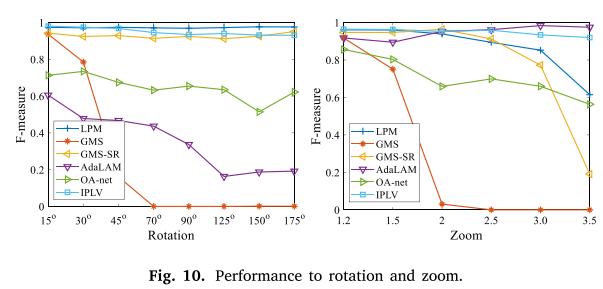
在本小节中,我们使用 Semper 和 Venice 数据集(来自 Heinly 等人(2012))分析了对大规模转换的鲁棒性。我们在图 10 中将 F-measure 结果绘制到不同的旋转度和缩放比。结果表明,IPLV 保持稳定,在所有旋转度和缩放比下获得接近于一的 F-measure 值,显示出出色的鲁棒性。在比较的方法中,LPM、GMS-SR 和 AdaLAM 也获得了良好的性能。 LPM 和 GMS-SR 在旋转方面与 IPLV 相当,但随着缩放比从 2.5 增加到 3.5,它们的 F-measure 值显着下降。 AdaLAM 对缩放非常健壮,在极端情况下甚至略微优于 IPLV。但是,它在处理轮换方面比 IPLV 差得多。 OA-net 没有获得显着的 F-measure 值,但它的性能似乎对旋转和缩放都很稳定。
5.3.3 参数分析
接下来,我们在初始参数设置下测试 IPLV 的性能。参数 𝑘、𝜔1、𝜔2 和𝜎如图 11 所示进行了研究,总共进行了 30 次测试以在各种初始参数设置下测试 IPLV。 VGG 数据集被用作测试数据,因为它涉及全面的挑战和场景。
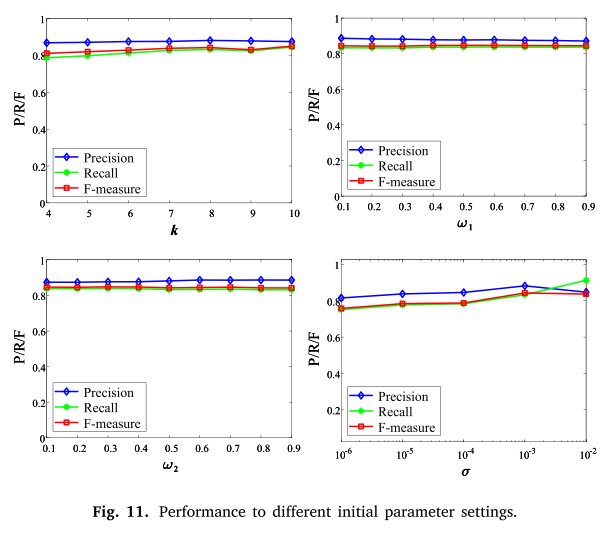
一般来说,我们看到 IPLV 的性能对于所有指标的所有参数都非常稳定,即使在极端情况下(例如,𝜔1 = 0.1)。在这些参数中,IPLV 对 𝜔1 和 𝜔2 的鲁棒性特别强,因为当这两个参数从 0.1 增加到 0.9 时,性能几乎没有变化。在 F-measure 方面,通过将 𝑘 从 4 增加到 8 可以观察到轻微的改善,而当我们将 𝑘 从 8 增加到 10 时没有看到明显的变化。至于 𝜎,当 𝜎 从到 。
6. 结论
在本文中,我们提出了一种用于特征对应的稳健且自适应的不匹配消除。我们提出了一种基于局部仿射帧信息的仿射不变邻域一致性度量,并建立了一个具有相邻内邻点的概率模型来评估对应关系。概率模型涉及两层潜在变量,特征匹配的正确性可以简单地通过具有线性时间和空间复杂度的贝叶斯定理来评估(通过knn搜索邻居,这是线性的)。可以自适应地估计参数以提高适应性和性能。我们还提出了一种置信距离比策略,通过平衡空间相关性和内部置信度来选择相邻的内部邻居。各种实验表明,我们的方法比许多其他最先进的方法表现得更好,尤其是在无人机定位任务中。