机器学习大作业
给定房屋租金价格的各个影响因素数据,建立模型预测国内某城市房屋的租金价格。
(1)ID:编号;
通过计算MSE来衡量回归模型的优劣。MSE越小,说明回归模型越好。
from sklearn.metrics import mean_squared_error
y_true = [1, 2, 3, 4]
y_pred = [1.1, 2.2, 3.3, 4.4]
score = mean_squared_error(y_true, y_pred)
由于多数特征与Label之间的相关性不强,应考虑从原始数据中构建新的特征,以此来优化模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pdimport numpy as npfrom numpy import nan as NaNimport matplotlib.pyplot as plt'font.sans-serif' ]=['SimHei' ]'axes.unicode_minus' ]=False import seaborn as snsimport warnings'ignore' )from sklearn import linear_modelimport lightgbm as lgbimport xgboost as xgbimport catboost as cbfrom sklearn.model_selection import train_test_split,GridSearchCV,cross_val_scorefrom sklearn.metrics import mean_squared_error,make_scorer
1 2 3 "train.csv" )"test_noLabel.csv" )
1 2 3 4 print ('-------------------' )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 196539 entries, 0 to 196538
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 196539 non-null int64
1 位置 196508 non-null float64
2 出租方式 24230 non-null float64
3 区 196508 non-null float64
4 卧室数量 196539 non-null int64
5 卫的数量 196539 non-null int64
6 厅的数量 196539 non-null int64
7 地铁站点 91778 non-null float64
8 地铁线路 91778 non-null float64
9 小区名 196539 non-null int64
10 小区房屋出租数量 195538 non-null float64
11 居住状态 20138 non-null float64
12 总楼层 196539 non-null float64
13 房屋朝向 196539 non-null object
14 房屋面积 196539 non-null float64
15 时间 196539 non-null int64
16 楼层 196539 non-null int64
17 装修情况 18492 non-null float64
18 距离 91778 non-null float64
19 Label 196539 non-null float64
dtypes: float64(12), int64(7), object(1)
memory usage: 30.0+ MB
-------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 56279 entries, 0 to 56278
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 56279 non-null int64
1 位置 56269 non-null float64
2 出租方式 4971 non-null float64
3 区 56269 non-null float64
4 卧室数量 56279 non-null int64
5 卫的数量 56279 non-null int64
6 厅的数量 56279 non-null int64
7 地铁站点 26494 non-null float64
8 地铁线路 26494 non-null float64
9 小区名 56279 non-null int64
10 小区房屋出租数量 56257 non-null float64
11 居住状态 4483 non-null float64
12 总楼层 56279 non-null float64
13 房屋朝向 56279 non-null object
14 房屋面积 56279 non-null float64
15 时间 56279 non-null int64
16 楼层 56279 non-null int64
17 装修情况 4207 non-null float64
18 距离 26494 non-null float64
dtypes: float64(11), int64(7), object(1)
memory usage: 8.2+ MB
1 2 3 4 sum ()/len (train))*100 0 ].index).sort_values(ascending=False )
装修情况 90.591180
居住状态 89.753688
出租方式 87.671658
地铁站点 53.302907
地铁线路 53.302907
距离 53.302907
小区房屋出租数量 0.509314
位置 0.015773
区 0.015773
dtype: float64
1 2 3 4 sum ()/len (test))*100 0 ].index).sort_values(ascending=False )
装修情况 92.524743
居住状态 92.034329
出租方式 91.167220
地铁站点 52.923826
地铁线路 52.923826
距离 52.923826
小区房屋出租数量 0.039091
位置 0.017769
区 0.017769
dtype: float64
1 sns.histplot(train['Label' ], kde=True )
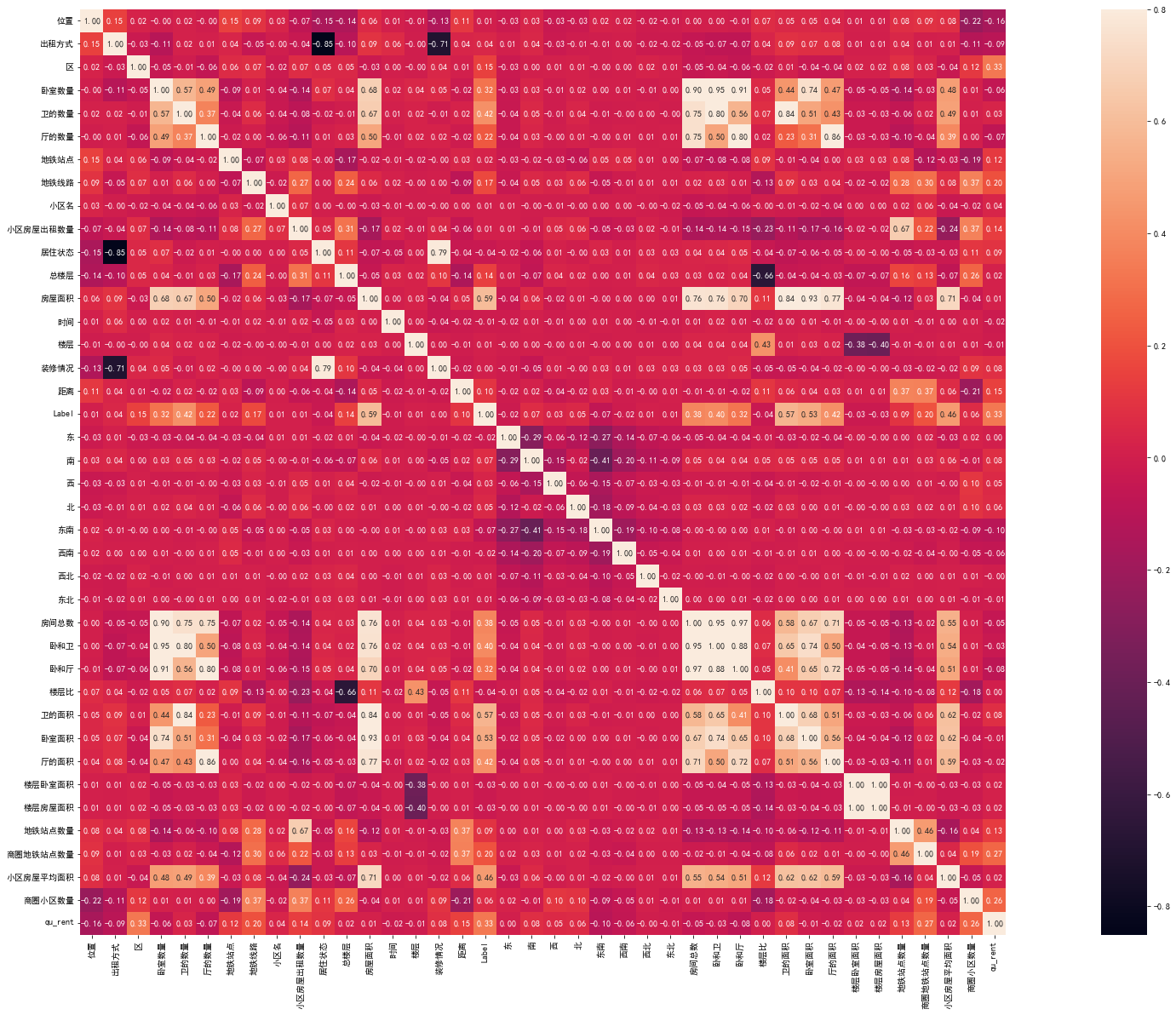
1 2 3 4 5 'ID' )20 , 10 )) True , annot=True , fmt='0.2f' ,vmax=0.8 )
通过相关性分析可以看出,房屋面积、卫的数量、卧室数量、厅的数量和租金之间相关性最高,其次是出租方式、装修情况、地铁线路、区、总楼层,其他特征相关性比较低。
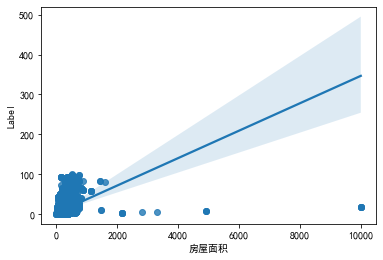
1 2 '房屋面积' ],y=train['Label' ])
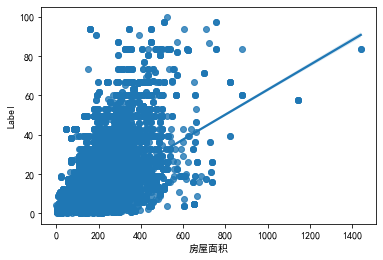
从图中可以看出房屋面积数据中存在异常点,因为测试集上房屋的最大面积为1441.576,则将删除阈值选为1441.576,下面将异常点删除:
1 2 3 '房屋面积' ]>1441.576 ].index)'房屋面积' ],y=train['Label' ])
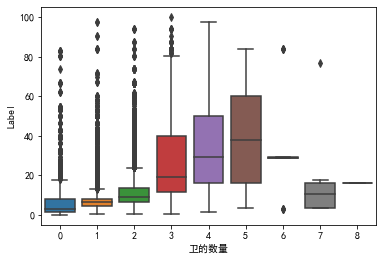
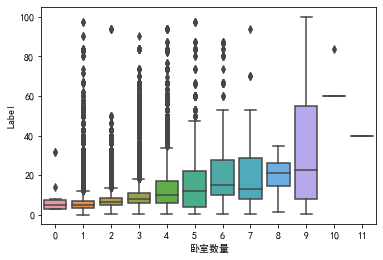
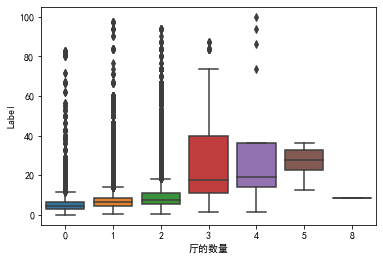
因为接下来的卫的数量、卧室数量、厅的数量属于离散型数据,所以采用箱线图来观察。
1 2 '卫的数量' ],y=train['Label' ])
1 2 '卧室数量' ],y=train['Label' ])
1 2 '厅的数量' ],y=train['Label' ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 '东' , '南' , '西' , '北' ,'东南' , '西南' , '西北' , '东北' ]def fill_orientation (item, orientation ):' ' )return 1 if orientation in x else 0 for i in orientation_headers:'房屋朝向' ].apply(lambda x: fill_orientation(x, i))for i in orientation_headers:'房屋朝向' ].apply(lambda x: fill_orientation(x, i))'房屋朝向' , axis=1 , inplace=True )'房屋朝向' , axis=1 , inplace=True )
上文去除了房屋面积的异常值,接下来进行缺失值处理
1 2 3 4 5 6 '区' ] = train['区' ].fillna(5 )'区' ] = test['区' ].fillna(5 )'位置' ] = train['位置' ].fillna(76 )'位置' ] = test['位置' ].fillna(76 )
1 2 3 4 5 6 '区' ,'小区名' , '楼层' ,], ascending=(True , True , True ))'区' ,'小区名' , '楼层' ], ascending=(True , True , True ))'小区房屋出租数量' ] = train['小区房屋出租数量' ].fillna(method='pad' )'小区房屋出租数量' ] = test['小区房屋出租数量' ].fillna(method='pad' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 data = pd.concat([train, test], axis=0 , ignore_index=True )'小区名' )['距离' ].mean()'小区名' :xiaoqu_dis.index,'平均距离' :xiaoqu_dis.values}'小区名' ,how='left' )'距离' ] = data['距离' ].fillna(data['平均距离' ])'小区名' )['地铁线路' ].max ()'小区名' :xiaoqu_sub_line.index,'小区地铁线路' :xiaoqu_sub_line.values}'小区名' ,how='left' )'地铁线路' ] = data['小区地铁线路' ]'小区名' )['地铁站点' ].max ()'小区名' :xiaoqu_sub.index,'小区地铁站点' :xiaoqu_sub.values}'小区名' ,how='left' )'地铁站点' ] = data['小区地铁站点' ]'平均距离' ,'小区地铁线路' ,'小区地铁站点' ],axis=1 ,inplace=True )
1 2 3 4 5 '距离' ] = data['距离' ].fillna(0 )'居住状态' ] = data['居住状态' ].fillna(0 )'装修情况' ] = data['装修情况' ].fillna(0 )'出租方式' ] = data['出租方式' ].fillna(2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 '房间总数' ] = data['卫的数量' ] + data['卧室数量' ] + data['厅的数量' ]'卧和卫' ] = data['卫的数量' ] + data['卧室数量' ]'卧和厅' ] = data['卧室数量' ] + data['厅的数量' ]'楼层比' ] = (data['楼层' ] + 1 ) / data['总楼层' ]'卫的面积' ] = data['房屋面积' ]*(data['卫的数量' ]/data['房间总数' ])'卧室面积' ] = data['房屋面积' ]*(data['卧室数量' ]/data['房间总数' ])'厅的面积' ] = data['房屋面积' ]*(data['厅的数量' ]/data['房间总数' ])'楼层' )['卧室面积' ].sum ().reset_index()'楼层' ,'楼层卧室面积' ]'left' ,on = '楼层' )'楼层' )['房屋面积' ].sum ().reset_index()'楼层' ,'楼层房屋面积' ]'left' ,on = '楼层' )'小区名' )['地铁站点' ].count().reset_index()'小区名' ,'地铁站点数量' ]'left' ,on = '小区名' )'位置' )['地铁站点' ].count().reset_index()'位置' ,'商圈地铁站点数量' ]'left' ,on = '位置' )'小区名' )['房屋面积' ].mean().reset_index()'小区名' ,'小区房屋平均面积' ]'left' ,on = '小区名' )'位置' )['小区名' ].count().reset_index()'位置' ,'商圈小区数量' ]'left' ,on = '位置' )'区' )['Label' ].mean()'区' :qu_rent.index,'qu_rent' :qu_rent.values}'qu_rent' ] = df_qu_rent['qu_rent' ].rank()'区' ,how='left' )
1 2 3 4 5 'ID' )40 , 20 )) True , annot=True , fmt='0.2f' ,vmax=0.8 )
Index(['ID', '位置', '出租方式', '区', '卧室数量', '卫的数量', '厅的数量', '地铁站点', '地铁线路', '小区名',
'小区房屋出租数量', '居住状态', '总楼层', '房屋面积', '时间', '楼层', '装修情况', '距离', 'Label',
'东', '南', '西', '北', '东南', '西南', '西北', '东北', '房间总数', '卧和卫', '卧和厅', '楼层比',
'卫的面积', '卧室面积', '厅的面积', '楼层卧室面积', '楼层房屋面积', '地铁站点数量', '商圈地铁站点数量',
'小区房屋平均面积', '商圈小区数量', 'qu_rent'],
dtype='object')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 df_train = data[data.Label.notna()].copy()'位置' , '出租方式' , '区' , '卧室数量' , '卫的数量' , '厅的数量' , '地铁站点' , '地铁线路' , '小区名' ,'小区房屋出租数量' , '居住状态' , '总楼层' , '房屋面积' , '时间' , '楼层' , '装修情况' , '距离' ,'东' , '南' , '西' , '北' , '东南' , '西南' , '西北' , '东北' , '房间总数' , '卧和卫' , '卧和厅' , '楼层比' ,'卫的面积' , '卧室面积' , '厅的面积' , '楼层卧室面积' , '楼层房屋面积' , '地铁站点数量' , '商圈地铁站点数量' ,'小区房屋平均面积' , '商圈小区数量' , 'qu_rent' ]'Label' ]0.3 )print ('X train shape:' ,X_data.shape)print ('X test shape:' ,X_test.shape)
X train shape: (196521, 39)
X test shape: (56279, 39)
选择xgb和lgb两种模型进行分析
1 2 3 4 5 'regression' , num_leaves=900 ,0.05 , n_estimators=3000 , bagging_fraction=0.7 ,0.6 , reg_alpha=0.3 , reg_lambda=2 ,18 , min_sum_hessian_in_leaf=0.001 )
1 2 3 4 model_lgb.fit(x_train, y_train)print ('MSE of val with lgb:' ,MSE_lgb)
MSE of val with lgb: 1.9318745903737613
1 2 3 4 5 6 model_lgb_pre = model_lgb.fit(X_data,Y_data)'ID' ] = test.ID'Label' ] = subA_lgb"sub_lgb.csv" ,index=False )
1 2 3 4 5 6 7 0.46 , gamma=0.047 , 0.05 , max_depth=3 , 1.7817 , n_estimators=2200 ,0.46 , reg_lambda=0.86 ,0.52 , silent=1 ,7 , nthread = -1 )
1 2 3 4 5 print ('MSE of val with xgb:' ,MSE_xgb)
MSE of val with xgb: 6.0960855438242305
1 2 3 4 5 6 7 'ID' ] = df_test.ID'Label' ] = subA_xgb"sub_xgb.csv" ,index=False )
进行stacking融合:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 'Method_1' ] = train_lgb_pred'Method_2' ] = train_xgb_pred'Method_1' ] = val_lgb'Method_2' ] = val_xgb'Method_1' ] = subA_lgb'Method_2' ] = subA_xgb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def build_model_lr (x_train,y_train ):return reg_modelprint ('MSE of Stacking-LR:' ,mean_squared_error(y_train,train_pre_Stacking))print ('MSE of Stacking-LR:' ,mean_squared_error(y_val,val_pre_Stacking))print ('Predict Stacking-LR...' )
MSE of Stacking-LR: 0.16213119164314563
MSE of Stacking-LR: 1.934086538479889
Predict Stacking-LR...
将模型融合后结果导出为csv文件:
1 2 3 4 sub_stack = pd.DataFrame()'ID' ] = test.ID'Label' ] = subA_Stacking"sub_stacking.csv" ,index=False )
本次作业首先对数据的分布和相关性进行了分析,然后判断了异常值和缺失值,之后结合初始数据对缺失值进行填充,然后使用初始数据构建新的特征,最后采用xgboost和lightgbm进行stacking模型融合,得出预测值。
我在本次的作业中大致走过一遍数据挖掘的流程,但在许多地方还有不足,需要继续学习,比如
可以考虑使用PCA、低方差特征过滤、相关系数等方法进行特征降维
本次作业的特征构建过于依赖人为设计和经验(对于影响租金因素的大致认识),后续还应该学习更多特征构建的方法
如何优化模型参数也是后续需要学习的地方
在完成作业中,有实现一些想法,但运行后的结果并不理想,具体原因还有待研究,写在下面供以后反思学习
在对’装修情况’、‘出租方式’、'居住状态’进行缺失值填充时,试图通过特定的排序后,使用缺失值的上一条数据进行填充。
使用这种方法的原因是,直观上,对于某个特征,在与其相关性强的几个特征固定时,该特征应该是一样的或者变化很小。
这个思路和上文中对’小区房屋出租数量’进行缺失值填充是一样的,但是这个思路的运行效果并不好,还不如直接使用固定值填充。究其原因可能有:
缺失值过多,‘小区房屋出租数量’的缺失值只有0.5%,但’装修情况’、‘出租方式’、'居住状态’的缺失值超过50%
选取了错误的用于排序的特征
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def fill (train, x, y ):""" 直观上,当前'小区名'(x[i])的'小区房屋出租数量'(y)的缺失值用上一个'小区名'(x[i-1])的'小区房屋出租数量'(y)进行填充是不合适的 但是在对train进行排序后,对于某个'小区名'(x[i])的'小区房屋出租数量'(y)可能会出现首尾都是NaN的情况,如[NaN, y1, y2,NaN, NaN] 此时不能直接用train['小区房屋出租数量'].fillna(method='pad')来填充 该函数使用x将train[y]分段,然后在每段中寻找第一个非NaN的元素放到数组首位,然后使用train[y].fillna(method='pad')进行填充 train: 排好序后的train x: 用于分段的特征 y: 需要进行缺失值填充的特征 """ list (set (train_x))for i in range (len (set_x)):if np.isnan(train_y[index[0 ]]):if len (train_y[index]) == np.sum (np.isnan(train_y[index])):continue else :0 ]0 ]] = train_y[index_n_nan]'pad' )return train_y'区' , '总楼层' , '房屋面积' ], ascending=(True , True , True ))'区' , '总楼层' , '房屋面积' ], ascending=(True , True , True ))'装修情况' ] = fill(train, '区' , '装修情况' )'装修情况' ] = fill(test, '区' , '装修情况' )'区' , '时间' , '房屋面积' ], ascending=(True , True , True ))'区' , '时间' , '房屋面积' ], ascending=(True , True , True ))'出租方式' ] = fill(train, '区' , '出租方式' )'出租方式' ] = fill(test, '区' , '出租方式' )'区' , '卧室数量' , '房屋面积' ], ascending=(True , True , True ))'区' , '卧室数量' , '房屋面积' ], ascending=(True , True , True ))'居住状态' ] = fill(train, '区' , '居住状态' )'居住状态' ] = fill(test, '区' , '居住状态' )