图像匹配综述翻译(1):问题定义&研究现状

从人为设定特征到深度特征的图像匹配:综述-翻译(1)
摘要:
作为各种视觉应用中的一项基本和关键任务,图像匹配可以识别并对应两幅或多幅图像中相同或相似的结构/内容。在过去的几十年中,图像匹配方法的数量和多样性不断增加,特别是近年来随着深度学习技术的发展。然而,对于不同场景和任务要求的特定应用,哪种方法是合适的选择,以及如何设计在准确性、鲁棒性和效率方面具有优异性能的更好的图像匹配方法,这可能会留下一些悬而未决的问题。这鼓励我们对这些经典和最新技术进行全面和系统的审查和分析。沿着基于特征的图像匹配管道,我们首先介绍了特征检测、描述和匹配技术,从手工制作的方法到可训练的方法,并分析了这些方法在理论和实践上的发展。其次,简要介绍了几种典型的基于图像匹配的应用,全面了解了图像匹配的意义。此外,我们还通过对代表性数据集的大量实验,对这些经典技术和最新技术进行了全面和客观的比较。最后,我们总结了图像匹配技术的现状,并对未来的工作进行了深入的讨论和展望。该调查可作为(但不限于)图像匹配及相关领域研究人员和工程师的参考。
关键词:
图像匹配、图匹配、特征匹配、配准、手工特征、深度学习
相关链接:
Fourth Workshop on Image Matching: Local Features & Beyond (image-matching-workshop.github.io)
[toc]
1. 引言
基于视觉的人工系统广泛用于引导机器感知和理解周围环境以做出更好的决策,在全球自动化和人工智能时代一直发挥着重要作用。然而,如何在特定要求下处理感知信息并理解多个视觉目标之间的差异和/或关系是各个领域的关键课题,包括计算机视觉、模式识别、图像分析、安全和遥感。作为这些复杂任务中的关键和基本问题,图像匹配,也称为图像配准或对应,旨在从两个或多个图像中识别然后对应相同或相似的结构/内容。该技术用于高维结构恢复和信息识别与整合,如3维重建、视觉同步定位与建图(VSLAM)、图像拼接、图像融合、图像检索、目标识别与跟踪等。如变化检测等。
图像匹配在将两个对象配对方面具有丰富的意义,从而衍生出许多特定的任务,例如稀疏特征匹配、密集匹配(如图像配准和立体匹配)、补丁匹配(检索)、2-D 和 3-D 点集配准,和图匹配。图像匹配一般由两部分组成,即匹配特征的性质和匹配策略,分别表示使用什么来匹配和如何匹配它们。最终目标是将感知到的图像几何变形到参考图像的公共空间坐标系中,并将它们的公共区域像素到像素对齐(即图像配准)。为此,一种直接策略,也称为基于区域的方法,利用原始图像像素强度的相似性度量或像素域变换后的信息在预定义大小的滑动窗口甚至整个图像中进行配准,不尝试检测任何显着的图像结构。
另一种经典且被广泛采用的流程称为基于特征的方法,即特征检测和描述、特征匹配、变换模型估计、图像重采样和变换,已在著名的调查论文(Zitova 和 Flusser 2003)中介绍并应用于各个领域。基于特征的图像匹配因其灵活性和鲁棒性以及广泛应用的能力而广受欢迎。特别是特征检测可以从图像中提取出独特的结构,而特征描述可以看作是一种图像表示方法,广泛应用于图像编码和图像分类检索等相似度测量中。此外,由于深度特征获取和非线性表达能力强,将深度学习技术应用于图像信息表示和/或相似度测量,以及图像对变换的参数回归,是当今图像匹配界的热门话题 ,与传统方法相比,已被证明可以实现更好的匹配性能并具有更大的潜力。
在现实世界中,用于匹配的图像通常取自相同或相似的场景/对象,同时在不同时间、不同视点或成像方式捕获。特别是,需要一种鲁棒且高效的匹配策略来建立正确的对应关系,从而激发各种方法来实现更好的效率、鲁棒性和准确性。尽管几十年来已经设计了许多技术,但就以下方面而言,开发一个统一的框架仍然是一项具有挑战性的任务:
- 直接匹配图像的基于区域的方法通常依赖于适当的补丁相似性测量来创建图像之间的像素级匹配。它们的计算成本可能很高,并且对图像失真、噪声引起的外观变化、不同的照明和不同的成像传感器敏感,这会对相似度测量和匹配搜索产生负面影响。因此,通常这些方法只能在小的旋转、缩放和局部变形下才能很好地工作。
- 基于特征的匹配方法通常效率更高,可以更好地处理几何变形。但它们是基于显著特征检测和描述、特征匹配和几何模型估计的,这也是一个挑战。一方面,在基于特征的图像匹配中,很难定义和提取真实世界中属于三维空间中相同位置的高百分比和大量特征,以确保匹配性。另一方面,将N个特征点与在另一幅图像中检测到的N个特征点进行匹配,将产生总共N个!可能的匹配,通常从高分辨率图像中提取数千个特征,点集中通常包含主要的异常值和噪声,这给现有的匹配方法带来了很大的困难。虽然已经提出了各种局部描述符,并将其与检测到的特征相结合以简化匹配过程,但使用局部外观信息将不可避免地导致模糊和大量错误匹配,尤其是对于质量低、内容重复的图像以及经历严重非刚性变形和极端视点变化的图像。
- 通常需要预定义的变换模型来指示两个图像或点集之间的几何关系。但是它可能会因不同的数据而异,并且事先未知,因此很难建模。对于涉及由于地表波动和图像视点变化,具有不同运动特性的多目标以及局部失真引起的非刚性变换的图像对,简单的参数模型通常是不够的
- 深度学习的出现为解决图像匹配问题提供了一条新途径,并显示出巨大的潜力。 然而,它仍然面临着一些挑战。 当应用于宽基线图像立体或复杂和严重变形下的配准时,从图像中学习用于直接配准或变换模型估计的选项是有限的。 将卷积神经网络 (CNN) 应用于稀疏点数据以进行匹配、配准和转换模型估计也很困难,因为要匹配的点——由于其无序和分散的性质而被称为非结构化或非欧几里得数据——使得 使用深度卷积技术难以操作和提取两个或多个点之间的空间关系(例如,相邻元素、相对位置以及多点之间的长度和角度信息)。
现有的调查集中在图像匹配任务的不同部分,无法涵盖过去十年的文献。例如,早期的评论 (Zitova和Flusser 2003; Tuytelaars和Mikolajczyk 2008; Strecha等人。2008; Aan æ s等人。2012; Heinly等人。2012; Awrangjeb等人。2012;Lietal。2015) 通常关注手工制作的方法,这不足以为研究基于CNN的方法提供有价值的参考。最近的评论涉及可训练的技术,但它们仅涵盖图像匹配社区的单个部分,要么关注检测器 (Huang等人。2018; Lenc和Vedaldi 2014),要么关注描述符 (Balntas等人。2017; Schonberger等人。2017) 或特定的匹配任务 (Ferrante和Paragios 2017;haskins等人2020; Yan等人2016b; Maiseli等人2017),以及许多其他人更关注相关应用 (Fan等人2019; Guo等人2016; Zheng等人2018; Piasco等人2018)。在本调查中,我们旨在提供对现有图像匹配方法的最新,全面的总结和评估,尤其是对于最近引入的基于学习的方法。更重要的是,我们对现有文献中缺少的主流方法进行了详细的评估和分析
本次调查主要关注基于特征的匹配,尽管补丁匹配、点集配准以及其他相关的匹配任务也进行了回顾。下图是该文的结构图; 第2节和第3节分别描述了从手工方法到可训练方法的特征检测和描述技术。块匹配被归类为特征描述域,并且还审查了3-D点集特征。在第4节所示,我们提出了不同的匹配方法,包括基于区域的图像匹配,纯点集配准,图像描述符相似性匹配和不匹配去除,图匹配以及基于学习的方法。第5节和第6节分别介绍了基于图像匹配的视觉应用程序和评估指标,包括性能比较。在第7节我们总结并讨论未来可能的发展。
2. 特征检测
早期的图像特征是手动注释的,在一些低质量的图像匹配中仍然使用。随着计算机视觉的发展和对自动匹配方法的要求,已经引入了许多特征检测方法来从图像中提取稳定且独特的特征。
2.1 特征检测器概述
检测到的特征表示图像或现实世界中的特定语义结构,可以分为角特征(Moravec 1977;Harrisetal. 1988;Smith 和 Brady 1997;Rosten 和 Drummond 2006;Rublee 等 2011)、斑点特征(Lowe 2004 ; Bay等人,2006; Agrawal等人, 2008;Yi 等人,2016), 线/边 (Harris等人,1988; Smith and Brady 1997; Canny 1987; Perona and Malik 1990), 以及形态区域特征 (Matas等人,2004 年;Mikolajczyk 等人,2005 年)。 但是,用于匹配的最流行的特征是点(也称为关键点或兴趣点)。 与线和区域特征相比,点易于提取和定义,其形式可大致分为角点和斑点。
一个好的兴趣点必须容易找到,理想情况下计算速度快,因为一个好位置的兴趣点对于进一步的特征描述和匹配是至关重要的。为了促进**(i)匹配性,(ii)后续应用的能力,以及(iii)**匹配效率和减少存储需求,提出了许多可靠的特性(Zitova和弗卢瑟2003;图特拉尔和米科拉奇克2008),包括重复性、不变性、鲁棒性和效率。**特征检测的常见思想是构造一个特征响应来区分突出的点、线和区域,以及平面和非独特的图像区域。这种想法随后可以分为梯度、强度、二阶导数、轮廓曲率、区域分割和基于学习的检测器。**下面,我们将对这些方法的特征检测器进行全面的介绍,重点关注基于学习的方法,以指导研究人员了解传统的和可训练的检测器如何工作,并深入了解它们的优点和缺点。
2.2 角点特征
例如,角特征可以定义为“L”、“T”、“X”形式的两条直线的交点,或轮廓的高曲率点。 角点检测的常见想法是计算角点响应并将其与边缘、平面或其他不太明显的图像区域区分开来。 不同的策略可用于传统的角点搜索,即基于梯度、强度和轮廓曲率。 参考 Zitova 和 Flusser (2003), Li 等人 (2015)、Tuytelaars 和 Mikolajczyk (2008) 以及 Rosten 等人 (2010) 了解详情。
2.2.1 基于梯度的检测器
基于梯度的角点响应更喜欢在图像中使用一阶信息来区分角点特征。最早的自动角点检测方法可以追溯到Moravec检测器 (Moravec 1977),它首先引入了 “兴趣点” 的概念来定义不同的特征点,这些特征点是基于局部强度的自相关来提取的。该方法从八个方向的移位窗口计算并搜索每个像素的最小强度变化,如果最小值优于给定阈值,则检测兴趣点。
然而,由于不连续的比较方向和大小,Moravec 检测器对方向或图像旋转不是不变的。 著名的 Harris 角点检测器 (Harris et al. 1988) 被用于解决各向异性和计算复杂度问题。 Harris 方法的目标是使用二阶矩矩阵或自相关矩阵找到灰度值变化最快和最低的方向; 因此,它不受方向和光照的影响,具有可靠的可重复性和独特性。 哈里斯在 Shi 和 Tomasi (1993) 中进一步改进,通过使特征更“分散”并更准确地定位来获得更好的跟踪性能。
2.2.2 基于强度的探测器
已经提出了几种基于模板或强度比较的角点检测器,通过将周围像素的强度与中心像素的强度进行比较,以简化图像梯度计算。由于它们的二进制性质,它们被广泛用于许多现代应用程序中,特别是一些具有存储和实时要求的应用程序。
基于强度的角检测器,即最小单值段同化核(SUSAN)(Smith 和 Brady 1997),是基于局部半径区域像素与核之间的亮度相似性。 SUSAN 可以快速实现,因为它不需要梯度计算。 基于亮度比较的概念已经提出了许多类似的方法,其中最著名的是 FAST 检测器(Trajkovi´c 和 Hedley 1998)。 FAST 使用沿圆形图案的每个像素与中心像素进行二进制比较,然后使用机器学习(即 ID3 树 Quinlan 1986)策略确定更可靠的角点特征,该策略在大量相似的场景图像上进行训练,可以生成 角选择的最佳标准。
作为SUSAN的一项改进,FAST具有极高的效率和高重复性,并被更广泛地使用。为了在不降低效率的情况下提高FAST,FAST-ER(Rosten等人2010) 通过基于以核为中心的进一步像素强度比较来推广检测器,引入以增强重复性。另一个改进是AGAST(Mair等人2010)其中定义了另外两个像素亮度比较标准,然后在扩展配置空间中训练最优的专用决策树,从而使FAST检测器更通用和自适应。结合FAST的效率以及Harris检测器的可靠性,Rublee et al.(2011)提出了一种集成的特征检测器和匹配描述符,称为ORB。ORB使用Harris响应选择一定数量的快速角点作为最终检测到的特征。将局部面片的灰度质心和中心像素本身形成一个向量来表示ORB特征的主方向,这有助于计算ORB中二元描述符的相似度。最近,提出了一种Sadder特征检测器(Aldana Iuit et al.2016)来提取兴趣点。在该检测器中,通过对具有一定几何约束的两个同心环的强度比较,有效地验证了鞍条件。与传统方法甚至现代可训练方法相比,Sadder检测器可以实现更高的重复性和更大的扩展性(Komorowski et al.2018)。
2.2.3 基于曲率的探测器
角点特征提取的另一种策略是基于检测到的高级图像结构,例如边缘、轮廓和显着区域。角特征可以立即定义为中点/端点或边缘或轮廓的稀疏采样(Belongie et al. 2002)。这些之后会被用于形状匹配或点配准,特别是对于纹理较少或二进制类型的图像对。基于曲率的策略旨在根据检测到的图像曲线状边缘提取具有最大曲率搜索的角点。该策略从边缘提取和选择方法开始,随后的两个步骤是曲线平滑和曲率估计。最后通过选择曲率极值点来确定角点。一般来说,边缘检测器通常首先需要基于轮廓曲率的角点检测。
在曲线平滑中,由于曲线点的量化位置,斜率和曲率难以评估。曲线中的噪声和局部变形也可能导致对特征稳定性和独特性的严重影响。因此,在曲率计算之前或期间应进行平滑处理,以使曲率极值点与其他曲线点更加明显。通常使用两种平滑策略,即直接方法和间接方法。直接平滑,例如高斯平滑(Mokhtarian 和 Suomela 1998;Pinheiro 和 Ghanbari 2010),可以去除噪声并可能在一定程度上改变曲线位置。相比之下,在间接平滑策略中,例如,支持区域法或基于弦长的方法 (Ramer 1972; Awrangjeb 和 Lu 2008),可以保留曲线点的位置。
对于曲率估计,对于平滑曲线的每个点,需要一个显着性响应度量来进行角搜索,即曲率。曲率估计方法一般也分为直接法和间接法。前者基于代数或几何估计,例如余弦,局部曲率和切向挠度 (Mokhtarian和Suomela 1998; Rosenfeld andWeszka 1975; Pinheiro和Ghanbari 2010)。后者以间接的方式估计曲率,并经常用作显著性度量,例如通过沿曲线的几个移动矩形来计算曲线点的数量 (Masood和Sarfraz 2007),使用从连接曲线的两个端点到曲线点的弦的垂直距离 (Ramer 1972),以及其他替代方案 (Zhang等人2010,2015)。与间接估计方法相比,由于邻接点考虑较少,直接估计方法对噪声和局部变化更敏感。
最后,可以使用阈值策略确定角点,以去除虚假和不明显的点(Mokhtarian 和 Suomela 1998;Awrangjeb 和 Lu 2008)。 可以从基于轮廓曲率的角点测量中获得更多详细信息(Awrangjeb 等人,2012 年)。 此外,最近还提出了一种名为 MSFD (Mustafa et al. 2018) 的基于多尺度分割的角点检测器,用于宽基线场景匹配和重建。 MSFD 中的特征点是通过使用现成的分割方法在三个或更多区域边界的交点处检测到的。 MSFD 可以为宽基线图像匹配和高重建性能生成丰富而准确的角点特征。
上述角点特征检测器很容易定位在图像的轮廓或边缘结构中(即不是这样的散布或不均匀分布),并且受到两幅图像之间的尺度和仿射变换的限制。在三种类型的角点检测策略中,基于梯度的方法能够更准确地定位,而基于强度的方法在效率上表现出优势。基于轮廓曲率的方法需要更多计算,但它们是处理无纹理或二值图像(例如红外和医学图像)的更好选择,因为基于图像线索的特征描述符不适用于这些类型的图像并且基于点的描述符通常用于匹配任务(即点集注册或形状匹配)。请参阅第3、4节的详细信息。
2.3 斑点特征
斑点特征通常表示为一个局部封闭区域(例如,具有规则的圆形或椭圆形),其中的像素被认为彼此相似并且与周围的邻域不同。 斑点特征可以写成(x,y,θ)的形式,其中(x,y)是特征位置的像素坐标,θ表示特征的blob形状信息,包括尺度和/或仿射。在过去的几十年中已经引入了许多 blob 特征检测器,它们可以大致分为二阶偏导数和基于区域分割的检测器。基于二阶偏导数的方法基于拉普拉斯尺度选择和/或Hessian矩阵计算仿射不变量。而基于分割的方法更倾向于先对形态学区域进行分割,然后利用椭圆拟合估计出仿射信息来检测斑点特征。与角点特征相比,斑点特征对于精度要求较高的视觉应用更为有用,因为更多的图像线索被用于特征识别和表示,从而使blob特征对图像变换更为准确和鲁棒。
2.3.1 基于二阶偏导数的检测器
在基于二阶偏导数的方法中,基于尺度空间理论应用高斯拉普拉斯算子 (LoG) (Lindeberg 1998)。在此,首先根据图像的二阶差分中的零交叉将Laplace算子用于边缘检测,然后将高斯卷积滤波用作预处理以减少噪声。
LoG可以检测局部极值点和高斯核圆对称引起的归一化响应区域。高斯函数的不同标准差通过在多尺度空间中搜索极值作为最终的稳定斑点特征,可以检测出不同尺度下的尺度不变斑点。高斯差分(DoG)(Lowe et al.1999;Lowe 2004)滤波器可用于近似对数滤波器,并大大加快计算速度。另一个经典的斑点特征检测策略基于Hessian(DoH)的行列式(Mikolajczyk和Schmid2001、2004)。这是因为第二个矩阵的特征值和特征向量可以用于估计和校正仿射区域,所以更具有仿射不变性。
通过使用 DoG、DoH 和两者进行兴趣点检测已在最近的视觉应用中得到广泛应用。 著名的 SIFT (Lowe et al. 1999;Lowe 2004) 提取关键点作为 DoG 金字塔中的局部极值,使用局部强度值的 Hessian 矩阵进行过滤(下一节将回顾相应的描述部分)。 Mikolajczyk 等人,将 Harris 和 Hessian 检测器与 Laplacian 和 Hessian 矩阵结合用于尺度和仿射特征检测(Mikolajczyk 和 Schmid 2001, 2004),即 Harris/Hessian-Laplacian/affine。 SURF (Bay et al. 2006) 通过使用 Haar 小波计算逼近基于 Hessian 矩阵的检测器以及积分图像策略来加速 SIFT,从而简化二阶微分模板的构建。
一些基于 SIFT 和 SURF 的改进已被相继提出,以便在后续应用中获得更好的性能。此类改进包括完全仿射不变 SIFT 检测器 (ASIFT) (Morel and Yu 2009)、中心环绕极值 (Agrawal et al. 2008) 策略特征检测器,其拉普拉斯计算近似于提出的双边滤波以提高效率,以及有效的在 DARTs 中使用分段三角形滤波器对 DoH 进行逼近 (Marimon et al. 2010)。此外,在 SIFT-ER 检测器 (Mainali et al. 2013) 中使用了余弦调制高斯滤波器,以在最小尺度空间定位误差的情况下获得高特征可检测性,其中滤波器组系统具有高精度的滤波器逼近,没有任何图像子/上采样。还为匹配任务引入了基于边缘焦点的斑点检测器(Zitnick 和 Ramnath 2011)。在该检测器中,边缘焦点定义为图像中与最近边缘大致等距且方向垂直于该点的点。
与圆形高斯响应函数不同,非线性偏微分方程应用于 KAZA 检测器,用于通过非线性扩散滤波进行斑点特征搜索 (Alcantarilla et al. 2012)。 通过在金字塔框架中嵌入快速显式扩散来实现称为 AKAZA (Alcantarilla and Solutions 2011) 的加速版本,以显着加快非线性尺度空间中的特征检测。 但是,它仍然存在计算复杂度高的问题。 另一种方法是 WADE (Salti et al. 2013),它通过波传播函数实现非线性特征检测。
2.3.2 基于分割的检测器
基于分割的斑点检测器从基于恒定像素强度或零梯度的不规则区域分割开始。最著名的基于区域分割的 blob 特征之一是最大稳定极值区域 (MSER) (Matas et al. 2004)。它提取在大范围的强度阈值下保持稳定的区域。这种方法不需要额外的尺度估计处理,并且对大的视点变化具有鲁棒性。术语“最大稳定”描述了阈值选择过程,假设每个极值区域都是通过阈值处理的分水岭图像的连通分量。 Kimmel 等人(2011)介绍了对 MSER 的扩展。利用形状结构线索。其他改进基于主曲率图像的分水岭区域 (Deng et al. 2007; Ferraz and Binefa 2012) 或考虑颜色信息以获得更高的辨别力 (Forssén 2007)
与 MSER 类似,其他基于分割的特征,例如基于强度和边缘的区域(Tuytelaars 和 Van Gool 2004),也用于仿射协变区域检测。 然而,这种类型的特征检测对特征匹配的用处较少,逐渐向计算机视觉中的显着性检测和分割发展。 具体的方法调查和综合评论可以在 Mikolajczyk 等人中找到(2005)和李等人(2015 年)。
2.4 可学习的特征
近年来,基于数据驱动的基于学习的方法在一般视觉模式识别任务中取得了重大进展,并且也被应用于图像特征检测。 该渠道大致可分为经典学习和深度学习的使用。
2.4.1 基于经典学习的检测器
从过去十年开始,经典的基于学习的方法,例如决策树、支持向量机 (SVM) 和其他与深度学习相反的分类器,已经被用于手工关键点检测(Trajkovi´c 和 Hedley 1998;Strecha等人 2009;Hartmann 等人 2014;理查森和奥尔森 2013)。FAST (Trajkovi´c and Hedley 1998) 检测器是使用传统学习进行可靠和可匹配点识别的第一次尝试,类似的策略已应用于许多后续改进(Mair et al. 2010; Rublee et al. 2011),斯特雷查等人 (2009) 训练 Wald-Boost 分类器在预对齐的训练集上学习具有高重复性的关键点。
最近,Hartmann等人 (2014) 表明,可以从运动结构 (SfM) 渠道中学习预测哪些候选点是可匹配的,从而显著减少兴趣点的数量而不失去过多的真实匹配。同时,Richardson和Olson (2013) 报告说,可以通过在卷积滤波器的空间中进行随机采样来学习手工设计的检测器,并尝试使用频域约束的学习策略来找到最佳滤波器。然而,经典学习一直只用于通过分类器学习进行可靠的特征选择,而不是直接从原始图像中提取感兴趣的特征,直到深度学习的出现。
2.4.2 基于深度学习的检测器
受手工制作的特征检测器的启发,基于CNN的检测的一般解决方案是构建响应图,在监督(Yi et al.2016;Verdie et al.2015;Zhang et al.2017b)、自我监督(Zhang and Rusinkiewicz 2018;DeTone et al.2018)或无监督方式(Lenc和Vedaldi 2016;Savinov et al.2017;Ono et al.2018;Georgakis et al.2018;Barroso Laguna et al.2019)中搜索兴趣点。该任务通常转化为回归问题,在变换和成像条件不变性约束下,可以以可微的方式进行训练。监督方法显示了使用锚(例如,从SIFT方法获得的锚)来指导其培训的好处,但其性能可能在很大程度上受到锚施工方法的限制,因为锚本身很难合理定义,如果附近不存在锚,可能会阻止网络提出新的关键点(Barroso Laguna et al.2019)。自监督和非监督方法训练检测器,无需任何人工标注,只需两幅图像之间的几何约束即可进行优化引导;有时需要简单的人力援助来进行预训练(DeTone et al.2018)。此外,许多方法通过与特征描述和匹配联合训练,将特征检测集成到整个匹配管道中(Yi et al.2016;DeTone et al.2018;Ono et al.2018;Shen et al.2019;Dusmanu et al.2019;Choyetal.2016;Rocco et al.2018;Dusmanu et al.2019;Revaud et al.2019),这可以增强最终匹配性能并以端到端的方式优化整个过程。
例如,TILDE (Verdie et al. 2015) 训练多个分段线性回归模型,以在天气和照明条件的剧烈成像变化下检测可重复的关键点。首先,它使用 DoG 识别从同一视点拍摄的多个训练图像中的良好关键点候选者进行训练集收集,然后训练一个通用回归器来预测一个分数图,其在非极大值抑制 (NMS) 后的最大值可以被视为想要的兴趣点。
DetNet(Lenc和Vedaldi 2016)是第一个用于学习局部协变特征的完全通用公式;它将检测任务转换为一个回归问题,然后导出一个协方差约束,以便在几何变换下自动学习用于局部特征检测的稳定锚。同时,Quad net(Savinov et al.2017)利用单个实值响应函数实现了变换不变分位数排序下的关键点检测,使其能够通过优化可重复的排序从零开始完全学习检测器。Zhang和Rusinkiewicz(2018)中的一个类似检测器将这种“排名”损失与“峰值”损失相结合,产生了一个更具可重复性的检测器。
Zhang等人(2017b)提出了TCDET检测器,基于“标准块”和“规范特征”的新概念,定义了一种新的公式,以同等关注区分性和协变约束。该检测器可以在不同的图像变换下检测出具有鉴别性和可重复性的特征。KeyNet(BarrosoLaguna et al.2019)将手工制作和学习的CNN过滤器结合在shallow multiscale架构中,并提出了一种轻型/高效的可训练检测器。手工制作的过滤器提供锚定结构,用于定位、评分和排序可重复的特征,这些特征将反馈给学习过的过滤器。CNN通过检测不同层次的关键点来表示尺度空间;定义损失函数,从不同尺度上检测稳健特征点,并最大化重复性得分。Mishkin等人(2017、2018)也使用CNN学习了基于仿射区域的兴趣点。
将检测器集成到匹配通道中的方法与上述仅用于检测的方法类似。主要区别可能在于训练方式,核心挑战是让整个过程可区分。例如,易等人(2016)试图基于输入四个补丁联合训练检测器、方向估计器和描述符。他们提出的 LIFT 可以被视为 SIFT 的可训练版本,需要 SfM 系统的监督来确定特征锚。训练过程从描述符到检测器是单独进行的,并且可以使用学习的结果来指导检测器的训练,从而提高可检测性。与 LIFT 不同,SuperPoint (DeTone et al. 2018) 通过输入全尺寸图像并在一次前向传递中联合计算像素级兴趣点位置和相关描述符来引入全卷积模型;构建了用于伪地面实况生成和预训练的合成数据集,单应性自适应模块使其能够在提高检测可重复性的同时实现自监督训练。
LF-Net (Ono等人2018) 将端到端通道限制在一个分支上,以可区分的方式优化整个过程; 它还使用在全尺寸图像上运行的全卷积网络来生成丰富的特征得分图,然后可以用来提取关键点位置和特征属性,例如比例和方向; 同时,它执行子像素位置的NMS的可区分形式,即softargmax,并提高关键点的准确性和显着性。与lf-net类似,rf-net (Shen等人2019) 选择高响应像素作为多尺度上的关键点,但是响应图由接受特征图构建。Bhowmik等人 (2020) 指出,这些低级匹配分数的增加的准确性不一定转化为高级视觉任务中的更好性能,因此它们将特征检测器嵌入到完整的视觉通道中,其中以端到端方式训练可学习的参数。作者使用强化学习的原理克服了关键点选择和描述匹配的离散性质。Luo等人 (2020) 提出了通过联合学习局部特征检测器和描述符来探索局部形状信息的特征点并增强点检测的准确性的ASFeat。另一种基于检测的学习方法是估计方向 (MooYi等人2016),而空间变换网络 (STN) (Jaderberg等人2015) 也可以在基于深度学习的旋转不变性检测器中提供很好的参考 (Yi等人2016;ono等人2018)。
与局部特征描述符不同,关于显著特征检测器的研究很少,尤其是最近基于CNN的技术。据我们所知,最新的调查(Lenc和Vedaldi 2014)侧重于局部特征检测。它介绍了几种著名方法的基本思想,从手工制作的探测器到加速和学习的探测器
2.5 三维特征探测器
Tombari 等人(2013)专注于 3-D 关键点检测器对最先进的方法进行了出色的调查,并对其性能进行了详细评估。 简而言之,现有的方法分为两类,固定尺度检测器和自适应尺度检测器。 在这两个类别中,关键点都被选为预定义显着性测量的局部极值。 不同之处在于尺度特征的参与,它定义了对后续描述阶段的支持。 固定尺度检测器倾向于在特定尺度级别搜索关键点,这是作为先验信息给出的。 自适应尺度检测器通过采用定义在表面上的尺度空间来扩展 2-D 图像的尺度概念,或者通过将 3-D 数据嵌入到 2-D 平面上来实现传统的尺度空间分析。
2.5.1 固定比例探测器
Chen 和 Bhanu (2007) 介绍了局部表面补丁 (LSP) 方法。 LSP 中一个点的显着性由其形状指数(Dorai 和 Jain 1997)测量,由该点的主曲率定义。钟(2009)介绍了固有形状特征(ISS)方法,其中显着性来自支持区域的散射矩阵的特征值分解。在这种方法中,使用特征值的比率来修剪一些点,最终的显着性由特征向量决定。通过这种方式,识别出沿每个主方向变化较大的点。类似于国际空间站,Mian 等人 (2010) 还利用散射矩阵修剪非特征点,但使用不同的基于曲率的显着性测量。孙等人(2009) 提出了热核特征 (HKS) 方法,该方法基于形状上的热扩散过程的特性。在这种方法中,显着性测量是通过将热核限制在时间域来定义的。热核由底层流形唯一确定,这使得 HKS 成为形状的紧凑表征。
2.5.2 自适应尺度检测器
在检测中,需要自适应地适应尺度。为此,Unnikrishnan和Hebert(2008)提出了一个Laplace-Beltrami尺度空间,通过计算每个点周围增加支撑的设计函数。该函数由一个新的算子定义,该算子反映基础形状的局部平均曲率,并提供显著性信息。Zaharescu等人(2009)提出了MeshDoG方法,该方法类似于二维情况下的DoG算子(Lowe 2004);尽管如此,操作符是在流形上定义的标量函数上计算的。DoG操作符的输出表示关键点检测的显著性。Castellani等人(2008年)也使用DoG操作符构建了缩放空间,但直接在三维网格上。Mian等人(2010)提出了一种用于提取尺度不变特征的自动尺度选择技术。缩放空间是通过增加支架尺寸来构建的,每个关键点的自动缩放选择是通过使用NMS长尺度来执行的。Bronstein和Kokkinos(2010)解决了对HKS尺度敏感的缺点,他们使用傅里叶变换幅值从HKS中提取尺度不变量,而无需进行尺度选择。Sipiran和Bustos(2011)利用自适应尺度确定技术将著名的Harris算子(1988)扩展为三维数据。读者可参考Tombari等人(2013)对其他自适应比例检测器的进一步讨论。Salti等人(2015)设计了一种基于学习的三维关键点检测器,将关键点检测问题转换为二进制分类问题,以确定预定义的三维描述符可以正确匹配哪些支持。
2.6 总结
特征检测器的基本思想是通过响应值将兴趣特征与其他特征区分开来,从而解决两个问题:(i)如何定义图像中的鉴别模式,以及(ii)如何在不同的图像条件和图像质量下重复检测显著特征(Zhang et al.2017b)。随着这些检测器的发展,主要的改进和常见的策略涉及四个方面,即特征响应类型和效率、鲁棒性和准确性的改进,从而提高检测到的特征的匹配性和后续应用的性能。
对于传统方法,使用更多的图像线索可以带来更好的鲁棒性和可重复性,但通常需要更多的计算成本。 除了使用低阶特征检测器外,还设计了几种策略,例如近似和预计算,以大大加快计算速度并保持可匹配性。 为了保证鲁棒性,在搜索稳定特征时通常需要进行尺度和仿射信息估计。 而为了提高精度,局部极值搜索亚像素精度和像素和尺度空间中的 NMS 策略以避免局部聚集特征是传统管道中的两个流行选择。
对于基于学习的检测器,除了强度、梯度或二阶导数之外,可以基于 CNN 捕获的高级线索提取可重复和显着的关键点。虽然效率很大程度上取决于网络结构,但早期的深度学习方法通常很耗时。最近提出的方法,例如 SuperPoint 和 KeyNet,已经在保持最先进性能的同时实时实现了良好的实现。多尺度采样或改变的感受野将使这些基于深度学习的检测器不随尺度变化,其中尺度或旋转信息在网络中直接估计。它们可以取得有希望的结果,因为深度学习技术可以轻松区分相同的结构,尽管图像存在明显的差异和几何变换。精度可以直接在基于学习的方法的损失函数中进行优化,NMS的可微分形式常用于亚像素精度定位和可重复性增强。
3. 特征描述
一旦从原始图像中检测到有区别的兴趣点,就需要为每个特征耦合一个局部块描述符,以便在两个或多个图像上正确有效地建立特征对应关系。换言之,特征描述符通常用于将兴趣点周围的原始局部信息转换为稳定且有区别的形式,通常作为高维向量,以便在描述符空间中两个对应的特征尽可能接近,而两个非对应的特征尽可能远。
3.1 特征描述符概述
特征描述的处理过程可以分为三个步骤:局部低级特征提取、空间池化和特征归一化(Lowe 2004; Rublee et al. 2011; Brown et al. 2010)。首先,必须提取局部图像区域的低级信息。该信息由像素强度和梯度组成,或者从一系列可控制的滤波器中获得。随后,局部块被分成几个部分,将局部信息汇集在每个部分中,然后使用池化方法将它们连接起来,例如矩形网格(Lowe 2004),极坐标网格(Mikolajczyk and Schmid 2005),高斯采样(Tola,2010 年)和其他人(Rublee 等人,2011 年);联合特征表示被转换为更具区分性的表示,可以以简化形式保留重要信息,以获得更好的匹配性能。最后,从池化局部信息的归一化结果中获得描述符,旨在将聚合结果映射为浮点或二进制值的长向量,以便轻松评估图像特征之间的相似性。
与特征检测器类似,现有的描述符被提出和改进以变得高度鲁棒、高效和判别性,以解决图像匹配问题。 为裁剪后的图像块估计合适的大小和方向是特征描述和匹配任务中的核心问题。 通过正确识别大小和方向,匹配方法可以对全局和/或局部变形(例如旋转和缩放)具有鲁棒性和不变性。 与使用原始图像信息的直接相似性测量相比,特征描述的初衷侧重于区分增强。 许多精心设计的描述符可以通过使用池化参数优化、采样规则设计或使用机器学习和深度学习技术来提高辨别和匹配性能。
特征描述引起了越来越多的关注。 描述符可以被视为给定图像的可区分和鲁棒的表示,不仅广泛用于图像匹配,还广泛用于图像检索、人脸识别和其他基于图像相似性测量的任务的图像编码。 然而,使用原始图像信息对两个图像块进行直接相似性测量将被视为基于区域的图像匹配方法,将在下一节中进行回顾。 至于基于图像块的特征描述符,我们将根据数据类型回顾传统的特征描述符,即浮动和二进制描述符。 将为最近的数据驱动方法添加一个新的小节,包括经典的机器学习和新兴的基于深度学习的方法。 我们将全面回顾手工和基于学习的特征描述方法,并展示这些方法之间的联系,为读者进一步研究提供有用的指导,特别是使用深度学习/CNN技术开发更好的描述方法。 此外,我们还将回顾 3-D 特征描述符,其中特征通常是从没有任何图像像素信息但具有空间位置关系的点数据中获得的(例如,3-D 点云配准)。
3.2 手工特征描述符
手工制作的特征描述符通常依赖于专家的先验知识,这些知识仍然广泛用于许多视觉应用中。 遵循传统局部描述符的构建过程,第一步是提取低级信息,可简单分为图像梯度和强度。 随后,应用常用的池化和归一化策略,如统计和比较,生成长而简单的向量,用于对数据类型(浮点数或二进制)进行区分描述。 因此,手工描述的描述符大多依赖于作者的知识,描述策略可以分为梯度统计、局部二值模式统计、局部强度比较和局部强度顺序统计方法。
3.2.1 基于梯度统计的描述符
梯度统计方法通常用于形成浮点型描述符,如SIFT(Lowe et al.1999;Lowe 2004)及其改进版本(Bay et al.2006;Morel and Yu 2009;Dong and Soatto 2015;Tola et al.2010)中引入的定向梯度直方图(HOG)(Dalal and Triggs 2005),并且它们仍然广泛用于一些现代视觉任务。在SIFT中,特征尺度和方向分别由DoG计算和梯度方向直方图中的最大面元从检测到的关键点周围的局部圆形区域确定,从而实现尺度和旋转不变性。在描述阶段,首先根据归一化的尺度和旋转,将检测到的特征局部区域矩形划分为4×4个不重叠的网格,然后在每个单元中进行具有8个单元的梯度方向直方图,并嵌入128维浮点向量中作为SIFT描述符。
另一个特征描述符是SURF,可以通过使用Haar小波的响应来近似梯度计算来加速SIFT算子; 还应用积分图像来避免Haar小波响应中的重复计算,从而比SIFT更有效地计算。基于这两个方面的其他改进通常集中在辨别,效率,健壮性以及应对特定的图像数据或任务。例如,CSIFT (Abdel-Hakim和Farag 2006) 使用额外的颜色信息来增强辨别能力,并且ASIFT (Morel和Yu 2009) 通过改变两个相机轴方向参数来模拟可获得的所有图像视图,以实现完全仿射不变性。Mikolajczyk和Schmid (2005) 使用梯度方向的极坐标划分和直方图统计。已经提出了SIFT-rank (Toews和wells 2009) 来研究基于现成的SIFT的顺序图像描述,以实现不变的特征对应。已经研究了基于韦伯定律的方法 (WLD) (Chen等人2009),以通过编码某些位置的差分激励和方向来计算直方图。
Arandjelovi’c和Zisserman(2012)使用平方根(Hellinger)核代替标准的欧几里德距离度量,将原始SIFT空间转换为RootSIFT空间,并在不增加处理或存储需求的情况下产生了优异的性能。Dong和Soatto(2015)通过汇集不同域大小的梯度方向修改了SIFT,并提出了DSP-SIFT描述符。另一种有效的基于SIFT的宽基线立体密集描述符,即DAISY(Tola et al.2010),使用对数极坐标网格排列和高斯池策略来近似梯度方向的直方图。受DAISY的启发,DARTs(Marimon et al.2010)可以高效地计算比例空间,并将其重新用于描述符,从而提高效率。最近还提出了一些手工制作的浮点类型描述符,并显示出良好的性能;例如**,局部引力局部描述符(Bhattacharjee和Roy 2019**)的模式受万有引力定律的启发,可以视为力的大小和角度的组合。
3.2.2 基于局部二进制模式统计的描述符
与类似 SIFT 的方法不同,在过去的几十年中已经提出了几种受局部二元模式 (LBP) (Ojala et al. 2002) 启发的基于强度统计的方法。 LBP 具有有利于其在兴趣区域描述中使用的特性,例如对光照变化的容忍度和计算简单性。 缺点是操作员会产生相当长的直方图,并且在平面图像区域中的鲁棒性微不足道。 中心对称 LBP (CS-LBP) (Heikkilä et al. 2009)(使用 SVM 进行分类器训练)是 LBP 的修改版本,结合了 SIFT 和 LBP 的优势来解决平面区域问题。 具体来说,CS-LBP 使用类似 SIFT 的网格,并用基于 LBP 的特征替换梯度信息。 为了解决噪声,中心对称局部三元模式 (CS-LTP) (Gupta et al. 2010) 建议使用区块中相对阶数的直方图和 LBP 码的直方图,例如相对强度直方图。 这两种基于 CS 的方法被设计为比以前考虑的描述符对高斯噪声更鲁棒。 RLBP (Chen et al. 2013) 通过改变编码比特来提高 LBP 的鲁棒性; 已经为纹理分类开发了 LBP 算子的完整建模和相关的完整 LBP 方案(Guo 等人,2010)。 类似 LBP 的方法广泛用于纹理表示和人脸识别社区,更多细节可以在评论文献中找到 (Huang et al. 2011)。
3.2.3 基于局部强度比较的描述符
描述符的另一种形式是基于局部强度的比较,也称为二进制描述符,其核心挑战是比较的选择规则。由于其独特性有限,这些方法大多局限于短基线匹配。Calonder等人(2010年)提出了一个BRIEF的描述符,该描述符是通过拼接图像中多个随机点对的二元强度测试结果来构建的。Rublee et al.(2011)提出了旋转BRIEF组合定向FAST角点,并在其ORB算法中使用机器学习策略选择鲁棒二进制测试,以缓解旋转和尺度变化的限制。Leutenegger等人(2011年)开发了BRISK方法,该方法使用半径增大的同心圆采样策略。受视网膜结构的启发,Alahi et al.(2012)通过比较视网膜采样模式上的图像强度,提出了FREAK描述符,以实现快速计算和低内存成本匹配,同时保持对缩放、旋转和噪声的鲁棒性。手工编制的二进制描述符和经典机器学习技术也得到了广泛的研究,这些应在基于学习的小节中介绍。
3.2.4 基于局部强度顺序统计的描述符
到目前为止,已经设计了许多使用像素值顺序而非原始强度的方法,实现了更具前景的性能(Tang et al.2009;Toews and Wells 2009)。按强度顺序合并对旋转和单调强度变化保持不变,并将顺序信息编码为描述符;强度顺序池方案可以使描述符具有旋转不变性,而无需估计SIFT等参考方向,这对于大多数现有方法来说是一个主要误差源。为了解决这个问题,Tang等人提出了有序空间强度分布(Tang等人2009)方法,该方法使用有序空间强度直方图对捕获的纹理信息和结构信息进行归一化;该方法对任何单调递增的亮度变化都是不变的。
Fan等人(2011)在多个支持区域中基于它们的梯度和强度顺序汇集局部特征,并提出了基于多支持区域顺序的梯度直方图和多支持区域旋转和强度单调不变描述符方法。 LIOP (Wang et al. 2011, 2015) 中使用了类似的策略,对每个像素的局部序数信息进行编码。在这项工作中,整体序数信息用于将局部补丁划分为子区域,这些子区域用于累积 LIOP。 LIOP 进一步改进为 OIOP/MIOP(Wang et al. 2015),然后可以对噪声和失真鲁棒性的整体序数信息进行编码。他们还提出了一种基于学习的量化来提高其独特性。
3.3 基于学习的特征描述符
如上所述,手工制作的描述符需要专业知识来设计,并且可能会忽略隐藏在数据中的有用模式。 这一要求促进了对基于学习的描述符的研究,最近由于其数据驱动的特性和有希望的性能而变得非常流行。 下面,我们将讨论在深度学习时代之前引入的一组经典的基于学习的描述符。
3.3.1 基于经典学习的描述符
基于学习的描述符可以追溯到PCASIFT(Ke et al.2004),其中使用主成分分析(PCA)通过降低由局部图像梯度构成的向量的维数来形成鲁棒且紧凑的描述符。Cai等人(2010年)研究了线性判别投影的使用,以减少维数并提高局部描述符的可分辨性。Brown等人(2010年)介绍了一个学习框架,其中包含一组构建块,用于使用Powell最小化和线性判别分析(LDA)技术来构建描述符,以找到最佳参数。Simonyan等人(2014年)在Brown等人的工作基础上,提出了一种新的公式,将描述符学习中的空间池和降维表示为凸优化问题(Brown等人,2010年)。与此同时,Trzcinski et al.(2012、2014)应用boosting技巧从多个基于梯度的弱学习者那里学习增强的复杂非线性局部视觉特征表示。
除了上述浮点值描述符之外,二进制描述符由于其有益的特性 (例如低存储要求和高匹配速度),在经典描述符学习中也引起了极大的兴趣。获得二进制描述符的一种自然方法是从提供的浮点值描述符中学习它。该任务通常是通过散列(哈希?)方法来实现的,因此建议应学习高维数据的紧凑表示,同时保持它们在新空间中的相似性。位置敏感散列 (LSH) (Gionis等人1999) 可以说是一种流行的无监督散列方法。此方法通过随机投影生成嵌入,并已用于许多大规模搜索任务。LSH的一些变体包括核化LSH (Kulis和Grauman 2009) 、谱散列 (Weiss等人2009) 、语义散列 (Salakhutdinov和Hinton 2009) 和基于p-stale分布的LSH (Datar等人2004)。这些变体不受设计监督。
监督哈希方法也已被广泛研究,其中提出了不同的机器学习策略来学习针对特定任务量身定制的特征空间。在这种情况下,已经提出了过多的方法 (Kulis和Darrell 2009; Wang等人2010; Strecha等人2012; Liu等人2012a; Norouzi和Blei 2011; Gong等人2013; Shakhnarovich 2005),其中图像匹配被认为是一个重要的实验验证任务。例如,在Strecha等人 (2012) 中使用LDA技术来辅助散列。在Liu等人 (2012a) 和wang等人 (2010) 中提出了半监督顺序学习算法来寻找判别投影。最小损失散列 (Norouzi和Blei 2011) 提供了一种新的公式,可以在具有潜在变量的结构svm的基础上学习二进制散列函数。Gong等人 (2012) 提出搜索零中心数据的旋转以最小化将描述符映射到零中心二进制超立方体的顶点的量化误差。
Trzcinski 和 Lepetit (2012) 以及 Trzcinski 等人(2017)报告说,开发二进制描述符的一种直接方法是直接从图像块中学习表示。 在 Trzcinski 和 Lepetit (2012) 中,他们提出通过使用几个简单滤波器的线性组合将图像块投影到判别子空间,然后对它们的坐标进行阈值化以创建紧凑的二进制描述符。 图像匹配过程中描述符(例如 SIFT)的成功表明非线性滤波器(例如梯度响应)比线性滤波器更适合。 Trzcinski 等人(2017)提出为每个描述符位学习与 AdaBoost 强分类器相同形式的哈希函数,即非线性弱学习器的线性组合的符号。 这项工作比基于简单阈值线性投影的 Trzcinski 和 Lepetit (2012) 更通用、更强大。 Trzcinski 等人(2017)建议生成每个补丁独立适应的二进制描述符。 这个目标是通过描述符的类间和类内在线优化来实现的。
3.3.2 基于深度学习的描述符
使用深度技术的描述符通常被表述为一个监督学习问题。目标是学习一种表示,使两个匹配的特征尽可能接近,而不匹配的特征在测量空间中相距很远(Schonberger et al. 2017)。描述符学习通常使用以检测到的关键点为中心的裁剪局部块进行;因此,它也被称为块匹配。一般来说,现有的方法包括两种形式,即度量学习(Weinberger and Saul 2009; Zagoruyko and Komodakis 2015; Han et al. 2015; Kedem et al. 2012; Wang et al. 2017; Weinberger and Saul 2009)和描述符学习(Simo-Serra 等人 2015;Balntas 等人 2016a、2017;Zhang 等人 2017c;Mishchuk 等人 2017;Wei 等人 2018;Heetal.2018;Tian 等人 2019;Luo 等人。 2019),根据基于深度学习的描述符的输出。这两种形式往往是联合训练的。具体来说,度量学习方法通常会学习一个判别度量,用于以原始块或生成的描述符作为输入进行相似性测量。相比之下,描述符学习倾向于从原始图像或块生成描述符表示。这样的过程需要一种测量方法,例如 L2 距离或训练的度量网络,用于相似性评估。与单一度量学习相比,使用 CNN 生成描述向量更加灵活,并且可以通过在大量候选块可用于对应搜索时避免重复计算来节省时间。深度学习由于其强大的信息提取和表示能力,在特征描述方面取得了令人满意的表现。
具有深度学习技术的描述符可以被视为基于经典学习的描述符的扩展(Schonberger et al. 2017)。例如,乔普拉等人 (2005)的Siamese结构 和常用的损失函数,如hinge、Siamese、三元组、排序和对比损失,在最近的深度方法中被借用和修改。具体来说,Zagoruyko 和 Komodakis (2015) 提出了他们的 DeepCompare,并展示了直接从具有通用块相似度函数的原始图像像素中学习的机制。在这种情况下,各种 Siamese-type CNN 模型被用于对相似度函数进行编码。然后对这些模型进行训练以识别正负图像补丁对。尝试的不同网络结构包括具有共享或非共享权重和中央环绕形式的 Siamese。 MatchNet (Han et al. 2015) 被提出来同时学习描述符和度量。这种技术是通过级联类似连体的描述网络和完全卷积决策网络来实现的。任务在交叉熵损失下转化为分类问题。 DeepDesc (Simo-Serra et al. 2015) 使用 CNN 来学习判别块表示以及 L2 距离测量。特别是,它通过最小化成对铰链损失来训练具有正负块对的连体网络,并且提出的硬负挖掘策略缓解了正负样本的不平衡。因此,描述性能显着增强。Wang等人(2014)提出了一种新颖的深度排名模型来学习细粒度的图像相似度。该模型采用基于三元组的铰链损失和排序函数来表征细粒度的图像相似性关系。多尺度神经网络架构用于捕获全局视觉属性和图像语义。
库马尔等人(2016)首先使用全局损失来扩大正负补丁对之间的距离裕度。它是通过三元组和连体网络实现的,这些网络结合了三元组和全局损失进行训练。 TFeat (Balntas et al. 2016b) 提出利用三组训练样本进行基于 CNN 的补丁描述和匹配。它是用浅层卷积网络和快速硬负挖掘策略实现的。在 L2Net(Tian 等人 2017)中,Tian 等人应用渐进式采样策略来优化欧几里得空间中基于相对距离的损失函数。该工作的作者考虑了中间特征图和描述符的紧凑性以实现更好的性能。 HardNet (Mishchuk et al. 2017) 通过使用简单的铰链三元组损失和“批内最难”挖掘实现了比 L2Net 更好的改进。 PN-Net (Balntas et al. 2016a) 使用在距离度量学习和在线提升领域中引入的想法,通过同时使用正约束和负约束进行训练。与铰链损失或 SoftMax 比率相比,提出的 SoftPN 损失函数具有更快的收敛速度和更低的误差(Wang et al. 2014; Zagoruyko and Komodakis 2015)。张等人(2017c)通过使用他们提出的全局正交正则化和三元组损失来训练他们的网络,以鼓励描述符充分“展开”。进行它是为了充分利用描述符空间。
基于平均精度注意力的描述符学习(He et al. 2018)引入了一种通用学习来对公式进行排序。 这种方法被定义为一个约束,其中真正的匹配应该排在所有错误的路径匹配之上,并基于二进制和实值局部特征描述符进行优化。 BinGAN (Zieba et al. 2018) 提出了一种用于生成对抗网络 (Goodfellow et al. 2014) 的正则化方法来学习图像块的有区别但紧凑的二进制表示。 相比之下,Erin Liong 等人(2015)提出了其他专注于二进制描述符学习的方法。 林等人(2016a)和段等人(2017)除了损失函数、网络结构、正则化和难负挖掘,Wei 等人(2018)通过使用核化子空间池学习了一个有区别的深度描述符。 田等人(2019)在他们的 SOSNet 中使用了二阶相似度。 在 ContextDesc 中,一种更新的方法,Luo 等人(2019)将局部块相似性约束与兴趣点的空间几何约束相结合来训练他们的网络,这大大提高了匹配性能。
正如在基于 CNN 的检测器中提到的,越来越多的端到端学习方法将特征描述与检测器一起集成到完整的匹配通道中。 这些方法与为上述描述单独设计的方法相似。 主要区别可能在于训练的方式和整个网络结构的设计。 核心挑战是使整个过程可区分和可训练。 例如,LIFT (Yi et al. 2016) 尝试通过端到端 CNN 网络同时实现关键点检测、方向估计和特征描述。
SuperPoint(DeTone et al. 2018) 提出了一个自监督框架,用于训练兴趣点检测器和多视图几何问题的描述符。 全卷积模型对全尺寸图像进行操作,并联合计算像素级兴趣点位置和相关描述符,这与基于路径的网络形成对比。 LF-Net (Ono et al. 2018) 设计了一个双分支设置并迭代地创建虚拟目标响应,以允许从头开始训练而无需手工制作的先验。 该技术实现了特征图生成、使用 top K 选择和 NMS 进行尺度不变关键点检测、方向估计和描述符提取。 在 LF-Net 中,目标函数包括图像级别损失(满足图像对、深度图和基本矩阵之间的附加约束)、块损失(学习有利于匹配的关键点并涉及方向和尺度分量几何一致性) ,以及用于描述符学习的三元组损失。
随后,RF-Net (Shen et al. 2019) 创建了一个从 LF-Net 结构修改而来的端到端可训练匹配框架。首先,构建的感受性特征图导致有效的关键点检测。其次,一个通用的损失函数术语,即邻居掩码,有助于训练补丁选择以增强描述符训练的稳定性。 D2-Net (Dusmanu et al. 2019) 使用单个 CNN 发挥双重作用:同时实现密集特征描述符和特征检测器。在 Bhowmik 等人(2020)使用强化学习的原理在高级视觉任务下优化关键点选择和描述符匹配。此外,李等人(2020)引入了双分辨率对应网络,通过提取不同分辨率的特征图以粗到细的方式获得像素对应。
除了同一目标或场景的特征匹配外,还使用CNN研究了从相似目标/场景捕获的图像的语义匹配,并实现了明显的提升。由于需要理解语义相似性,语义匹配问题可能会对手工制作的方法提出挑战。为此,UCN(Choy et al.2016)使用深度度量学习直接学习保留几何或语义相似性的特征空间。使用这种方法还有助于为几何或语义对应任务生成密集而准确的对应。具体而言,UCN实现了一种具有对应对比损耗的全卷积结构,用于快速训练和测试,并提出了一种用于局部面片归一化的卷积空间变换器。NCN(Rocco et al.2018)开发了一种端到端可训练的CNN架构,该架构基于通过使用半局部约束消除特征匹配歧义的经典思想,以找到一对图像之间可靠的密集对应关系。该框架通过分析全局几何模型的相邻一致性模式来识别空间一致性匹配集。该模型可以通过弱监督进行有效训练,而无需手动标注点对应关系。这种类型的框架可应用于类别级和实例级匹配任务,其他类似方法见Han et al.(2017)、Plötz and Roth(2018)、Chen et al.(2018)、Laskar and Kannala(2018)、Kim et al.(2018、2020)、Ufer and Ommer(2017)和Wang et al.(2018)。
3.4 三维特征描述符
对三维特征描述符进行了广泛的研究。如前所述,由于深度学习范式在许多不同领域取得的革命性成功,许多研究者已经将注意力转向了深度学习范式。这一事实促使我们将现代描述符分为两类,即手工制作的描述符和基于学习的描述符。Guo等人(2016)对传统手工制作的三维特征描述符进行了全面的性能评价,但忽略了基于学习的方法。在下一节中,我们将简要介绍最先进的手工制作的描述符和基于学习的描述符。
3.4.1 手工制作的3-D描述符
郭等人(2016)将手工制作的描述符分为空间分布直方图和基于几何属性直方图的描述符,前者通过直方图表示局部特征,直方图对支持区域中点的空间分布进行编码。 通常,为每个关键点构建局部参考框架/轴。 因此,3-D 支持区域被划分为 bin 以形成直方图。 通过累积空间分布测量值来计算每个 bin 的值。 一些代表性的工作包括旋转图像(Johnson 和 Hebert 1999)、3-D 形状上下文(Frome 等人 2004)、独特形状上下文(Tombari 等人 2010a)、旋转投影统计(Guo 等人 2013)和三自旋图像(Guo et al. 2015)。 空间分布直方图描述符通过从支持区域中的几何属性(例如法线、曲率)的统计数据生成直方图来表示局部特征。 这些直方图包括局部表面贴片 (Chen and Bhanu 2007)、THRIFT (Flint et al. 2007)、点特征直方图 (Rusu et al. 2008)、快速点特征直方图 (Rusu et al. 2009) 和方向直方图的签名 (Tombari 等人,2010b)。 除了基于几何属性和空间分布直方图的描述符之外,Zaharescu 等人 (2009) 引入了类似于 SIFT (Lowe 2004) 的 MeshHoG 描述符,并使用梯度信息生成直方图。
光谱描述符,例如全局点特征 (Rustamov 2007)、HKS (Sun et al. 2009) 和波核特征 (WKS) (Aubry et al. 2011),也是该领域的一个重要类别。描述符是从与形状相关的拉普拉斯-贝尔特拉米算子的谱分解中获得的。 Global Point Signature (Rustamov 2007) 利用形状上的 Laplace–Beltrami 算子的特征值和特征函数来表示点的局部特征。 HKS (Sun et al. 2009) 和 WKS (Aubry et al. 2011) 分别基于热扩散过程和量子力学粒子在形状上的时间演化。
3.4.2 基于学习的 3D 描述符
通过使用不同的学习方案,还致力于推广光谱描述符。Litman和Bronstein(2014)将光谱描述符概括为一个泛型家族,并建议从示例中学习,以获得特定任务的优化描述符。学习方案类似于信号处理中维纳滤波器的精神。Rodoláet al.(2014)提出了一种学习方法,使the wave核描述符能够使用随机森林分类器从示例集中识别更广泛的变形类别。Windhueser等人(2014年)提出了一种度量学习方法,以改进光谱描述符的表示。现代深度学习技术也得到了成功应用。Masci et al.(2015)提出了第一次尝试,并将CNN范式推广到形状对应的非欧几里德流形。随后,Boscaini等人提出通过光谱卷积网络(Boscaini等人2015)和各向异性CNN(Boscaini等人2016)学习描述符。Monti et al.(2017)提出了一个统一的框架,用于将CNN architectures推广到非欧几里德域(图和流形)。Xie et al.(2016)构建了一个深度度量网络,以形成用于形状表征的二元光谱形状描述符。输入基于Laplace-Beltrami算子的特征值分解。
在空间领域,各种深度学习方法的差异往往在于消费数据的表示。魏等人(2016)在形状的深度图表示上训练了一个深度 CNN,以找到对应关系。曾等人(2017)提出使用 3D 深度 CNN 来学习局部体积块描述符。该描述符使用局部区域的截断距离函数值的体素网格。埃尔巴兹等人(2017)提出了一种深度神经网络自动编码器来解决 3D 匹配问题。作者使用随机球面覆盖集算法来检测特征点并将每个局部区域投影到深度图中,作为神经网络的输入以生成描述符。库里等人(2017)通过使用以每个点为中心的球形直方图对输入进行参数化,并利用全连接网络生成低维描述符。 Georgakis 等人(2018)最近采用了处理深度图的连体架构网络。周等人(2018)提出从多个视图的图像中学习来描述 3D 关键点。王等人(2018b)将关键点的多尺度局部邻域参数化为常规二维网格,作为三重架构CNN。Deng 等人(2018)的输入首先提出了一个基于PointNet的无序网络(Qi et al. 2017a)。该网络可以使用原始点云来利用 3D 匹配任务中的完全稀疏性。
3.5 总结
如前所述,指定图像面片描述符以在检测到的特征点之间建立准确有效的对应关系。其目的是将原始图像信息转换为一种有区别的、稳定的表示,使两个匹配的特征尽可能接近,而不匹配的特征相距很远。为此,描述符应易于计算,且计算量和存储请求较低。这些描述符还应保持其对严重变形和成像条件的区分性和不变特征。在下一节中,我们将对手工编制的描述符进行全面分析,并介绍基于学习的方法可以部分解决这些挑战并实现良好性能的机制。
按照传统局部描述符的构建过程,第一步是提取低层信息,可简单分为图像梯度和强度。具体来说,梯度信息可以被视为比原始强度更高阶的图像线索。池化策略通常需要与直方图或统计方式一起形成浮点描述符。因此,这种策略对几何变换更加不变(也许池化和统计策略使其更独立于像素位置和几何变化)。然而,它需要在梯度计算和统计以及浮点型数据的距离测量方面进行额外的计算。基于LBP的方法通常具有较高的判别能力和对光照变化和图像对比度的良好鲁棒性,常用于纹理表示和人脸识别。
与基于梯度和/或统计的方法相比,简单的图像强度比较策略会牺牲很大的辨别力和鲁棒性。经典的机器学习技术通常旨在识别大量有用的比特。这些类型的方法通常需要参考方向估计来实现旋转不变,这似乎是大多数现有方法的主要误差源。然而,强度顺序的使用在没有任何几何估计的情况下对旋转和强度变化本质上是不变的。由于结合使用强度顺序和统计策略,它可以实现有希望的性能。
人工经验和先验知识。 它们自动优化并获得最优参数并直接构建想要的描述符。 传统的学习方法旨在使生成的描述符在效率、低存储和区分方面具有优势。 然而,使用的图像线索,如强度和梯度,仍然是低阶的,并且它们高度依赖于手工方法中的框架。 然而,目标函数、训练技能和应用的数据集
一些技能可以帮助提高深度描述符的可辨别性和鲁棒性。一方面,中央环绕和三元组(甚至更多)结构可以提供大量重要的信息来学习。硬负样本挖掘策略会使结构集中在硬样本上(也可能导致过拟合),从而可以获得更好的匹配性能。还应根据描述任务的基本和内在属性设计更可靠的损失函数。例如,最近设计的三元组、排序、对比和全局损失,优于早期的简单铰链和交叉熵损失。另一方面,为了更好地匹配和泛化能力,还需要有效和全面的地面实况数据集。通过端到端的方式将描述符与检测器一起训练到完整的匹配通道中,目前也引起了极大的关注。这可以联合优化检测器和描述符,从而获得令人鼓舞的性能,并且其中的无监督训练可以在不需要任何标记的地面实况补丁数据的情况下执行。通过使用深度技术,当前的描述符可以在外观差异的图像对(例如照明和昼夜)之间实现显着的匹配性能。然而,这些描述符仍然存在严重的几何变形,例如大旋转或低重叠图像对。对新型数据泛化能力低也是另一个局限。
描述符的总体性能还取决于适当的检测器。检测器和描述符的不同组合可能导致不同的匹配性能。因此,应根据特定任务和图像数据类型选择描述符。使用深度学习的高级描述符显示出巨大的潜力。
4. 匹配方法
匹配任务旨在在使用或不使用特征检测和/或描述的情况下在两幅图像之间建立正确的图像像素或点对应关系。这项任务对整个图像匹配管道发挥了重要作用。针对具体的应用和场景引入了不同的匹配任务定义,可能会显示出各自的优势。
4.1 匹配方法的概述
在过去的几十年中,在图像匹配社区中,现有方法可以大致分为两类,即基于区域和基于特征的方法 (Zitova和Flusser 2003; Litjens等人2017)。基于区域的方法通常是指密度匹配,也称为图像配准,它通常不会检测特征。在基于特征的方法中,当从图像对中提取特征点及其局部描述符时,图像匹配任务可以转换为以间接和直接的方式匹配它们,这对应于局部图像描述符的使用和不使用。
直接特征匹配旨在直接利用空间几何关系和优化方法建立两个给定特征集的对应关系,大致可分为图匹配和点集配准。相比之下,间接特征匹配方法通常将匹配任务转换为两阶段问题。这样的任务通常从通过描述符的相似性与从测量空间判断的距离建立初步对应关系开始。此后,通过使用额外的局部和/或全局几何约束从假定的匹配集中删除错误匹配。来自稀疏特征对应的密集匹配通常需要变换模型估计的后处理,然后是图像重采样和插值(翘曲)。
我们将把基于学习的方法与基于区域和特征的方法分开,并在一个新的小节中介绍它们。从输入数据来看,图像学习和点数据学习是基于学习的匹配的两种主要形式。与传统方法相比,这些方法在某些场景下可以实现更好的性能。本节还简要介绍了 3-D 案例中的匹配任务。
4.2 基于区域的匹配
基于区域的方法旨在通过直接使用整个图像的像素强度进行图像配准并建立密集像素对应。几何变换估计和公共区域对齐需要一种相似性度量和优化方法,通过最小化目标和扭曲运动图像之间的总体差异来实现。因此,经常使用一些手动相似性度量,包括类相关、域转换和互信息(MI)方法。执行最终注册任务还需要优化方法和转换模型(Zitova和Flusser 2003)。
在图像配准社区中,被认为是基于区域的方法中的经典代表的类相关方法通过最大化两个滑动窗口的相似性来对应两个图像(Zitova and Flusser 2003;Lietal.2015)。 例如,小波特征的最大相关性已经被开发用于自动配准(Le Moigne et al. 2002)。 然而,这种方法可能会受到严重的图像变形(只有在出现轻微的旋转和缩放时才能成功应用)、包含平滑区域而没有任何突出细节的窗口以及巨大的计算负担等问题。
域变换方法倾向于在将原始图像转换为另一个域的基础上对齐两个图像,例如基于傅里叶位移定理的相位相关(Reddy and Chatterji 1996; Liu et al. 2005; Chen et al. 1994; Takita et al. . 2003; Foroosh et al. 2002),以及基于 Walsh 变换的方法 (Lazaridis and Petrou 2006;Pan et al. 2008)。这种方法对相关的和频率相关的噪声和非均匀的时变照明干扰具有鲁棒性。然而,这些方法在具有显着不同光谱内容和小重叠区域的图像对的情况下存在一些局限性。
基于信息论,MI,例如使用MI和b样条 (Klein等人2007) 和条件MI (Loeckx等人2009) 的非刚性图像配准,是两个图像之间的统计相关性的测量,并且与整个图像一起工作 (Maes等人1997)。因此,MI特别适用于多模态的注册 (Chen等人,2003a,b; Johnson等人,2001)。最近,Cao等人 (2020) 提出了一种结构一致性增强变换,以增强多光谱和多模态图像配准问题中的结构相似性,从而避免光谱信息失真。但是,MI在确定整个搜索空间的全局最大值方面表现出困难,这不可避免地降低了其鲁棒性。此外,优化方法 (例如,连续优化,离散优化及其混合形式) 和转换模型 (例如,刚性,仿射,薄板样条 (TPS),弹性体和扩散模型) 被认为是足够成熟的。有关代表性文献和更多细节,请参考Zitova和Flusser (2003) 、Dawn等 (2010) 、Sotiras等 (2013) 和Ferrante和Paragios (2017)。
基于区域的方法对于医学或遥感图像配准是可接受的,许多基于特征的方法不再可行,因为由于不同的成像传感器,图像通常包含较少的纹理细节和较大的图像外观差异。但是,基于区域的方法可能会严重遭受严重的几何变换和局部变形的困扰。虽然深度学习已经证明了它的功效,但早期的学习通常被用作经典配准框架的直接扩展,而后来的学习则使用强化学习范式来迭代地估计转换,甚至直接估计变形场。端到端的方式。基于区域的匹配与学习策略的匹配将在基于学习的匹配部分进行审查。
4.3 图匹配方法 GM
给定从图像中提取的特征点,通过将每个特征点与一个节点相关联并指定边来构造图形。这一过程为研究图像数据的内在结构,特别是匹配问题提供了方便。根据这个定义,图匹配(gm)指的是在两个或多个图之间建立节点对应关系。由于其重要性和根本性的挑战,转基因一直是一个长期存在的研究领域,几十年来,仍然是非常感兴趣的研究人员。从问题设置的角度来看,gm 可以分为两类,即精确匹配和不精确匹配。精确匹配方法认为 gm 是图或子图同构问题的一种特殊情形。它的目的是找到两个二进制(子)图的双射,因此,所有的边都被严格保留,babai2018groups,cook2006mining,levi1973note)。事实上,这个要求对于像计算机视觉这样的真实任务来说太严格了。因此,研究人员经常采用不精确匹配的加权属性的节点和边。这种方法在实践中具有良好的灵活性和实用性。因此,我们主要集中讨论这次综述中的不精确匹配方法。
pass
4.4 点集配准方法 PSR
点集配准(PSR)旨在估计优化对齐两个点集的空间变换。在特征匹配中,PSR和GM采用了不同的公式。对于两个点集,GM方法通过最大化一元对应和成对对应的整体亲和力分数来确定配准。相比之下,PSR方法确定了潜在的全局变换。给定两个点集和,一般常规目标可以表示为
其中θ表示预定义变换的参数。正则化项g(P)避免了琐碎的解,例如P=0。与GM相比,该模型仅代表一般原理,但不一定涵盖PSR的所有算法。例如,可以使用概率解释或基于密度的目标,并且P的约束可能仅在优化期间部分施加,这些都与上述公式不同。
PSR对数据提出了更强的假设,即点集之间存在全局变换,这是区别于GM的关键特征。 尽管通用性受到限制,但由于全局变换模型所需的参数很少,这种假设导致计算复杂度较低。 为了增强泛化能力,我们开发了一个从刚性到非刚性的复杂转换模型。 还提出了各种方案来提高对劣化的鲁棒性,例如噪声、异常值和缺失点。
4.4.1 ICP及其变体
近几十年来,PSR 一直是计算机视觉领域的一个重要研究课题,迭代最近点 (ICP) 算法是一种流行的方法 (Besl and McKay 1992)。 ICP 在两个点集中最近点的对应硬分配和封闭形式的刚性变换估计之间迭代交替,直到收敛。 ICP算法由于其简单性和计算复杂度低而被广泛用作基线。 但是,需要良好的初始化,因为 ICP 容易陷入局部最优。 许多研究,如 EM-ICP (Granger and Pennec 2002)、LM-ICP (Fitzgibbon 2003) 和 TriICP (Chetverikov et al. 2005),已经在 PSR 的研究领域提出来改进 ICP。 读者可以参考最近的一项调查 (Pomerleau et al. 2013),详细讨论 ICP 的变体。 提出了鲁棒点匹配 (RPM) 算法 (Gold et al. 1998) 以克服 ICP 限制; 采用软分配和确定性退火策略,利用薄板样条[TPS-RPM (Chui and Rangarajan 2003)]将刚性变换模型推广到非刚性模型。
4.4.2 基于 EM 的方法
RPM 也是类 EM 的PSR 方法的代表,是该领域的一个重要类别。类EM方法将PSR表述为加权平方损失函数或高斯混合模型(GMM)的对数似然最大化的优化问题,并通过EM或类EM算法搜索局部最优。每个对应的后验概率在 E 步中计算,变换在 M 步中细化。索夫卡等人 (2007) 研究了配准过程中不确定性的建模,并在类似 EM 的框架中提出了协方差驱动的对应方法。 Myronenko 和 Song (2010) 提出了著名的相干点漂移 (CPD) 方法,该方法在 GMM 的基础上建立了概率框架;在这里,EM算法用于参数的最大似然估计。霍罗德等人 (2011) 开发了一种基于期望条件最大化的概率方法,该方法允许对混合模型组件使用各向异性协方差,并改进了各向同性协方差的情况。马等人(2016b)和张等人(2017a)在基于 GMM 的概率框架中利用了局部特征和全局特征的统一。劳文等人(2018 年)通过将场景的底层结构建模为潜在概率分布,提出了一种密度自适应 PSR 方法。
4.4.3 基于密度的方法
基于密度的方法将生成模型引入 PSR 问题,其中没有建立明确的点对应关系。每个点集由一个密度函数表示,例如 GMM。配准是通过最小化两个密度函数之间的统计差异度量来实现的。 Tsin 和 Kanade (2004) 最先提出了这种方法,并使用核密度函数对点集进行建模,并将差异度量定义为核相关。同时,Glaunes 等人 (2004) 使用松弛的狄拉克函数来表示点集。然后,他们确定了最小化两个分布的距离的最佳微分同胚变换。 Jian 和 Vemuri (2011) 通过使用基于 GMM 的表示和最小化密度之间的 L2 误差扩展了这种方法。作者还提供了基于密度的 PSR 的统一框架。许多流行的方法,包括 MyronenkoandSong (2010) 和 Tsin and Kanade (2004) 在理论上都可以被视为特例。 Campbell 和 Petersson (2015) 提出使用支持向量参数化 GMM 进行自适应数据表示。这种方法可以提高基于密度的方法对噪声、异常值和遮挡的鲁棒性。最近,廖等人(2020)利用模糊聚类来表示扫描的点集,然后通过最小化它们的模糊聚类中心之间的距离的模糊加权和来注册两个点集。
4.4.4 基于优化的方法
已经提出了一组基于优化的方法作为全局最优解,以缓解局部最优问题。这些方法通常在有限的转换空间中搜索以节省时序,例如旋转,平移和缩放。随机优化技术,包括遗传算法 (Silva等人2005; Robertson和Fisher 2002),粒子群优化 (Li等人2009),粒子滤波 (Sandhu等人2010) 和模拟退火方案 (Papazov和Burschka 2011; Blais和Levine 1995),被广泛使用,但是不能保证收敛。同时,Branch and bound (BnB) 是一种成熟的优化技术,可以在转换空间中有效地搜索全局最优解,并形成许多基于优化的方法的理论基础,包括Li和Hartley (2007),Parra Bustos等 (2014),campbell和Petersson (2016),Yang等人 (2016) 和Liu等人 (2018b)。除了这些方法之外,Maron等人 (2016) 引入了一种基于半定编程 (SDP) 松弛的方法,其中保证了等距形状匹配的全局解。Lian等人 (2017) 通过消除刚性变换变量将PSR公式化为凹形QAP,并且利用BnB来实现全局最优解。Yao等人 (2020) 提出了一种基于全局平滑鲁棒估计器的鲁棒非刚性PSR公式,用于数据拟合和正则化,该公式通过主化最小化算法进行优化,以减少求解简单最小二乘问题的每次迭代。Iglesias等人 (2020) 中的另一种方法是对缺少数据的PSR的全局最优性条件的研究。该方法应用拉格朗日对偶性来生成原始问题的候选解,从而使其能够以封闭形式获得相应的对偶变量。
4.4.5 其他方法
除了常用的刚性模型或基于TPS (Chui和Rangarajan 2003) 或高斯径向基函数 (Myronenko和Song 2010) 的非刚性变换模型之外,文献中还考虑了额外的复杂变形。这些模型包括简单的铰接扩展,例如Horaud等人 (2011) 和Gao和Tedrake (2019)。引入平滑局部仿射模型作为变换模型,并在非刚性ICP的ICP框架下开发 (Amberg等人2007),这也在Li等人 (2008) 中采用。但是,此模型应与稀疏的手动选择特征对应关系结合使用,因为它允许许多自由度。已经提出了一种不同的线性蒙皮模型,该模型不需要用户参与配准过程,并将其应用于另一项工作 (Chang和Zwicker 2009)。
另一类 PSR 方法将形状描述符引入注册过程。 生成局部形状描述符,例如自旋图像 (Johnson and Hebert 1999)、形状上下文 (Belongie et al. 2001)、积分体积 (Gelfand et al. 2005) 和点特征直方图 (Rusu et al. 2009)。 稀疏特征对应是由描述符的相似性约束建立的。 随后,可以使用随机抽样一致性 (RANSAC) (Fischler and Bolles 1981) 或 BnB 搜索 (Bazin et al. 2012) 来估计潜在的刚性变换。 马等人(2013b)在非刚性情况下提出了一种基于 L2E 估计器的鲁棒算法。
出现了一些基于不同观察的 PSR 新方案。 戈利亚尼克等人(2016)将点集建模为以重力为吸引力的粒子,并通过求解牛顿力学的微分方程来完成配准。 马等人(2015a)和王等人(2016)提出使用上下文感知高斯场来解决 PSR 问题。Vongkulbhisal 等人 (2017, 2018) 提出了判别优化方法。 这种方法从训练数据中学习搜索方向来指导优化,而不需要定义成本函数。 Danelljan 等人(2016) 和 Park 等人 (2017) 考虑了点集的颜色信息,而 Evangelidis 和 Horaud (2018) 和 Giraldo 等人(2017)解决了多个点集的联合配准问题。
4.5 带有错误匹配去除的描述符匹配
描述子匹配后错误匹配去除,也称为间接图像匹配,将匹配任务转化为一个两阶段的问题。这种方法通常首先通过局部图像描述子的相似性与从测量空间判断的距离建立初步对应关系。几种常见的策略,包括固定阈值 (FT)、最近邻 (NN),也称为蛮力匹配、相互 NN (MNN) 和 NN 距离比 (NNDR),可用于构建假定匹配集。此后,通过使用额外的局部和/或全局几何约束从假定的匹配集中删除错误匹配。我们简要地将错配去除方法分为基于重采样、基于非参数模型和松弛方法。在接下来的章节中,我们将详细介绍这些方法并提供全面的分析。
4.5.1 假定的匹配集构造
假设我们已经从考虑的两个图像和中检测并提取了要匹配的和个局部特征。描述匹配阶段通过计算具有个条目的成对距离矩阵,然后通过上述规则选择潜在的真实匹配来进行操作。
FT 策略考虑距离低于固定阈值的匹配。 然而,与一对一对应的性质相比,这种策略可能很敏感,并且可能会导致大量的一对多匹配。 这种情况导致特征匹配任务的性能不佳。 NN 策略可以有效地处理数据敏感性问题并召回更多潜在的真实匹配。 这种策略已经应用在各种描述符匹配方法中,但它无法避免一对多的情况。 在互 NN 描述符匹配中,I1 中的每个特征在 I2 中寻找其 NN(反之亦然),互 NN 的特征对成为推定匹配集中的候选匹配。 这种类型的策略可以获得高比例的正确匹配,但可能会牺牲许多其他真实对应。 NNDR认为第一个和第二个NN之间的距离差异是显着的。因此,使用具有预定义阈值的距离比将获得稳健且有希望的匹配性能,同时不会牺牲许多真实匹配。 然而,NNDR 依赖于这些描述符的稳定距离分布,即使该方法在类似 SIFT 的描述符匹配中被广泛使用并且表现良好。 事实上,NNDR 不再适用于其他类型的描述符,例如二进制或一些基于学习的描述符(Rublee et al. 2011; Ono et al. 2018)。
这些描述符匹配方法的最佳选择应依赖于描述符的性质和具体的应用程序。例如,MNN比其他高的更严格,但可能会牺牲许多其他潜在的真实匹配。相比之下,NN和NNDR在特征匹配任务中更为普遍,性能相对较好。米科拉奇克和Schmid(2005)提出了一个关于这些候选匹配选择策略的简单测试。虽然各种方法可用于假定的特征对应建设,只使用局部外观信息和简单的基于相似性的假定匹配选择策略,将不可避免地导致大量的错误匹配,特别是当图像经历严重的非刚性变形、极端的观点变化、低质量,和/或重复的内容。因此,在第二阶段迫切需要一种鲁棒、准确、有效的失配消除方法,以保持尽可能多的真实匹配,同时使用额外的几何约束保持其匹配最小。
4.5.2 基于重采样的方法
重采样技术(可以说)是一种流行的范式,由经典的 RANSAC 算法代表(Fischler 和 Bolles 1981)。 基本上,假设这两个图像通过某种参数几何关系耦合,例如投影变换或对极几何。 然后,RANSAC 算法遵循假设和验证策略:重复从数据中采样一个最小子集,例如 四个对应射影变换和七个基本对应,估计一个模型作为假设,并通过一致内点的数量来验证质量。 最后,与最优模型一致的对应被识别为内点。
人们提出了各种方法来提高RANSAC的性能。在MLESAC(Torr和Zisserman,1998,2000)中,模型质量通过最大似然过程进行验证,尽管在某些假设下,该过程可以改善结果,并且对预定义的阈值不太敏感。由于实现简单,修改验证阶段的想法不仅得到了利用,而且在许多后续研究中得到了进一步扩展。由于效率提高的诱人结果,许多研究也考虑了抽样策略的修改。本质上,不同的先验信息被合并,以增加选择所有内部样本子集的概率。具体而言,假设内联线在NAPSAC中具有空间一致性(Nasuto和Craddock,2002),或与GroupSAC中的某些分组存在(Ni等人,2009)。PROSAC(Chum和Matas,2005年)利用了先验预测的内隐概率,而EVSAC(Fragoso等人,2013年)利用了对应关系极值理论的置信度估计。另一项开创性的工作是局部优化RANSAC(LO-RANSAC)(Chum et al.2003),关键的观察结果是,采用最小的子集可以放大潜在的噪声,并产生与基本事实相去甚远的假设。这个问题是通过在得到最理想的模型时引入局部优化过程来解决的。在最初的论文中,局部优化被实现为一个迭代最小二乘拟合过程,在内部RANSAC中具有一个缩小的内部异常值阈值。这具有大于最小的采样,并且仅应用于当前模型的内联器。Lebeda等人(2012年)讨论了LO-RANSAC的计算成本问题,提出了一些实施改进建议。Barath和Matas(2018)使用图切割技术对局部优化步骤进行了扩充。RANSAC的许多改进策略已纳入USAC(Raguram等人,2012年)
最近,Barath 等人 (2019b)在他们的 MAGSAC 中应用了 σ 共识,通过在一系列噪声尺度上边缘化来消除用户定义阈值的需要。 此后,观察到附近的点更有可能来自相同的几何模型,Barath 等人(2019a)通过从逐渐增长的邻域中抽取样本来提取局部结构以进行全局采样和参数模型估计。 基于以上两种方法,他们引入了具有新评分功能的 MAGSAC++ (Barath et al. 2020)。 这种方法避免了需要离群值决策,其中一个新的边缘化过程被表述为 M 估计,通过迭代重新加权最小二乘过程和 Barath 等人(2019a)的渐进增长抽样策略来解决也适用于类似 RANSAC 的稳健估计。
尽管重采样方法在计算机视觉的广泛应用中有效,但它们仍表现出一些基本缺点。 例如,理论上所需的运行时间随着离群率的增加呈指数增长。 最小子集采样策略仅适用于参数模型,无法处理经历复杂变换的图像对,例如非刚性变换。 这种情况促使研究人员开发脱离重采样范式的新算法。
4.5.3 基于非参数模型的方法
已经提出了一组基于非参数模型的方法。非参数模型不是简单的参数模型,而是解决匹配中更一般的先验,例如运动连贯性,并且可以处理退化的场景。这些方法的区别在于不同的变形函数来模拟变换和处理严重异常值的不同方法。皮莱特等人(2008) 提出使用三角 2-Dmesh 来模拟变形,使用定制的稳健估计器来消除异常值的不利影响。 Gay-Bellile 等人也利用了稳健估计器的想法(2008 年),使用 Huber 估计器和 Ma 等人(2015)使用 L2E 估计器,尽管它们的变形建模不同。 Li and Hu (2010) 提出了一种完全不同的方法,其中使用支持向量回归技术来稳健地估计对应函数并拒绝不匹配。
开创性的工作向量场共识 (VFC) (Ma et al. 2013a, 2014) 引入了一个新的非刚性匹配框架。 变形函数被限制在与 Tikhonov 正则化相关的再现核希尔伯特空间内,以强制执行平滑约束。 估计是在贝叶斯模型中进行的,其中异常值被明确考虑为稳健性。 VFC 算法及其变体(Ma et al. 2015b, 2017a, 2019b)已被证明是有效的。
4.5.4 松弛方法
最近的趋势是开发宽松的匹配方法,其中几何约束不那么严格以适应甚至复杂的场景,例如由宽基线的图像对或经历独立运动的对象引起的运动不连续性。某些 GM 方法(Leordenu 和 Hebert 2005;Liu 和 Yan 2010)可用于此类要求,并使用包含对应关系的成对几何关系的二次模型来找到可能正确的模型。然而,结果往往是粗糙的。
Lipman等人 (2014) 考虑了分段仿射的变形; 然后,他们将特征匹配公式化为约束优化问题,该问题寻求与大多数对应关系一致的这种变形并施加有界失真。Lin等人 (2014,2017) 提出在特别设计的对应域中使用非线性回归技术估计的似然函数来识别真实匹配,其中施加运动相干性,同时也允许不连续性。此概念对应于实施局部运动相干约束。马等人 (2018a,2019d) 提出了一种用于配准的局部性保持方法,从而放宽配准的全局失真模型,以关注每个对应关系的局部性,以换取通用性和效率。已经证明,导出的标准能够快速准确地过滤错误匹配。类似的方法出现在Bian等人 (2017) 中,其中引入了基于局部支持匹配以拒绝异常值的简单标准。Jiang等人 (2020a) 将特征匹配作为具有异常值的空间聚类问题,以自适应地将假定的匹配与异常值/失配聚类一起聚类成几个运动一致的聚类。Lee等人 (2020) 的另一种方法将特征匹配问题公式化为一个马尔可夫随机场,它同时使用局部描述符距离和相对几何相似性来增强鲁棒性和准确性。
4.6 匹配的学习
除了检测器或描述符之外,基于学习的匹配方法通常用于替代信息提取和表示或模型回归中的传统方法。通过学习的匹配步骤可以大致分为基于图像的学习和基于点的学习。在传统方法的基础上,前者旨在应对三种典型任务,即图像配准 (Wu等人2015a) 、立体匹配 (Poursaeed等人2018) 和相机定位或变换估计 (Poursaeed等人2018; Erlik Nowruzi等人2017;尹和石2018)。这样的方法可以直接实现基于任务的学习,而无需预先尝试检测任何显著的图像结构 (例如兴趣点)。相比之下,基于点的学习更喜欢在提取的点集上进行; 这样的方法通常用于点数据处理,例如分类、分割 (Qi等人2017a,b) 和配准 (Simonovsky等人2016; Liao等人2017)。研究人员还将这些用于从假定的匹配集进行正确的匹配选择和几何变换模型估计 (Moo Yi等人2018;Maetal. 2019a; Zhao等人2019; Ranftl和Koltun 2018; Poursaeed等人2018)。
4.6.1 从图像中学习
基于图像的学习的匹配方法通常使用cnn进行图像级潜在信息提取和相似性测量以及几何关系估计。因此,基于块的学习 (第3.3节: 基于学习的特征描述符) 经常用作基于区域的图像配准和立体匹配的扩展。这是因为滑动窗口中的传统相似性测量可以很容易地用深度方式 (即深度描述符) 替换。然而,研究人员在空间变换网络 (STN) (Jaderberg等2015) 和光流估计 (FlowNet) (Dosovitskiy等2015) 中使用深度学习所取得的成功,引起了人们对使用深度学习技术直接估计几何变换或非参数变形场的研究浪潮,甚至实现端到端的可培训框架。
图像配准。对于基于区域的图像配准,早期的深度学习一般作为经典配准框架的直接扩展,后来使用强化学习范式迭代估计变换,甚至直接估计变形场或位移场用于配准任务。 最直观的方法是使用深度学习网络来估计目标图像对的相似性测量,以驱动迭代优化过程。 这样,经典的度量指标,如相关性和 MI 方法等,可以用更优越的深度指标代替。 例如,吴等人(2015a)通过使用**卷积堆叠自动编码器(CAE)**从观察到的图像块数据中发现紧凑和高度区分的特征来进行相似性度量学习,从而实现了可变形图像配准。 同样,为了获得更好的相似性度量,Simonovsky 等人(2016)使用了一个从几个对齐的图像对训练的深度网络。 此外,通过直接使用图像外观对变形模型进行块预测,设计了一种快速、可变形的图像配准方法,称为 Quicksilver (Yang et al. 2017b),其中使用深度编码器-解码器网络来预测大变形微分模型。 Revaud 等人受到深度卷积的启发(2016)引入了一种基于分层相关架构的密集匹配算法。 这种方法可以处理复杂的非刚性变形和重复的纹理区域。 阿拉尔等人(2020)引入了一种基于具有几何保留约束的图像到图像转换网络的无监督多模态图像配准技术。
与度量学习不同,经过训练的代理用于使用强化学习范式进行图像配准,通常用于估计刚性变换模型或可变形场。 廖等人(2017)首先将强化学习用于刚性图像配准,其中使用人工代理和贪心监督方法以及注意力驱动的分层策略来实现“策略学习”过程并找到最佳的运动动作序列以产生 图像对齐。 Krebs 等人(2017)还训练了一个人工代理,该代理通过从大量合成变形的图像对中进行训练来探索统计变形模型的参数空间应对可变形配准问题和提取真实数据的可靠真实变形场的困难。 Miao 等人(2018)没有使用单一代理提出了一种用于医学图像配准的多智能体强化学习范式,其中自动注意机制用于接收多个图像区域。 然而,强化学习通常用于预测回归过程的迭代更新,并且在迭代过程中仍然消耗大量计算。
为了减少运行时间并避免明确定义差异度量,一次性完成端到端配准已受到越来越多的关注。 索库蒂等(2017)首先设计了深度回归网络,直接从一对输入图像中学习位移矢量场。 de Vos 等人的另一种方法 (2017) 类似地训练了一个深度网络来回归并输出空间变换的参数,然后可以生成位移场以将运动图像扭曲到目标图像。 然而,仍然需要图像对之间的相似性度量来实现无监督优化。 最近,de Vos 等人引入了深度学习框架(2019)用于无监督仿射和可变形图像配准。 经过训练的网络可用于在一次拍摄中注册成对的看不见的图像。 将深度网络作为回归器的类似方法可以直接从图像对中学习参数变换模型,例如 Fundamental (Poursaeed et al. 2018)、Homography (DeTone et al. 2016) 和非刚性变形 (Rocco et al. 2017) 。
提出了许多其他基于端到端图像级学习的配准方法。Chen等人(2019)提出了端到端可训练的深层网络,以直接预测图像对齐的密集位移场。Wang和Zhang(2020)介绍了用于高效可变形医学图像配准的DeepFLASH,该技术在低维带限空间中实现,从而大大减少了计算和内存需求。为了同时增强变换模型的拓扑保持性和平滑性,Mok和Chung(2020)提出了一种有效的无监督对称图像配准方法,该方法在差分映射空间内最大化图像之间的相似性,并同时估计正变换和逆变换。在Truong et al.(2020)中,作者介绍了一种用于几何匹配、光流估计和语义对应的通用网络,通过研究全局和局部相关层的组合使用,该网络可以实现高精度和鲁棒性。更多详情请参见配准特定审查(Ferrante and Paragios 2017;Haskins et al.2020)。
立体匹配。在过去的几年中,与配准类似,立体匹配的大量研究都集中在通过使用深度卷积技术和改进视差图来准确计算匹配成本(Zbontar 和 LeCun 2015;Luo 等人 2016;Zbontar 和 LeCun 2016;Shaked和狼 2017)。除了 DeepCompare (Zagoruyko and Komodakis 2015) 和 MatchNet (Han et al. 2015) 等深度描述符之外,Zbontar 和 LeCun (2015) 还引入了深度 Siamese 网络来计算匹配成本,该网络被训练为预测图像块之间的相似性。他们进一步提出了一系列 CNN(Zbontar 和 LeCun 2016)用于成对匹配的二元分类,并将其应用于视差估计。类似于将匹配成本的计算转换为多标签分类问题,Luo 等人(2016)提出了一种用于快速立体匹配的高效连体网络。此外,Shaked 和 Wolf (2017) 通过计算与提议的恒定高速公路网络的匹配成本和使用反射置信度学习的视差估计来提高性能。
近年来,这种匹配任务的端到端深度方式引起了越来越多的关注。 例如,Mayer 等人(2016)在他们的 DispNet 中训练了一个端到端的 CNN 以获得精细的视差图,该图由 Pang 等人扩展(2017)具有称为级联残差学习(CRL)的两阶段CNN。 最近,Chang 和 Chen (2018) 引入了空间金字塔池化模块和 3-D 卷积策略。 这种方法可以利用全局上下文信息来增强立体匹配。 受 CycleGAN (Zhu et al. 2017) 的启发,为了处理领域差距,Liu et al. (2020)提出了一个端到端的训练框架,将所有合成立体图像转换为逼真的图像,同时保持极线约束。 该方法是通过域翻译和立体匹配之间的联合优化来实现的。 Yang 等人的另一种方法 (2020) 学习视差的小波系数而不是视差本身,它可以从低频子模块中学习全局上下文信息,并从其他子模块中学习细节。 此外,引导策略(Zhang et al. 2019a; Poggi et al. 2019)也用于立体匹配。
使用深度卷积技术的立体匹配因其在公共基准测试中的最佳性能而占据主导地位。 然而,在立体匹配社区中 CNN 的使用受到输入图像对的限制,输入图像对通常是从具有窄基线和极线校正的双目相机捕获的。 尽管如此,这些基于学习的立体匹配中的网络结构、基本思想和一些技巧或策略可能对一般的图像匹配任务有很强的参考意义。
4.6.2 从点学习
在特征提取、表示和相似性测量方面,从点中学习不如在图像中流行。基于点的学习,尤其是特征匹配,是近年来才引入的。这是因为由于稀疏点的无序结构和分散性质,在点数据上使用 CNN 比在原始图像上更困难。此外,使用深度卷积技术操作和提取多点之间的空间关系,例如相邻元素、相对位置、长度和角度信息,具有挑战性。然而,使用深度学习技术来解决基于点的任务已经受到越来越多的考虑。这些技术可以大致分为参数拟合(Brachmann et al. 2017; Ranftl and Koltun 2018)和点分类和/或分割(Qi et al. 2017a, b; MooYietal. 2018; Maetal. 2019a; Zhao et al. 2019 )。前者受经典 RANSAC 算法的启发,旨在通过 CNN 的数据驱动优化策略来估计转换模型,例如基本矩阵(Ranftl 和 Koltun 2018)和对极几何(Brachmann 和 Rother 2019)。然而,后者倾向于训练分类器从假定的匹配集中识别真正的匹配。通常,参数拟合和点分类联合训练以提高性能。
对于可训练的基本矩阵估计,Brachmann等人 (2017) 提出了一种可微分的RANSAC,称为DSAC,其基于端到端的强化学习。他们用概率选择代替确定性假设选择,以减少预期损失并优化可学习参数。随后,Ranftl和Koltun (2018) 提出了一种可训练的方法,用于从噪声中估计基本矩阵,该方法被视为一系列加权齐次最小二乘问题,其中鲁棒权重是用深度网络估计的。与DSAC类似,在Brachmann和Rother (2019) 和Kluger等人 (2020) 中也引入了使用学习技术来改进再采样策略。Brachmann和Rother (2019) 提出了NG-RANSAC,这是一种使用假设抽样的学习指导的鲁棒估计量。它使用内部计数本身作为训练目标,以促进NG-RANSAC的自我监督学习,并且可以合并不可微的任务损失函数和不可微的最小求解器。同时引入CONSAC (Kluger等人2020) 作为多参数模型拟合的鲁棒估计器。它使用神经网络顺序更新假设选择的条件采样概率。
基于学习的错误匹配去除方法是近年来发展起来的。MooYi等人 (2018) 首先尝试引入一种基于学习的技术,称为 “学习到正确的对应关系” (LFGC),该技术旨在从一组稀疏推定匹配以及在刚性几何变换约束下的图像本质来训练网络,并将测试对应关系标记为inlier或outlier,并同时输出相机运动。但是,LFGC可能会牺牲许多真实的对应关系来估计运动参数,从而无法处理一般的匹配问题,例如可变形和非刚性图像匹配。马等人 (2019a) 提出了一个通用框架,用于学习称为LMR的错误匹配去除的两类分类器,该框架使用一些图像和手工制作的几何表示进行训练。他们的方法显示了具有线性时间复杂度的有希望的匹配性能。最近,Zhang等人 (2019b) 专注于基于它们的有序感知网络 (OAN) 的几何恢复,并在姿态估计方面取得了有希望的性能。Sarlin等人 (2020) 提出了Super-
Glue,通过共同找到对应关系并拒绝不可匹配的点来匹配两组局部特征。该方法通过图神经网络 (Scarselli等人2009) 实现,用于可微传输问题优化。类似的图神经网络管道已经被一个新兴的研究分支采用,即深度图匹配 (Wang等人。2019; Yuotal.2020a; Fey等人。2020),其中交叉图卷积 (Wang等人。2019),提出了与信道无关的嵌入 (Yu等人2020a) 和基于样条的卷积 (Fey等人2020),并将其用于监督图对应学习。
尽管将cnn应用于点数据很困难,但最新技术已显示出使用深度回归器和分类器进行矩阵估计和点数据分类的巨大潜力,特别是对于具有挑战性的数据或场景。此外,自然语言处理中的多层感知方法和图卷积技术可以作为解决匹配任务中这些分散和非结构化点数据的重要参考。
4.7 3-D 案例中的匹配
与 2-D 匹配方法类似,3-D 匹配方法通常涉及两个步骤,即关键点检测和局部特征描述,然后可以通过计算描述符之间的相似性来建立稀疏对应集。虽然大多数方法使用局部特征描述符,其旨在对噪声和变形具有鲁棒性以建立 3-D 实例之间的对应关系,但各种经典和最近的作品属于另一类。鉴于对文献的详细回顾超出了本文的范围,我们建议读者参考最近在形状匹配领域进行的调查(Biasotti 等人 2016;Van Kaick 等人 2011)。
嵌入方法旨在通过利用一些自然假设(例如,近似等距)以较少的自由度参数化复杂的匹配问题以实现易处理性。 Elad 和 Kimmel (2003) 提出了一种传统方法,通过将形状嵌入中间欧几里得空间来匹配形状。在这种方法中,测地线距离近似为欧几里得距离,原始的非刚性配准问题被简化为中间空间的刚性配准。值得注意的是,另一项工作开发了同样使用嵌入空间的保形映射方法(Lipman 和 Funkhouser 2009;Kim 等人 2011;Zeng 等人 2010)。
一种更直接的方法是通过最小化结构失真来找到形状上的点(子集)之间的逐点匹配。 这个公式是由 Bronstein 等人开发的(2006 年),他介绍了一种高度非凸和不可微的目标以及用于优化的广义多维缩放技术。 一些研究人员还试图在考虑图中的二次分配公式(Rodola et al. 2012, 2013; Chen and Koltun 2015; Wang et al. 2011)的同时缓解过高的计算复杂度问题(Sahillioglu and Yemez 2011;Tevsetal.2011) 匹配。
基于功能图框架的方法系列首先由Ovsjanikov等人 (2012) 开发。这些方法不是在欧几里得空间中进行点对点匹配,而是使用两个子之间的功能映射来表示对应关系,可以用线性算子来表征。可以通过使用Laplace-Beltrami算子的本征基以紧凑形式编码功能图。地图上的大多数自然约束 (例如地标对应关系和运算符交换性) 在此公式中变得线性,从而导致有效的解决方案。这种方法在许多后续工作中被采用和扩展 (Aflalo等人2016; Kovnatsky等人2015; Pokrass等人2013; Rodola等人2017; Litany等人2017)。
用于配准的 3-D 案例中的点集学习也是一个热门话题。尤等人 (2020) 提出了用于刚性点云配准的 RPM-Net,其中它使初始化不敏感,并通过学习的融合特征提高收敛性能。戈西奇等人(2020)通过直接学习以全局一致的方式注册场景的所有视图,引入了端到端的多视图点云注册框架。派斯等人 (2020) 引入了一种用于 3D 点配准的学习架构,即 3DRegNet。该方法可以从一组假定的匹配中识别真正的点对应关系,并回归运动参数以将扫描对齐到一个公共参考帧中。蔡等人(2020)使用高维卷积网络检测高维空间中的线性子空间,然后将其应用于刚性运动和图像对应估计下的 3D 配准。
4.8 总结
给定一对相似对象/场景的图像,有/没有特征检测和/或描述,匹配任务已经扩展到几种不同的形式,例如图像配准、立体匹配、特征匹配、图匹配和点集配准。 这些不同的匹配定义一般都是针对特定的应用来介绍的,并呈现出各自的优势。
传统的图像配准和立体匹配通过逐块相似度测量结合优化策略来实现密集匹配,以搜索整体最优解。然而,它们是在高重叠区域(轻微几何变形)和双目相机的图像对上进行的,这些可能需要大量的计算负担和有限的手工测量指标。
由于网络设计和损失定义的进步以及丰富的训练样本,深度学习的引入提高了配准准确性和视差估计。 然而,我们还发现,对这些匹配任务使用深度学习通常是在发生轻微几何变形的图像对上执行的,例如医学图像配准和双目立体匹配。 将它们应用于更复杂的场景,例如宽基线图像立体或具有严重几何变形的图像配准,仍然是开放的。
基于特征匹配的可以有效地解决大型观点的局限性,宽基线,和严重的非刚性的图像匹配问题。其中提出的文献中,最受欢迎的策略是构建基于描述符的假定的匹配距离,紧随其后的是一个健壮的RANSAC之类的估计量。然而,大量的假定的匹配集不匹配可能会消极地影响性能在随后的视觉任务并为模型估计还需要相当长的时间。因此,不匹配需要去除方法和综合保护尽可能多的真正的比赛,同时保持最低水平不匹配使用额外的几何约束。具体来说,resampling-based方法,如RANSAC,可以同时估计的参数模型和删除离群值。然而,他们理论上所需的运行时异常率的增加呈指数级增长,他们无法处理的图像对进行更复杂的非刚性的转换。非参数模型方法可以处理非刚性的图像匹配问题,使用高维非参数模型,但它仍然是具有挑战性的定义目标函数,找到一个更复杂的解决方案空间的最优解。与全球约束不同重采样和non-parameter基于模型的方法,轻松去除不匹配的方法通常在本地进行连贯的假设潜在的内围层。因此,更简单但有效的规则是用来过滤异常值同时维持在一个极短的时间内围层。然而,这种类型的方法是有限的由于他们的参数敏感性;此外,他们容易保持明显的异常值,从而影响后续姿势估计和图像配准的精度。
此外,由于纹理较少的图像、形状、语义图像以及从特定设备直接捕获的原始点中的匹配请求,基于图像块的描述符可能无法使用。因此,对于执行这些情况的匹配任务,图匹配和点配准方法更适合。应用相邻点之间的图结构和整体对应矩阵进行优化并找到最优解。然而,这些纯基于点的方法受到计算负担和异常值敏感性的限制。因此,设计合适的问题表述和约束条件,提出更有效的优化方法,仍然是图像匹配界的开放性问题,需要进一步研究关注。
与基于图像的学习类似,越来越多的研究在基于特征的匹配社区中使用深度学习。最新的技术在矩阵估计(例如基本矩阵)和点数据分类(例如不匹配消除)方面显示出巨大的潜力,使用深度回归器和分类器,特别是在处理具有挑战性的数据或场景方面。然而,由于这些稀疏点的无序结构和分散性质,在点数据上进行卷积网络并不像在原始图像上那么容易。尽管如此,最近的研究表明使用图卷积策略和多层感知方法以及对此类点数据进行特定归一化的可行性。除了刚性变换参数估计之外,使用深度卷积技术匹配具有非刚性甚至严重变形的点数据可能是一个更具挑战性和意义的问题。
补充内容
1.宽基线图像
基线的本意是指立体视觉系统中两摄像机光心之间的距离。依据拍摄两幅图 像的视点位置关系可将对应点匹配问题分为宽基线(Wide Baseline)和窄基线匹配(Short Baseline)。宽基线一词用于匹配时,泛指两幅图像有明显不同的情况下的匹配。产生这种情况的原因有可能为摄像机之间的位置相差很大,也有可能由于摄像机旋转或焦距的变化等因素产生的。
宽基线匹配和窄基线匹配的分界不是很严格,但是在窄基线匹配中存在如下假设:摄像机焦距及其它内参数变化不大:摄像机位置不会相差很远,不会有大的转动,对应点的邻域是相似的。
宽基线匹配中则存在如下假设:对图像上的任意点,在另一图像上的对应点可以为任意位置;摄像机可以任意移动,且摄像机的焦距及其它内参数可以有较大的变化;一幅图像上的景物在另一幅图像上可能被遮挡;对应点的邻域有相似的地方,但由于摄像机位置的变化及光照的变化,单依靠邻域的相似不能得到正确的对应。
窄基线匹配中典型方法是利用邻域的互相关(Neighborhood Cross-Correlation)方法.但在宽基线的情况下,图像之间拍摄距离较远,成像条件存在较大差异,即使是空间同一特征,在图像中所表示出来的光学特性(灰度值,颜色值等)、几何特性(外形,大小等)及空间位置(图像中的位置,方向等)都有很大的不同,再加上噪声、遮挡等因素的存在,此时基于邻域互相关的匹配方法就失效了。在宽基线匹配中,仅仅使用特征本身的信息(比如边缘、角点的位置信息)是难以正确匹配的,研究学者将多个特征尤其是结构性特征予以组合,以形成稳定的特征向量(称为特征描述符)。这种对于图像的几何变形、光照变化等因素保持一定稳定性的特征向量称为不变量(Invariarlt)。不变量技术是宽基线匹配应用中的重要技术。
2.非结构化或非欧几里得数据
欧几里得数据:
特点:“排列整齐”,是一类具有很好的平移不变性的数据。
即不管图像中的目标被移动到图片的哪个位置,得到的结果(标签)应该相同的。
对于这类数据以其中一个像素为中心点,其邻居节点的数量相同。可以很好的定义一个全局共享的卷积核来提取图像中相同的结构。常见这类数据有图像、文本、语言。
图像:图像是一种2D的网格类型数据,通常用矩阵进行存储。
文本:文本是一种1D的网格类型数据,通常可以用向量进行存储。对于文本,我们通常做法是去停用词、以及高频词(DIFT),最后嵌入到一个一维的向量空间。
而且,因为这类型的数据排列整齐,不同样本之间可以容易的定义出 “距离” 这个概念出来。我们假设现在有两个图片样本,尽管其图片大小可能不一致,但是总是可以通过空间下采样的方式将其统一到同一个尺寸的,然后直接逐个像素点进行相减后取得平方和,求得两个样本之间的欧几里德距离是完全可以进行的。如下式所见:
因此,不妨把图片样本的不同像素点看成是高维欧几里德空间中的某个维度,因此一张mxn的图片可以看成是mxn维的欧几里德样本空间中的一个点,而不同样本之间的距离就体现在了样本点之间的距离了。
非欧几里得数据:
它是一类不具有平移不变性的数据。这类数据以其中的一个为节点,其邻居节点的数量可能不同。常见这类数据有知识图谱、社交网络、化学分子结构等等。
非欧几里德结构的样本总得来说有两大类型,分别是图(Graph)数据和流形数据( manifolds),如下图所示:


这两类数据有个特点就是,排列不整齐,比较的随意。
具体体现在:对于数据中的某个点,难以定义出其邻居节点出来,或者是不同节点的邻居节点的数量是不同的,这个其实是一个特别麻烦的问题,因为这样就意味着难以在这类型的数据上定义出和图像等数据上相同的卷积操作出来,而且因为每个样本的节点排列可能都不同,比如在生物医学中的分子筛选中,显然这个是一个Graph数据的应用,但是我们都明白,不同的分子结构的原子连接数量,方式可能都是不同的,因此难以定义出其欧几里德距离出来,这个是和我们的欧几里德结构数据明显不同的。因此这类型的数据不能看成是在欧几里德样本空间中的一个样本点了,而是要想办法将其嵌入(embed)到合适的欧几里德空间后再进行度量。而我们现在流行的 Graph Neural Network(GNN) 便可以进行这类型的操作。
另外,欧几里德结构数据所谓的“排列整齐”也可以视为是一种特殊的非欧几里德结构数据,比如说是一种特殊的Graph数据,如下图所示:
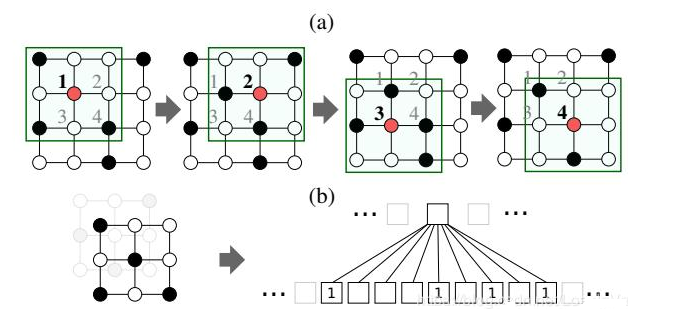
因此,用Graph Neural Network的方法同样可以应用在欧几里德结构数据上,事实上,只要是赋范空间中的数据,都可以建立数据节点与数据节点之间的某种关联,都可以尝试用非欧几里德结构数据的深度方法进行实验。
3. Siamese network
Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
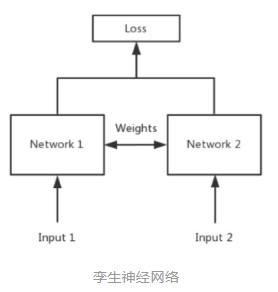
一般用于比较两个输入的相似度。